《Agent Harness Engineering: A Survey》阅读笔记
71 页 TMLR 综述论文,2026-05-14 投稿,9 位作者来自 CMU / Yale / Amazon 等。
本笔记为minimax m3阅读后直出,用户要求是总结 + 叙述性段落 + 论文原图。
论文:Junjie Li 等,《Agent Harness Engineering: A Survey》,2026。
一、这篇论文要回答什么问题
如果把大语言模型比作一颗越来越聪明的大脑,那么当它被要求”在真实世界里独立完成任务”时,包裹在它外面那整套基础设施——执行环境、工具协议、上下文管理、调度编排、可观测、评估、治理——才是决定它能不能干好活的真正关键。 这篇 71 页的学术综述论文把这个直觉系统化了,并把它命名为 “Agent Harness Engineering”(Agent 驾驭层工程)——一个被 OpenAI、Anthropic、LangChain 在生产中用了两年、但学术界从未正式研究的领域。
论文的三个核心论断构成了全文骨架:第一,harness 是独立的系统层,长跑任务上可靠性的瓶颈约束是 harness 而非模型;第二,论文提出 ETCLOVG 七层分类法(Execution / Tool / Context / Lifecycle-Orchestration / Observability / Verification / Governance),把已有六组件框架扩展为七层,首次把 Observability 提升为独立架构层,并新增跨 model/system/organization 三级的 Governance;第三,论文用 PRISMA-style 方法学从 GitHub、survey、curated list、公司博客四源汇聚 171 个开源项目编码到七层中,并系统提炼 OpenAI / Anthropic / LangChain 三大厂商的生产经验。
理解这篇论文最大的价值不在任何一个新算法或新协议,而在于它给整个”agent 工程”领域装上了一套共同词汇。在此之前,”harness engineering”只是 OpenAI 工程博客(2026-02-11 发表的 Harness engineering: leveraging Codex in an agent-first world)里的口号;在此之后,它有了 academic citation、可以教学、可以写进论文。
二、为什么是 2026 年:harness 概念从工程口号到学术学科
理解这篇论文要先理解一个时间点:2026 年初,”harness engineering” 突然从一家公司的内部术语变成了行业共识。
- 2024-11-25:Anthropic 发布 Model Context Protocol (MCP)**,给 agent 调用工具提供了”AI 时代的 USB 接口”标准。一年之内社区建了数千个 MCP server,到 **2025-12-10 Anthropic 把 MCP 捐赠给 Linux 基金会。
- 2025-04-09:Google 发布 Agent-to-Agent (A2A) 协议,给 agent 之间互相协作提供标准;2025-06-23 Linux 基金会成立 A2A 项目,得到 100+ 厂商支持。
- 2025-04:OpenAI 开源 Codex CLI(终端编码 agent,2026 年 1 月已 67K stars);同期 Mem0 发表 arXiv 论文 2504.19413 提出”可扩展长期记忆架构”。
- 2025-10:OpenAI DevDay 2025 宣布 Codex 正式 GA,并明确把”harness engineering”列入主题演讲。
- 2026-02-11:OpenAI 发布 Harness engineering: leveraging Codex in an agent-first world 工程博客,把 harness 概念从代码实践升级为公共术语。
- 2026-05-14:本文作为第一篇系统化综述投稿 TMLR。
从 2024-11 到 2026-05 仅仅 18 个月,”harness”从一个隐喻(来自马术,harness = 马具、驾驭具)变成一个学科。论文正好踩在学科确立的节点上。
三、论文的”图谱”——ETCLOVG 七层架构
论文把 agent harness 拆成 7 层架构。下面这张图是论文 Figure 2 的简化版,强烈建议先把图看完再读后面文字:
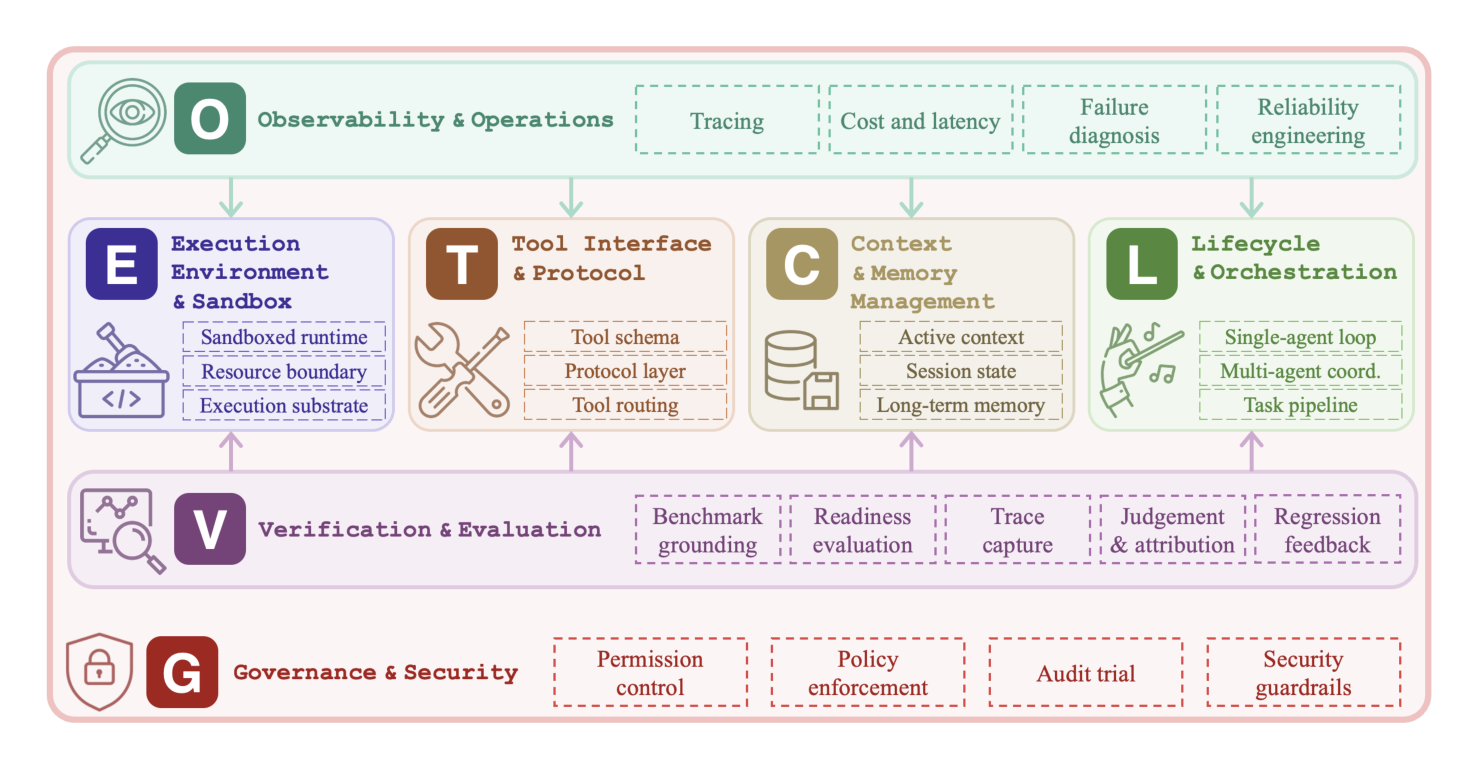
论文 Figure 2 把七层画成一个有上下结构关系的体系:E / T / C / L 四层是”结构性支柱”**(它们构成 agent 本身),O 层提供系统级监控(横跨其他层),V 层提供跨组件的评估与反馈(横跨其他层),G 层治理与安全**作为最底层执行准入规则。
如果把 Figure 2 展开成细节图(论文 Figure 4),七层各自又细分为若干子类别——
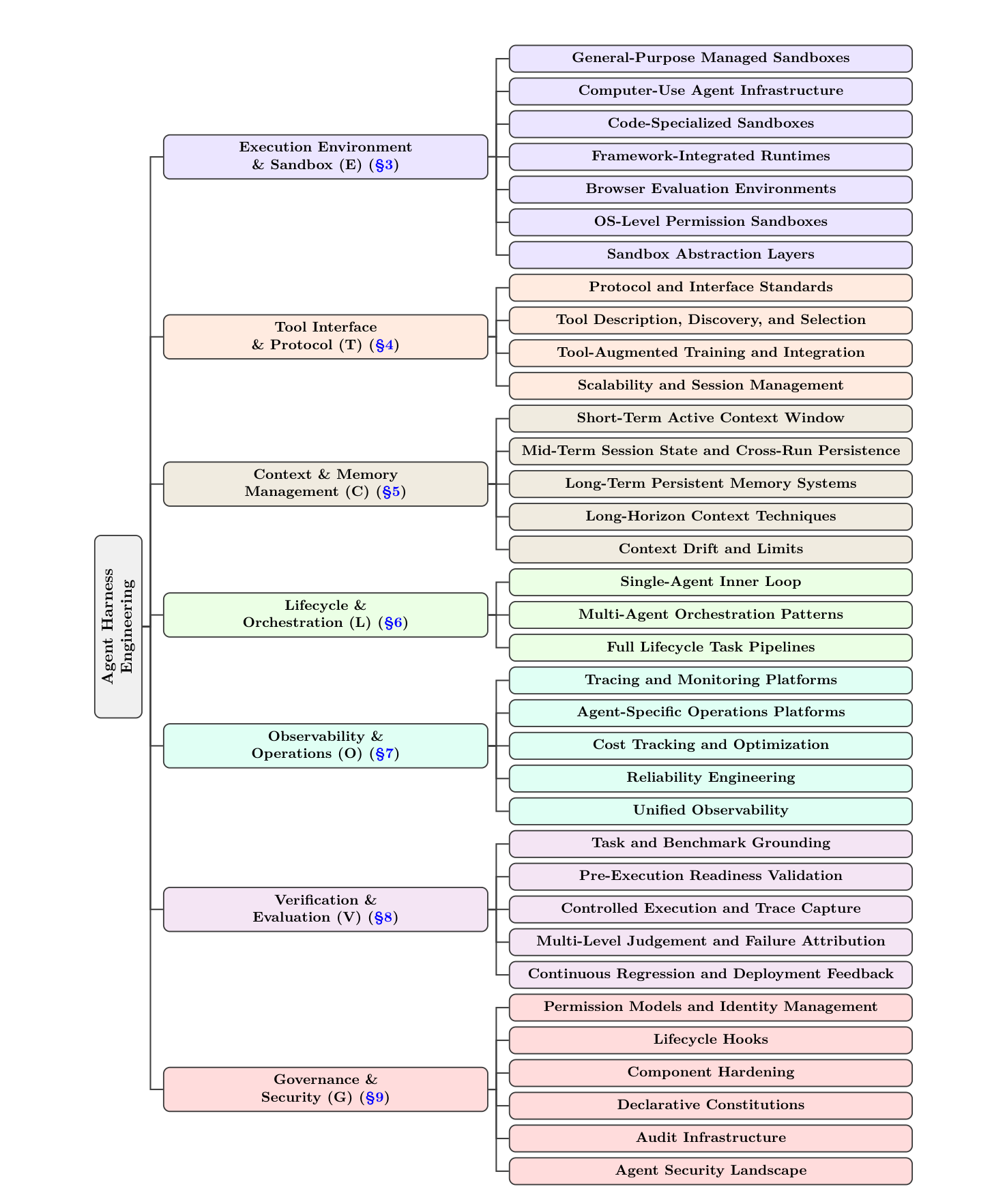
