为什么要预测 action?
我最近在学习VLA、World Action Model,但有一个问题我始终都没有想清楚:为什么大家开始关注如何预测”action“了?
带着这个疑问,我回顾了近几十年机器人领域的一些论文,以及一些博客,写下了这篇文章。
0. 机器人的“智能”是一个什么样的问题?
研究机器人有两层价值。第一层是工程价值:让机器进入工厂、仓库、医院、家庭、道路和灾害现场,替人承担危险、重复、繁重或高精度的工作。第二层是认识价值:机器人把“智能是什么”这种抽象的问题,转化为了可被观察、可被检验的行为,(机器人的)“智能”会在行动、反馈、身体限制和环境变化中暴露出来[33][34][35][36][37][38]。
这里我展开讨论两篇论文。Six Lessons from Babies[39]主要探讨了智能怎样从身体、环境、社会和语言的耦合中发展出来,这篇论文认为智能体从早期能力很弱的状态开始,在多模态感知、渐进发展、物理世界、探索、社会互动和语言中逐步形成能力。而Self-evolving Embodied AI[40]主要是探讨具身智能怎么自我进化,这种能力怎样在持续部署中更新,这篇论文把这个问题推进到开放世界和长时间尺度:具身系统要在动态环境和可变身体中持续更新记忆、切换任务、预测环境、适配身体并让模型演化。
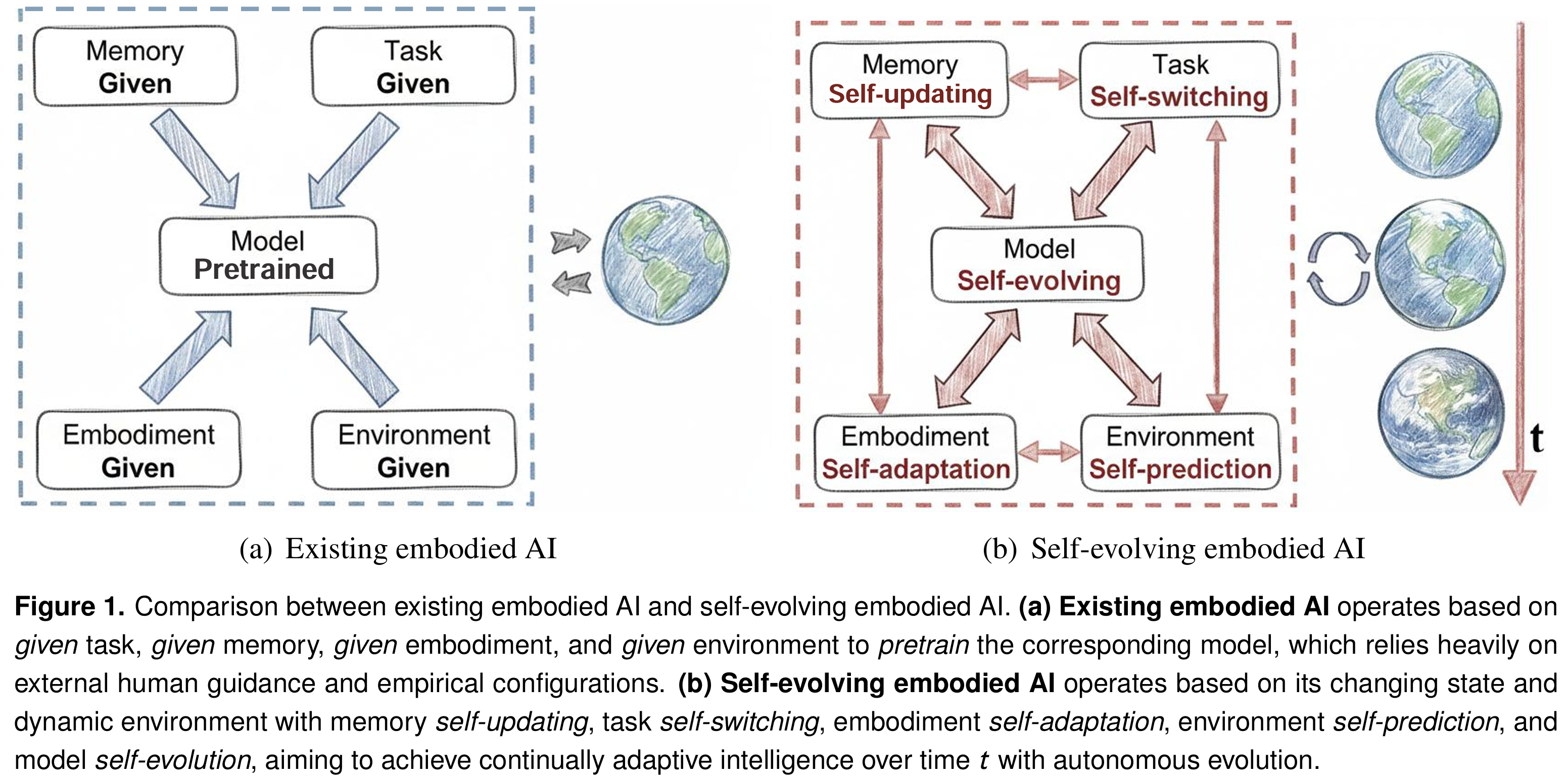
结合这些论文的讨论,我觉得机器人的智能问题可以概括为:行为泛化。这里的行为泛化,指一个有身体的智能体,怎样在环境、身体、目标、反馈、经验和时间都变化的情况下,继续生成、维持、修正、重组和扩展有效行为。其中,会说话会交流是一种行为,会执行一些动作完成一些事情也是一种行为。
1. 机器人的算法框架应该是什么样的?