论文 Figure 4 显示的细分中,几个关键观察:
- E 层(执行环境) 拆成 7 个子类——通用管理沙箱、计算机使用 agent 基础设施、代码专用沙箱、框架集成运行时、浏览器评测环境、OS 级权限沙箱、沙箱抽象层。
- O 层(可观测) 拆成 5 类:追踪/监控平台、agent 专用运维、成本追踪与优化、可靠性工程、统一可观测。
- V 层(验证) 拆成 5 个子阶段:任务与基准锚定 → 执行前准备验证 → 受控执行与 trace 捕获 → 多层判断与失败归因 → 持续回归与部署反馈。这是论文的”5 阶段 task-to-feedback lifecycle”原创框架(见 Figure 12)。
- G 层(治理) 拆成 5 类:权限模型与身份管理、生命周期钩子(H1-H4)、组件硬化、声明式宪法、审计基础设施。
四、三阶段工程演进:Prompt → Context → Harness
论文用 Figure 1 解释了为什么 harness engineering 必然在 2026 年出现——它是工程抽象层级的必然结果。
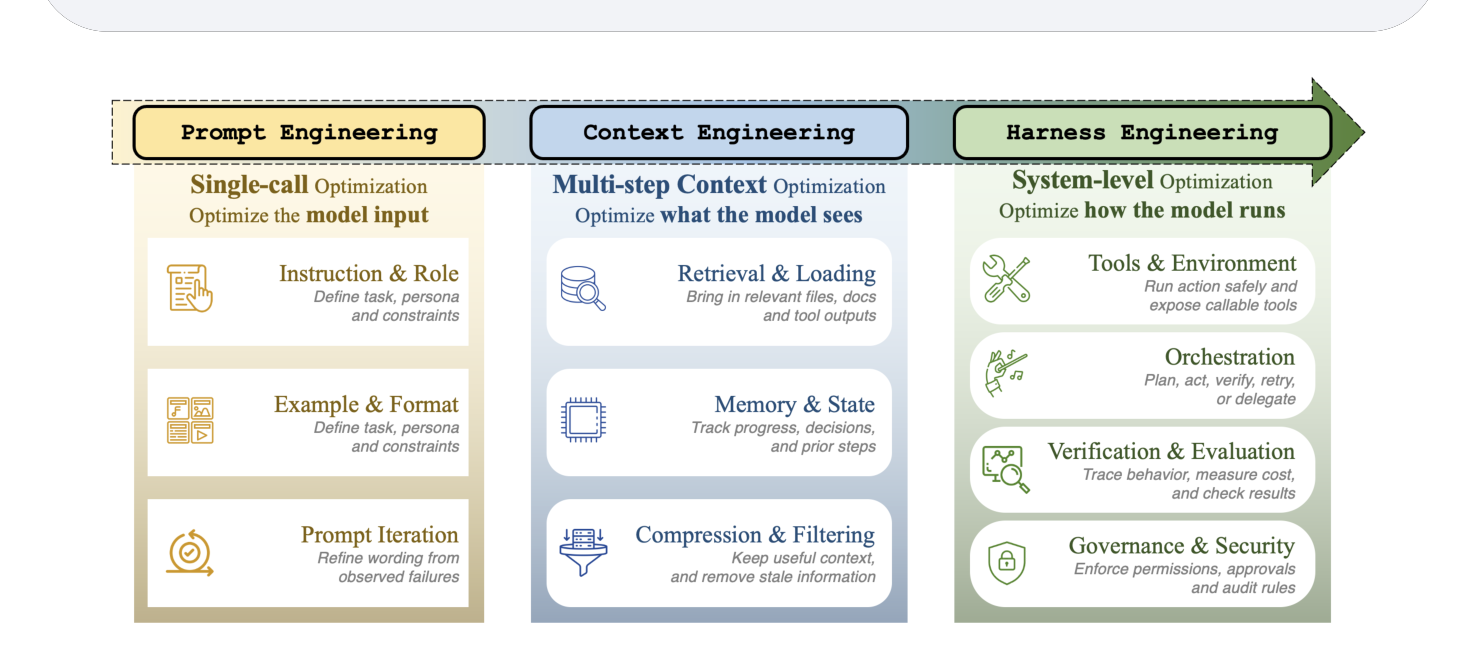
Prompt Engineering(2022-2024) 是第一阶段:把模型的输入 prompt 文本调好(指令调优、Few-shot、推理模板)。这个阶段的工程范围是”单次文本输入到单次模型调用“。它假设”模型能处理一切”,所以工程的目标只是”怎么说服模型”。
Context Engineering(2025) 是第二阶段:当 agent 变长跑时,”模型看到什么”比”模型被说什么”重要得多。Karpathy 在 2025 年推广这个概念——把”单次输入”扩展到”跨多步的信息状态”。典型的 context engineering 包括 RAG、记忆管理、压缩、progressive disclosure。论文明确指出:harness engineering 包含 context engineering,不是替代。
Harness Engineering(2026) 是第三阶段:模型本身无法独立处理的所有”周边问题”——执行环境、工具协议、orchestration、监控、评估、治理——都被纳入”harness”这一层。Harness 是把模型从”能回答问题”变成”能在真实世界完成任务”的必要容器。论文 Figure 1 的最后一栏把 harness 拆成”基础设施 wrapper”和”execution control feedbacks”两块,前者是基础设施层,后者是反馈环——合起来就是”控制论”视角下的”前馈 + 反馈”闭环。
一个关键观察:后一阶段是前一阶段的超集而非替代。每个 harness 组件都编码”模型做不到某事”的假设;模型变强时这些假设会过时——这就是论文第 12 节”五大未解问题”中Harness 随模型进化而自适应简化(adaptive simplification)的核心。
五、每一层:核心洞见与代表项目
这一节按七层顺序展开,每层抓住一个最有代表性的洞见,并介绍该层的代表项目。
5.1 E 层 - Execution Environment:Sandbox 在 agent 时代承担 3 种职能
论文关于 E 层最有冲击力的论断是:沙箱在 agent 时代承担的不仅是 security 和 reproducibility,还有第三种职能——liveness。
传统沙箱的”安全 + 可复现”目标是软件工程老问题。但 agent 时代多出的 liveness 维度,是说:sandbox 让 agent 在 bounded region 内”自由行动”,把每个动作的弹窗授权转成会话级配置。**Anthropic 报告 Claude Code 引入 sandboxing 后权限弹窗减少 84%**——这就是 liveness 价值的最直观证据。
论文 Figure 6 展示了 E 层 7 个子类的代表项目——

几个值得记住的项目:
- Daytona(72.4K stars):用 Docker containers 实现 sub-90ms 冷启动(vs Docker 通常 2-5 秒),让”per-call sandbox”成为可能。这是 agent 时代的专用沙箱——为 AI 重新设计,不是改造传统云沙箱。
- E2B(12.1K stars):用 AWS Firecracker microVM 做云沙箱。
- Anthropic Computer Use:旗舰商业 computer-use 实现,是该子类的标杆。
- OpenHands Runtime:研究级”一站式”runtime,把 Docker + bash + IPython + Chromium + API server 装在一个镜像里。
- SWE-ReX:跨云 sandbox 统一接口(Docker/Fargate/Modal/Daytona)。
E 层也有严肃的威胁面:论文引用 SandboxEscapeBench (Marchand 2026) 实测,前沿 LLM 在 Docker 容器中逃逸成功率 **15%-35%**——这不是”理论上能逃”,是”在嵌套沙盒 CTF 中实际能逃”。
5.2 T 层 - Tool Interface:协议按”集成边界”分类
T 层最有价值的不是某一个工具,而是协议分类学。论文 Table 1 把所有主流 agent 工具/接口标准按”集成边界”和四个能力轴排成矩阵——
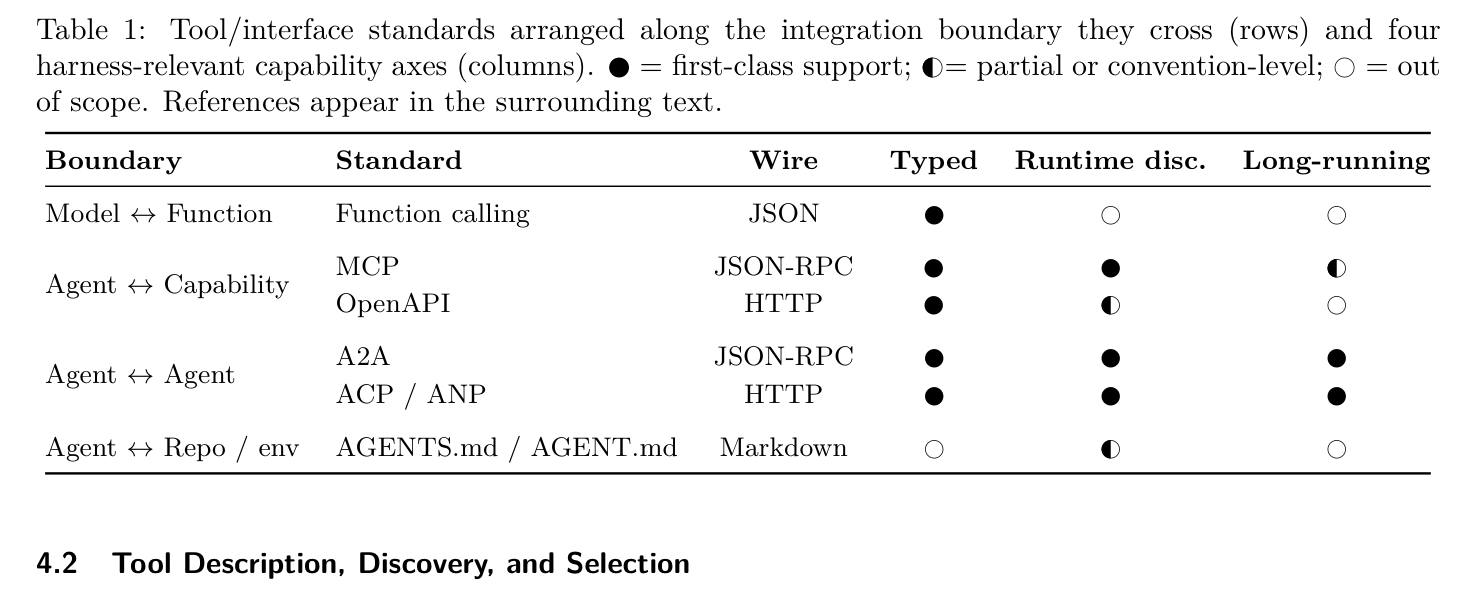
Table 1 显示了一个清晰的结论:**MCP 和 A2A 已经覆盖了 agent 工具层和 agent 间的全部”金标准”**。具体观察:
- Function calling 只覆盖 Model↔Function 边界,能力最强但不可发现。
- MCP(Anthropic 2024-11-25 发布)覆盖 Agent↔Capability 边界,是当前最可见的工具集成 substrate;JSON-RPC 线协议,类型化、运行时发现、支持长跑任务。
- A2A(Google 2025-04-09 发布)覆盖 Agent↔Agent 边界,是 agent 间通信标准;JSON-RPC 线协议,类型化、运行时发现、支持长跑任务。
- OpenAPI 是 HTTP API 描述标准,覆盖 Agent↔Capability 边界,类型化但不支持运行时发现。
- AGENTS.md / AGENT.md(21K stars)覆盖 Agent↔Repo/env 边界,是仓库级 agent 指令文件的标准——Anthropic、OpenAI、Google、Cursor 普遍支持。
值得注意:没有单一协议能同时覆盖”工具”和”agent”两类——MCP 和 A2A 是互补关系:MCP 管”agent 怎么调工具”,A2A 管”agent 怎么调 agent”。这与论文 Table 1 的”行”对应(按集成边界)非常吻合。
5.3 C 层 - Context Management:长上下文不解决记忆问题
C 层最有冲击力的事实是:长上下文窗口不解决记忆问题。三个机制共同决定 context 是稀缺资源——
- Quadratic attention:注意力计算是 O(n²),n 翻倍 → 计算 ×4
- U-shaped attention curve:模型对开头和结尾关注多,中间关注少(Liu et al. 2024 “Lost in the Middle”——20 篇文档中段放答案准确率掉 30%+)
- Context rot:Hong et al. 2025 评测 18 个前沿模型,全部随输入增长退化;200K 上下文模型在 50K 就开始掉点
C 层的代表项目——

最有代表性的项目是 Mem0——arXiv 2504.19413 (2025-04-28),由 Taranjeet Singh 等提出。Mem0 把”长期记忆”建模为 LLM 决策的 4 种操作:ADD(新建记忆)、UPDATE(丰富现有记忆)、DELETE(删除)、NOOP(无操作)。在 LOCOMO 基准上,Mem0 比 OpenAI 原生 memory 准确率高 26%、省 90% token;Python 包下载 1400 万+次,AWS Agent SDK 2025 独家选用。它的成功意味着 agent 工程的”上下文管理”正在从”模型自己处理”转向”专用层处理”。
C 层的另一关键洞察来自 KV-cache 经济学:Anthropic 缓存命中价 0.30/Mtok vs 未命中 3.00/Mtok,差 10 倍价。Manus 团队把 KV-cache hit rate 认定为”生产 Agent 最重要单一指标”。这意味着 agent 设计中”append-only context“(上下文只追加不修改)和”sub-agent isolation“(让子 agent 拿干净窗口做深度探索,只回 1-2k token 总结)这些设计模式不是”美学选择”而是”成本选择”。
5.4 L 层 - Lifecycle & Orchestration:从单 agent 到多 agent 到控制平面
L 层是论文中最大的子类(48 个项目),也是工程实践最丰富的层。
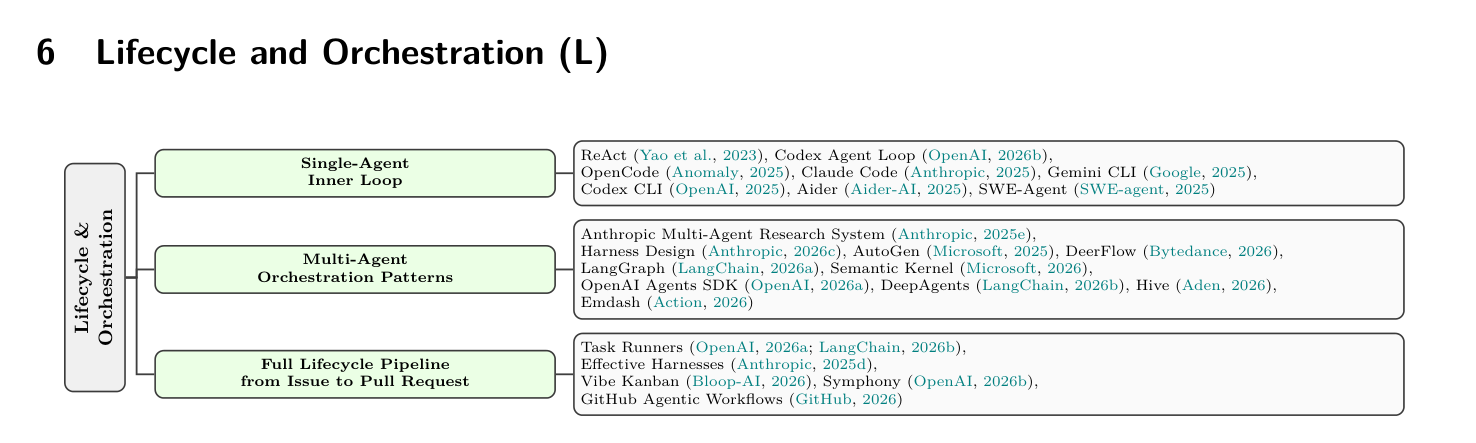
Figure 9 显示 L 层按”组织层级”分成三级:
- 单 agent 内循环(§6.2):OpenCode(155.8K stars)、Claude Code(120.9K)、Gemini CLI(103.3K)、Codex CLI(80.4K)、Aider(44.4K)、SWE-agent(19.1K)。这一类的代表哲学是”少即是多”——只暴露 bash/read/write/grep 几个核心工具,让 agent 自己组合。
- 多 agent 编排(§6.3):DeerFlow、AutoGen、LangGraph、OpenAI Agents SDK、DeepAgents。这一类走相反路线——planner/generator/evaluator 各司其职,靠分工换质量。