在讨论本篇文章的主题之前,我们可以先来看一看,一个比较通用的机器人算法框架应该是什么样的。
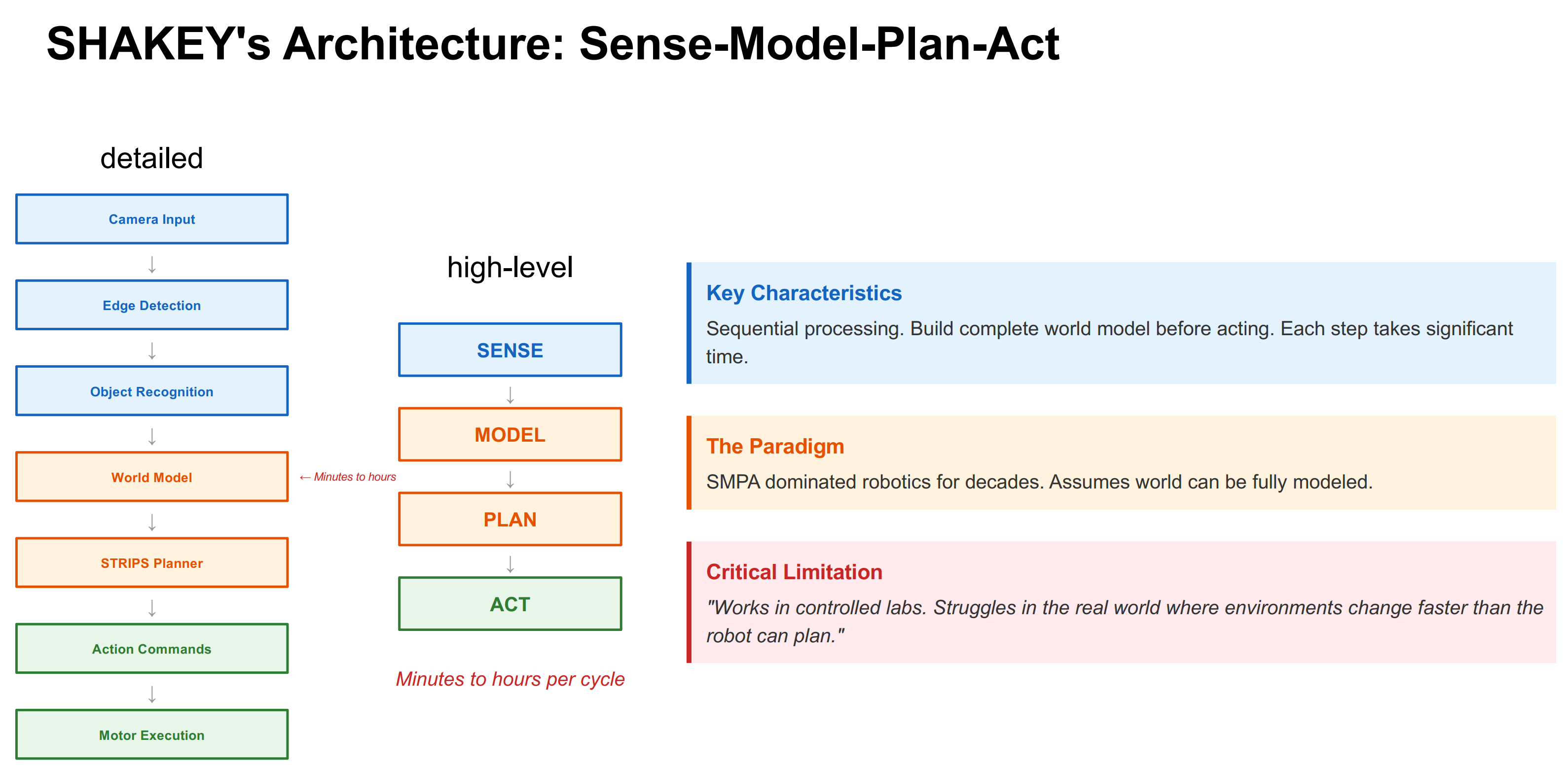
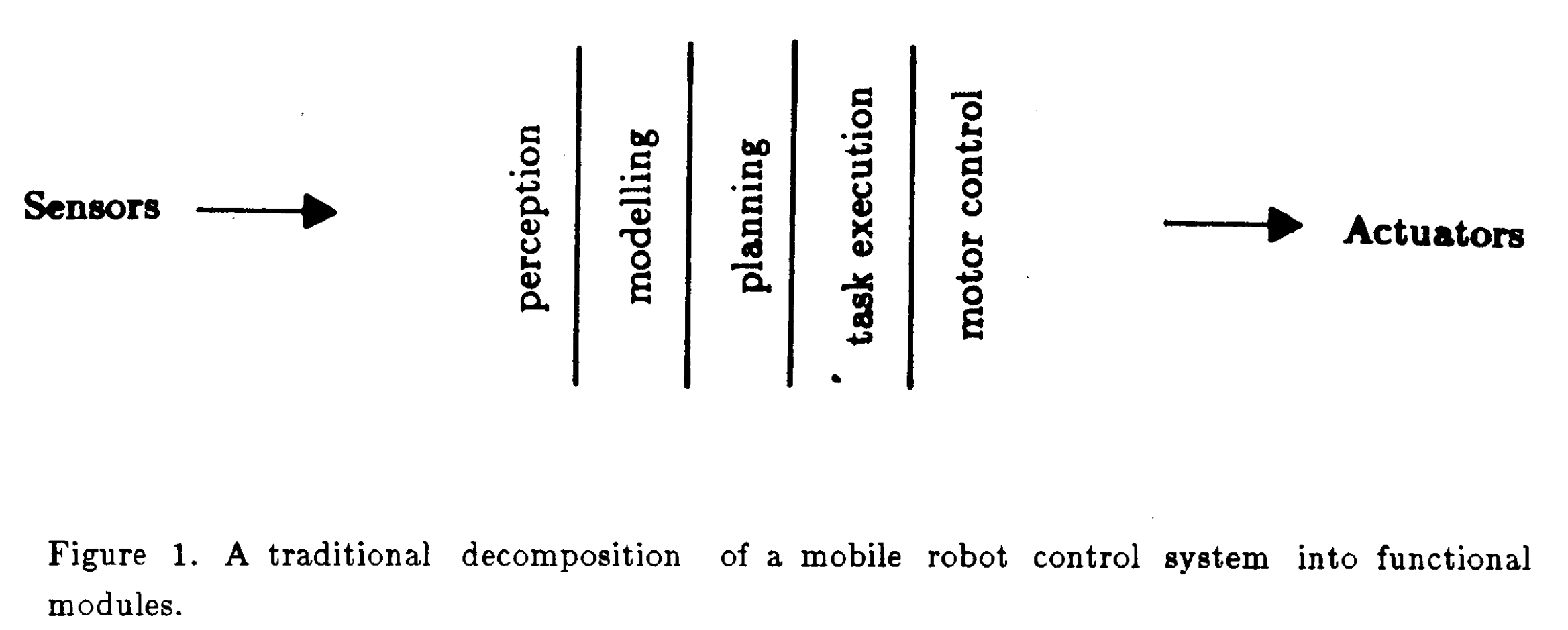
这个问题在上世纪60-70年代,就有相关的研究了,当时的人们认为,机器人应该先进行感知,再对这个世界进行建模,然后进行规划,再开始执行操作,把操作的信号发给电机,这个过程是串行的。1969年,Nils J. Nilsson[1]把这个过程分为了三步:(1) problem-solving, (2) modelling, and (3) perception。