- 全生命周期管道(§6.4):Vibe Kanban、Symphony、GitHub Agentic Workflows。这一类把 issue tracker + repo 作为 agent 工作的”控制平面”,人工审批成为流程一部分。
多 agent 编排的范式正在快速收敛:Anthropic 2025-2026 的工程博客提出 Planner-Generator-Evaluator 标准三 agent 角色,并借鉴 GAN 思想加 sprint contracts 防止自评偏见。Anthropic 2026c 实证:从 Opus 4.5 升 4.6 后,移除 sprint contract 和 context reset,成本从 $200 降到 $125,质量不变——这是”adaptive simplification”思想最有力的证据。
5.5 O 层 - Observability:89% 用可观测,52.4% 做评估
O 层最有冲击力的事实是 LangChain 2026 调查:89% 团队用可观测工具,只有 52.4% 做离线评估——能看 agent 做了什么但没系统判断”做得对不对”。
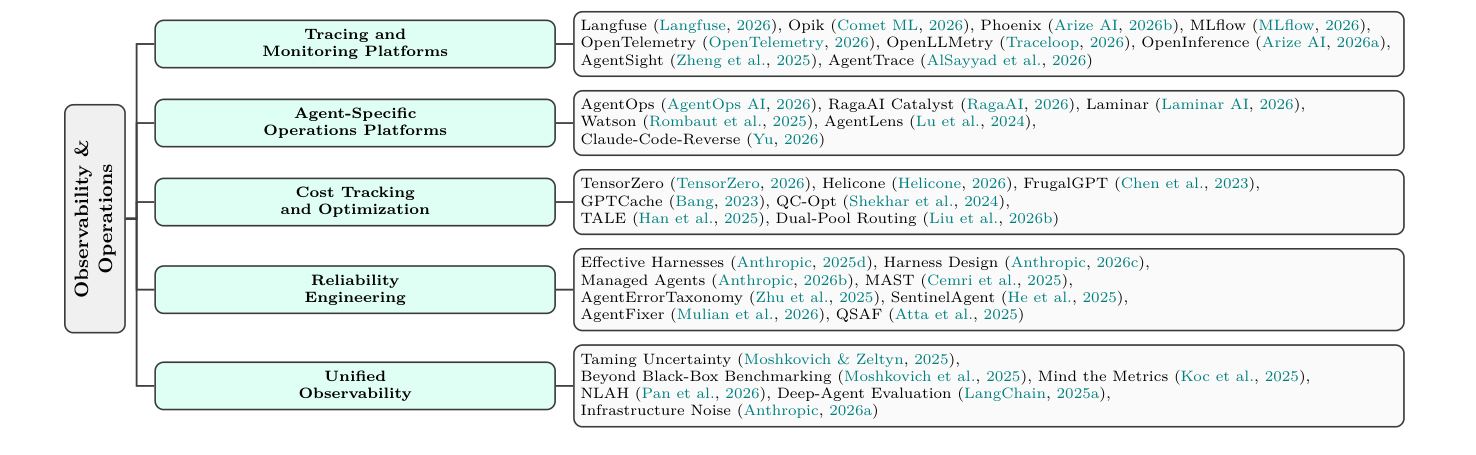
O 层最有技术含量的项目是 AgentSight——eBPF-based monitoring。eBPF 是 Linux 内核的”可编程探针”技术,可在 SSL 边界拦截 LLM 流量。AgentSight 用这个机制做框架无关、<3% CPU 开销、被攻陷 agent 也无法绕过的监控——这是从内核层而非应用层做可观测,安全性上一个数量级。
另一个工业级实践是 Dual-Pool Token-Budget Routing(Anthropic 2026a):把 vLLM 集群拆成短/长上下文池,Azure 上减 31-42% GPU 小时,年省 $2.86M(A100 规模)。
O 层也面临 MAST 失败模式(Cemri 2025)——多 agent 系统 14 种失败模式,3 大类(系统设计、agent 间失配、任务验证)。这意味着 O 层不只是”看”——是”识别 14 种翻车方式”的诊断能力。
5.6 V 层 - Verification:5 阶段 task-to-feedback lifecycle
V 层是论文最有方法论贡献的部分——把”评估 = 打分”升级为”评估 = 质量控制回路”。
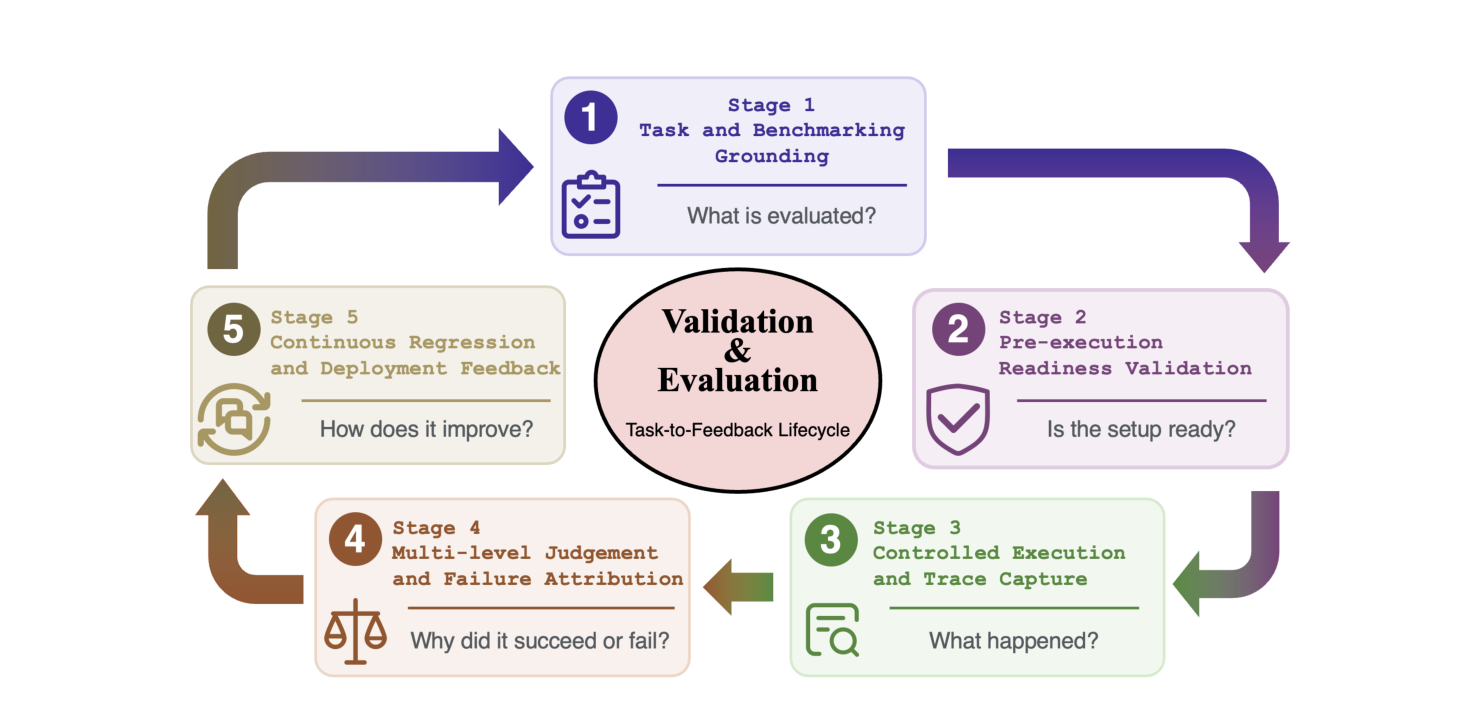
论文 Figure 12 把评估拆成 5 个阶段:
- Task and Benchmark Grounding(任务与基准锚定):定义任务(环境状态+可用工具+允许动作+约束+终止条件+成功标准)
- Pre-execution Readiness Validation(执行前准备验证):开跑前验证 sandbox、依赖、工具、上下文、权限、预算、打分器都对齐
- Controlled Execution and Trace Capture(受控执行与 trace 捕获):rollout 时记录 model output / tool call / state 变化 / error / retry / cost / latency
- Multi-level Judgement and Failure Attribution(多层判断与失败归因):outcome / trajectory / evaluator 三级评估 + 跨 harness 层归因
- Continuous Regression and Deployment Feedback(持续回归与部署反馈):评估结果变回归测试、监控信号、harness 改进反馈
关键洞察:V 层的设计反向喂给 L 层——评估机制奖励某些恢复循环、惩罚另一些,从而塑造 agent 行为。这与 L 层的设计是双向耦合的(harness coupling problem)。
代表项目(Figure 11):

- Promptfoo(20.9K stars):eval-as-code 范式,把测试用例写进 YAML 自动跑
- DeepEval(15.2K)、RAGAS(13.8K)、SWE-bench(4.9K)
5.7 G 层 - Governance:H1-H4 钩子 + 21.7% 幻觉包名
G 层是论文识别的”卡脖子短板”——Table 4 显示六大主流 agent(Codex、Gemini CLI、OpenHands、Browser Use、Nanobrowser、Skyvern)全部缺失 IFC(信息流控制)、身份管理、形式化验证。

G 层最有可操作性的概念是 H1-H4 生命周期钩子——

Figure 14 显示了一个工具使用循环中 4 个 hook 位置:
Input → H1 → LLM → H2 → Tool → H3 → Context → ... → H4 (HITL) → Response- H1:验输入(防 prompt 注入)
- H2:验动作(防越权)
- H3:验工具返回(防数据污染/taint tracking)
- H4:人类审批(高危动作人工 gate)
G 层最有名的开源项目是 LiteLLM(45.9K stars,gateway/proxy/guardrails)——把传统 API gateway 的所有能力(鉴权/限流/缓存/审计)平移到 LLM 时代。
Table 3 把治理机制映射到 7 大风险类(R1-R7)——

G 层最让人警醒的事实是 Slopsquatting 攻击:开源模型 21.7% 会产生幻觉包名(Spracklen 2025),攻击者抢先注册 → 注入恶意代码。这意味着 agent 在安装依赖时本身就是攻击面。
六、跨层综合:三大 Trade-off
跨层综合是论文最有”智识密度”的部分。三个 trade-off 不是新发现,但被首次系统化。
6.1 成本-质量-速度三角
核心论断:质量不是标量目标;必须选”哪些风险值得花代价”、”哪些检查可异步/放回归集”、”每阶段值得捕获哪些遥测”。
具体权衡:更强 sandbox → 安全与可复现 ↑ 但启动延迟 + 成本 ↑;更丰富 context/memory → 任务连续性 ↑ 但 token + 检索开销 ↑;更深评估/可观测 → 诊断能力 ↑ 但迭代变慢 + 存储/标注/trace 处理成本 ↑。
最尖锐的数据点是 Anthropic 2026a 警示:基础设施配置本身能让基准分数偏移 6 个百分点(p<0.01)——成本与评估保真度强耦合。这意味着模型升级的”分数”是被 harness 配置放大的,所谓”模型更好”很多时候是”我们用更好的 harness 跑出来的”。
6.2 能力-控制权衡
核心论断:更”能干”的 harness = 更多授权 = 更大攻击面。这不是安全附加项,是设计主轴,贯穿工具 schema、context 策略、运行时权限、身份、审计、人审。
具体权衡:更大工具菜单 → 任务覆盖 ↑ 但选择错误 + prompt 注入面 ↑;持久记忆 → 长任务友好 但来源/staleness/隐私风险 ↑;宽松沙箱 → 自主执行更有效 但 blast radius(爆炸半径)↑。
真实案例:Anthropic 2026c 实验——放开 context reset 和 sprint contract 后,agent 自主性更强但成本翻倍。这印证了 capability-control 的硬性折中。
6.3 Harness 耦合问题(Harness Coupling Problem)
核心论断:层与层相互依赖 → 局部最优是脆弱的。A 在隔离下看着好,组合进整个控制环可能反而劣化。模型分数无法干净归因到模型本身(因为控制器 C_H 已经变了)。
具体例子:
- E 改变 V 结果(包可用性、reset 语义、延迟、失败模式)
- 工具描述消耗 context 预算、塑造模型行为
- 可观测 trace 要成为治理证据需要同等粒度的身份/权限状态
- V 设计反向喂给 L(奖励某些恢复循环、惩罚另一些)
方法论启示:harness 改动要作为系统级改动测试,不能把模型分数干净归因到模型。这就是为什么论文第 12 节把”Harness 随模型进化而自适应简化“列为五大未解问题之首。
七、OpenAI / Anthropic / LangChain 的生产经验精华
论文最有”行内情报”价值的部分是从三大厂商博客/演讲/工程文章中提炼的经验。
7.1 OpenAI:harness engineering 是工程口号
OpenAI 工程师在 2026-02-11 工程博客 Harness engineering: leveraging Codex in an agent-first world 中明确使用”harness engineering”作为术语。几个关键事实:
- 5 个月内小团队产出约 100 万行内部产品代码,无手写生产代码(OpenAI 2026a)——这不是个人生产力的提升,是组织级别的范式转移
- Codex CLI(2025-04 开源,2026 年 1 月已 67K stars)走 stateless replay 路线——每次执行都从 prompt + 工具结果从头来,trace 完整可复现
- Symphony 把 issue tracker + repo 作为 agent 工作的”控制平面”,分配、进度状态、验证 gate、review 边界都是 Codex 编排的显式部分
- **Meta-Harness (Lee 2026)**:自动 harness 优化在 Terminal-Bench-2 上达到 **76.4%**,超越所有手工方案
OpenAI 的核心论文(2026a)证明:仅靠基础设施配置 + system prompt 重组 + 自验证 hooks 就能让 Terminal-Bench 2.0 从 52.8% 升到 66.5%——**+13.7 pp 提升来自 harness 改动**,而 GPT-5.2 模型升级在该 benchmark 上只带来 2-4 pp。
7.2 Anthropic:GAN 启发的三 agent 与 Managed Agents
Anthropic 在 harness 上的实践最深——可能因为他们认为 harness 是 Anthropic 的护城河之一。
- Claude Code(2025-02 发布,120.9K stars):终端编码 agent,Fewer but better tools 哲学——只暴露 bash/read/write/grep 几个核心工具。引入 sandboxing 后权限弹窗减少 84%。
- GAN-inspired three-agent(Anthropic 2026c):借鉴 GAN 的对抗式三 agent(planner / generator / evaluator)+ sprint contracts 防自夸。最反直觉的发现:从 Opus 4.5 升 4.6 后,移除 sprint contract 和 context reset,成本从 $200 降到 $125,质量不变——这就是 adaptive simplification 的最强证据。
- Managed Agents(Anthropic 2026b):把 brain(harness+LLM)/ hands(sandbox+tools)/ session(durable event log)三层解耦,**”Pets vs. Cattle” 化**——任何组件崩了都能自动重启恢复。
- Long-Running Agent Harness(Anthropic 2025d):总结 4 种长跑 agent 失败模式——① 试图一把搞定全任务 ② 过早宣布完成 ③ 跨 session 留下坏环境 ④ 不测试就标 done。
7.3 LangChain:89% 团队用可观测,52.4% 做评估
LangChain 作为 agent framework 的事实标准,在生产经验上有独特视角:
- LangGraph 31.3K stars(图组合的 multi-agent runtime)、deepagents 22.3K(runtime/long-running)——图组合是 multi-agent 编排的主流范式。
- LangChain 调查揭示 observability-evaluation gap:89% 团队用可观测工具,52.4% 跑离线评估。这意味着大多数团队能”看到”agent 做了什么但没系统判断”做得对不对”——这正是 V 层要解决的。
八、五大未解问题
论文最诚实也最有价值的地方是它不假装给出了全部答案。§12 列出的 5 大未解问题(实际是研究议程):
8.1 硬化与扩展执行环境
SandboxEscapeBench 证明前沿模型能在现实配置下逃逸(15-35% 成功率)。防御工作碎片化,一容器一任务模式在万级并行下压力大。开放问题:让运行时 substrate 既可测又可组合;需要 prompt injection / 目标错位 / 组合放大的共同评测。
8.2 长跑 Agent 维持可靠状态
最深 context 问题不是”装更多 token”,而是长视野下工作状态与真实任务状态的对齐。反复 summarize/retrieve/compact/externalize 都会删除约束、扭曲优先级、保留过期假设。应把 context 管理重新建模为状态估计(state estimation):每次压缩/检索/遗忘丢失多少任务相关信息?
8.3 从 Agent Traces 诊断失败
失败可能源自:模型推理、误导性工具 schema、sandbox 错配、stale context、flaky 测试、benchmark 模糊、judge 不稳定、orchestration 循环。Anthropic 2026a 证明基础设施设置能移动 benchmark 分数 6 pp。评估层要作为测量仪器来研究,不只是 leaderboard。
8.4 跨 Agent/Tool/Human 的标准化 Handoff
局部标准已有:MCP(工具)、A2A(agent 间)、OpenTelemetry(trace)。缺少跨层 handoff 契约:planner 交给 executor、agent 调工具、subagent 还控制、系统升级给人——交接应带意图/约束/权限/工件/provenance/预算/风险/trace 历史/未决决策。开放问题:定义足够丰富以保证安全恢复、足够简单以广泛采用的 handoff 协议。
8.5 Harness 随模型进化而自适应简化
假设 harness 单调变复杂是错的;每个干预都编码”模型不能做什么”的假设。因子 model × harness 评测可揭示:跨模型都帮的 / 只帮特定家族的 / 反转模型排名的。Anthropic 2026c 真实案例:原本对某个模型有用的 context reset,模型变强后可移除且省成本不降质量。核心机制:Meta-Harness(搜索 prompts/tools/control loops)、Natural-Language Agent Harnesses(把模块显式可消融)、TensorZero/Axon/AgentOps(成本感知运营)。终极目标:adaptive simplification——harness 持续追问”哪些控制还有必要”。
九、关键项目一览(按层归类,挑重要的)
论文附录 A 列出 171 个项目,下面挑每个层最值得记住的几个。
E - 执行环境
- Daytona 72.4K ⭐(sub-90ms 冷启动,AI 时代专用沙箱)
- E2B 12.1K(Firecracker microVM)
- OpenSandbox 10.5K(阿里开源)
- Anthropic Computer Use(旗舰商业)
T - 工具接口
- MCP Servers 85.1K(MCP 生态 server 集合,Anthropic 2024-11)
- AGENTS.md 21.0K(仓库级 agent 指令文件标准)
- GitHub Spec Kit 92.9K(spec-driven workflows)
C - 上下文与记忆
- Mem0 41K ⭐(长期记忆层事实标准,AWS Agent SDK 2025 独家选用)
- claude-mem 72.8K ⭐(Claude Code 记忆层)
- Trellis 7.2K(specs/memory/workflow)
L - 编排(最大子类)
- OpenCode 155.8K ⭐(Anomaly 开源,sub-agents 标杆)
- Claude Code 120.9K(Anthropic 旗舰)
- Gemini CLI 103.3K(Google 旗舰)
- Codex CLI 80.4K(OpenAI 旗舰,stateless replay 范式)
- OpenHands 72.7K(研究级 runtime)
- DeerFlow 65.4K(long-horizon/memory)
- LangGraph 31.3K(LangChain 图工作流)
- OpenAI Agents SDK 25.9K(handoff/workflows)
O - 可观测
- Langfuse 26.7K ⭐(OpenTelemetry 兼容 LLM 追踪)
- MLflow 25.8K(平台/监控/评估)
- Opik 19.2K(Comet 旗下)
- TensorZero 11.3K(成本优化)
V - 评估
- Promptfoo 20.9K ⭐(eval-as-code 标杆)
- DeepEval 15.2K
- RAGAS 13.8K
- SWE-bench 4.9K(GitHub issue 修复基准)
- Terminal-Bench 2.2K(terminal/long-horizon)
G - 治理
- LiteLLM 45.9K ⭐(最大治理工具——gateway/proxy/guardrails)
- Kong 43.3K(gateway/policy/infra)
- Archestra 3.6K(enterprise/guardrails)
- Portkey 11.6K(gateway)
附录 B 6 个参考实现的 7 层覆盖矩阵
论文附录 B 详细剖析了 6 个旗舰 harness:
| 实现 | E | T | C | L | O | V | G | 特点 |
|---|---|---|---|---|---|---|---|---|
| Claude Code | ✓ | ✓ | ✓ | ✓ | ✓ | 终端编码;生产级闭源 | ||
| OpenCode | ✓ | ✓ | ✓ | 开源终端;plan/build/subagents | ||||
| Codex CLI | ✓ | ✓ | ✓ | ✓ | 无状态 replay 循环 | |||
| OpenHands | ✓ | ✓ | ✓ | ✓ | ✓ | 研究级可组合 SDK | ||
| SWE-agent | ✓ | ✓ | ✓ | ✓ | agent-computer interface | |||
| Symphony | ✓ | ✓ | ✓ | ✓ | 持久控制平面 + issue tracker |
关键观察:L 层全覆盖(编排是所有 harness 的核心),O 层 0/6 覆盖(可观测仍处于”作为独立层处理”的过渡期),G 层仅 2/6(治理仍是短板)。
十、给 Agent 工程师 / 研究者的一句话
“Harness engineering 是 2026 年 AI 工程的核心学科。模型升级带来 2-4 pp 的提升,harness 改动经常超过这个量级——这个数字本身就是该领域的全部论点。”
三个最值得带走的认知
第一,从”调 prompt”到”建平台”**。三阶段演进的终局不是”更好的 prompt”,而是”**可治理、可观测、可验证的运营系统“。Agent 平台是 harness 工程的下一个形态——tenancy、合规、计费、组织归属都成为 agent 系统的核心维度。这就是为什么 OpenAI 5 个月能写 100 万行代码——不是模型变聪明了,是 harness 让组织级协作成为可能。
第二,局部最优是脆弱的(Harness Coupling Problem)。prompt 改好、tool 改好、context 改好,组合进同一控制环可能反向。harness 改动要作为系统级改动测试,不能把模型分数干净归因到模型(控制器 C_H 已变)。论文把”评估层要作为测量仪器来研究”列为五大未解问题之一,意思是:今天我们还分不清”模型好不好”和”harness 好不好”。
第三,Harness 是有”保质期”的工程。Anthropic 2026c 实证——Opus 4.5 → 4.6 砍掉 sprint contract + context reset,省 37.5% 成本且质量不变。每个 wrapper/reset/verifier 都编码”模型不能做什么”的假设,模型变强时这些干预要被重新评估甚至移除。Adaptive simplification 才是 harness 工程的长期主义。
一个能立刻上手的 checklist
- C 层:pre-load 必备内容,retrieve 条件内容,compact 临近饱和,spawn sub-agent 处理会污染主上下文的子任务
- L 层:用 stateless replay 做 audit,用 stateful 做恢复
- O 层:接 Langfuse / MLflow / OpenLLMetry;做 cost tracking;做 eBPF 监控 agent 实际流量
- V 层:outcome / trajectory / evaluator 三级判断;用 Promptfoo / DeepEval / RAGAS 做 CI 评估
- G 层:H1-H4 四点 hook;用 LiteLLM / Portkey 做 gateway;用 AGENTS.md 让 agent 知道边界
附录:关键数据点速查
| 数据 | 出处 | 含义 |
|---|---|---|
| 52.8% → 66.5% (Terminal-Bench 2.0) | Trivedy 2026 | 仅改 harness 提升 13.7 pp |
| 76.4% (Terminal-Bench-2 自动 harness) | Lee 2026 Meta-Harness | 超越所有手工方案 |
| 100 万行代码 / 5 个月 | OpenAI 2026a | 小团队 + agent |
| 15-35% 沙箱逃逸率 | SandboxEscapeBench 2026 | 前沿 LLM 在 Docker 容器 |
| 84% 弹窗减少 | Anthropic Claude Code | sandboxing |
| 26% / 90% | Mem0 vs OpenAI Memory | 准确率/省 token |
| 6 pp (p<0.01) | Anthropic 2026a | 基础设施设置偏移 benchmark |
| 21.7% | Spracklen 2025 | 开源模型包名幻觉率 |
| 31-42% GPU 小时节省 | Dual-Pool Token-Budget | Azure vLLM 集群 |
| 98% 成本节省 | FrugalGPT cascade | 性能匹配 GPT-4 |
| 89% / 52.4% | LangChain 2026 | 可观测用 / 评估用 |
| 64-88% / 38% | AgentFixer 2026 | 检出率 / 解析错误 |
| $200 → $125 | Anthropic 2026c | Opus 4.5 → 4.6 砍 sprint contract + context reset |
| 171 项目 / 0 失效 | Table S1 2026-05-08 | 验证 0 失效链接 |
| 18 个月 | 2024-11 MCP → 2026-05 综述 | 行业从口号到学科的时间 |
参考资料
- 论文主页:Junjie Li 等,《Agent Harness Engineering: A Survey》,TMLR 投稿 2026-05-14
- 项目页:Awesome-Agent-Harness
- OpenAI 关键博客:Harness engineering: leveraging Codex in an agent-first world,2026-02-11
- MCP:Introducing the Model Context Protocol,Anthropic 2024-11-25
- A2A:Announcing the Agent2Agent Protocol (A2A),Google 2025-04-09
- Mem0:Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory,arXiv 2025-04-28
- Daytona:Daytona 官网
- Claude Code:Claude Code: Anthropic’s Agent in Your Terminal
- Codex CLI:OpenAI Codex CLI
笔记完。这篇论文的价值不在于提供答案——而在于给整个”agent 工程”领域装上了一套共同词汇。在 2026 年这个时间点,无论是 Agent 应用开发者、平台架构师、AI 投资人还是 ML 研究生,理解 ETCLOVG 七层、三大 trade-off、五大未解问题都是必要的。