其中modelling的功能个人认为与现在的world model是非常相似的,“A body of knowledge about the effects of actions is a type of model of the world.”。而两年后,Nils J. Nilsson等人[2]把这个过程进一步细化,写成了initial world model、goal formula、operator、precondition 和 effect 的组合,让系统在 world models 的空间里寻找一串 operators完成任务。



显然,这一套方法(如下图[90],以及下下图的Figure 1所示)在当时存在很多问题,尤其是算力的瓶颈,导致这种串行的方法很难做到实时,而物理世界的变化往往是迅速的,机器人处理的往往是过时的信息。
其实更有名的可能是Scene-Plan-Act,出自SHAKEY THE ROBOT,作者也是Nils J. Nilsson,不过这里我引用了他更早期的工作。
对SHAKEY THE ROBOT感兴趣的朋友可以看:https://ai.stanford.edu/~nilsson/OnlinePubs-Nils/shakey-the-robot.pdf
对下面这一页PPT来源感兴趣的朋友可以看:https://embodied-ai-hku.github.io/DATA8010/
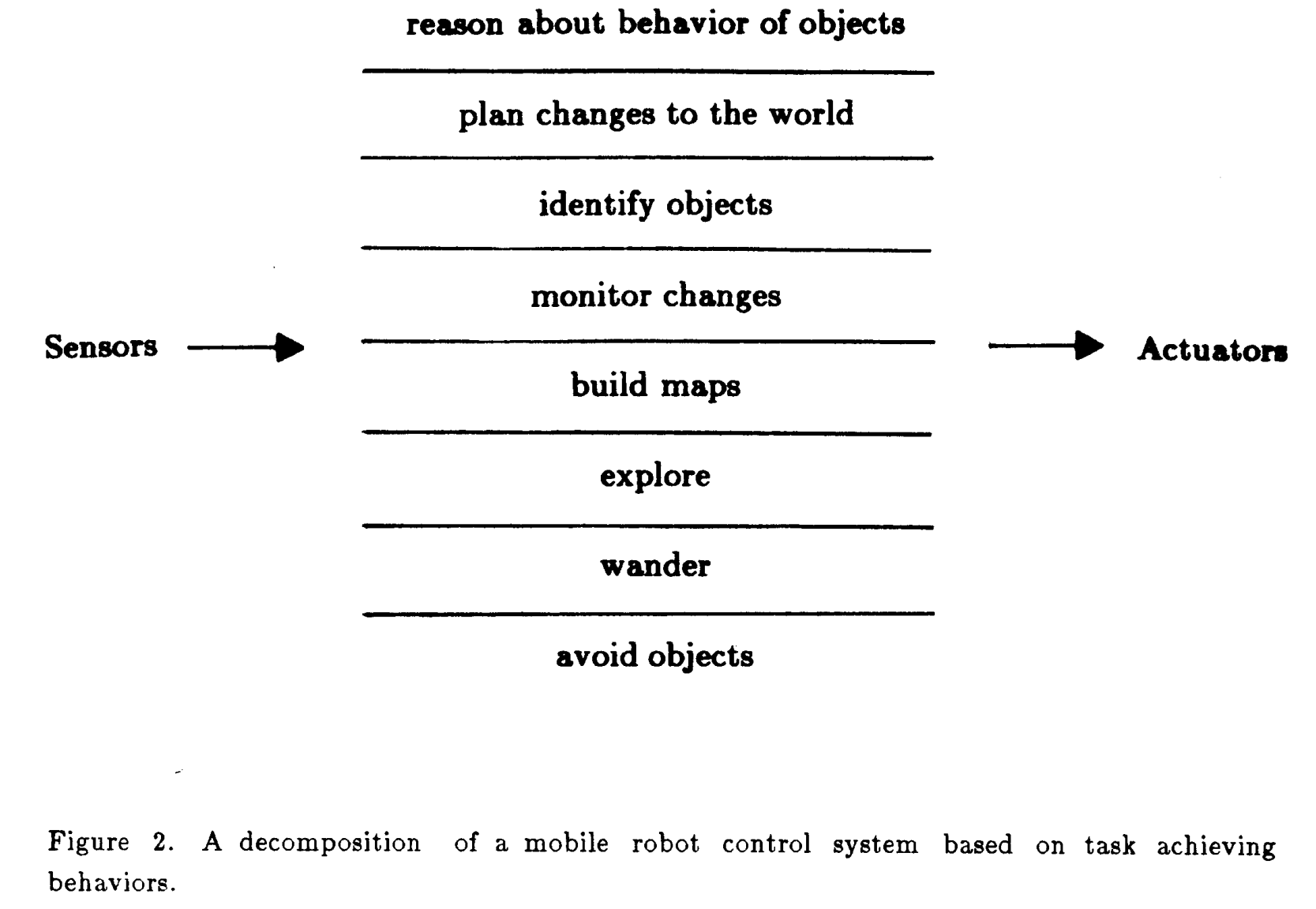
在1985年,Rodney A. Brooks提出分层控制系统(如下图的Figure 2以及Figure 3所示),低层行为持续运行,高层能力逐步叠加;每一层由异步模块构成,高层可以抑制低层输出,但低层仍然继续工作 [3]。之后Rodney A. Brooks进一步强调,简单层级的智能里,显式的去做world presentation有时会拖慢系统,可以让现实世界本身承担一部分计算 [4]。
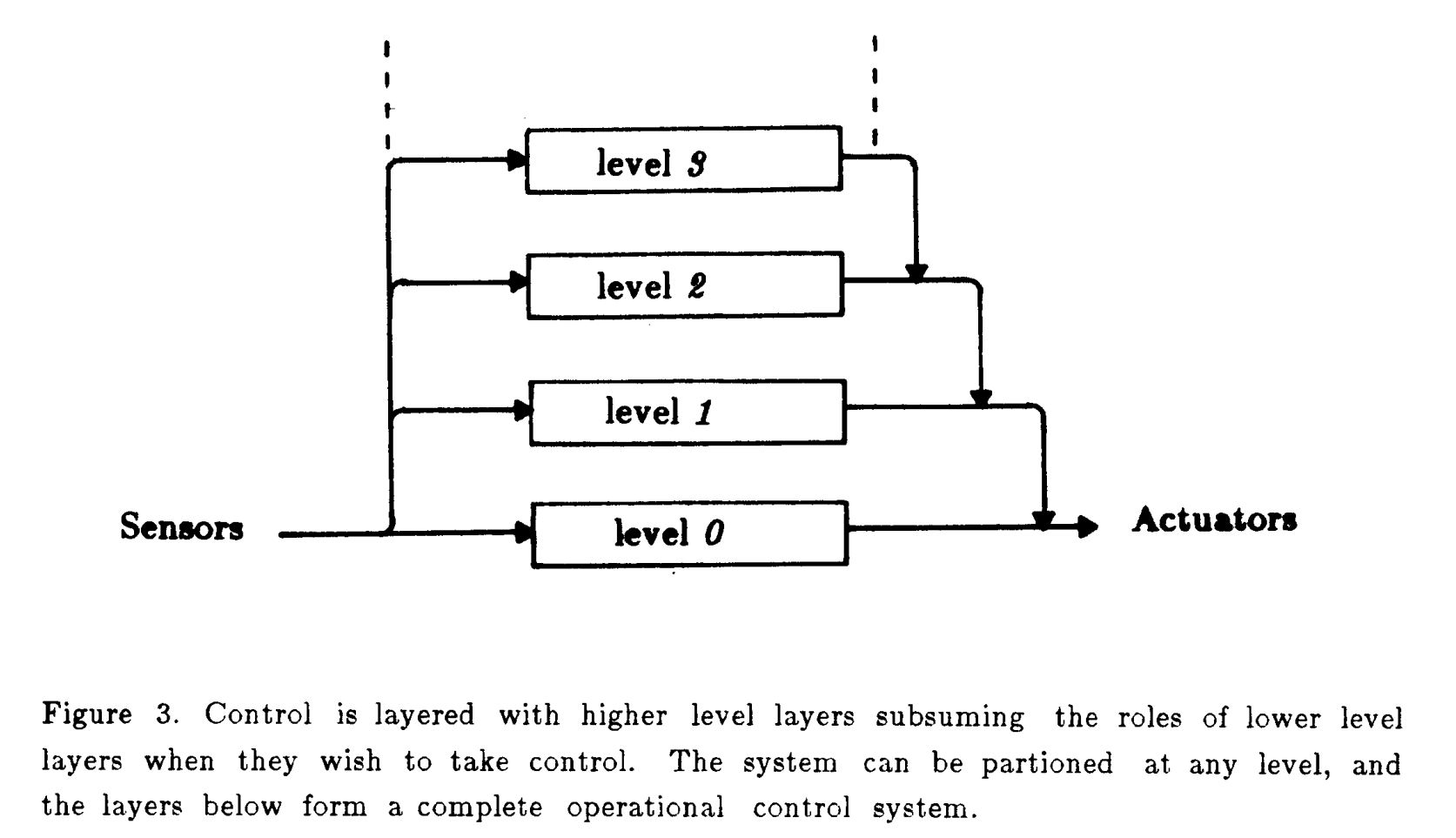
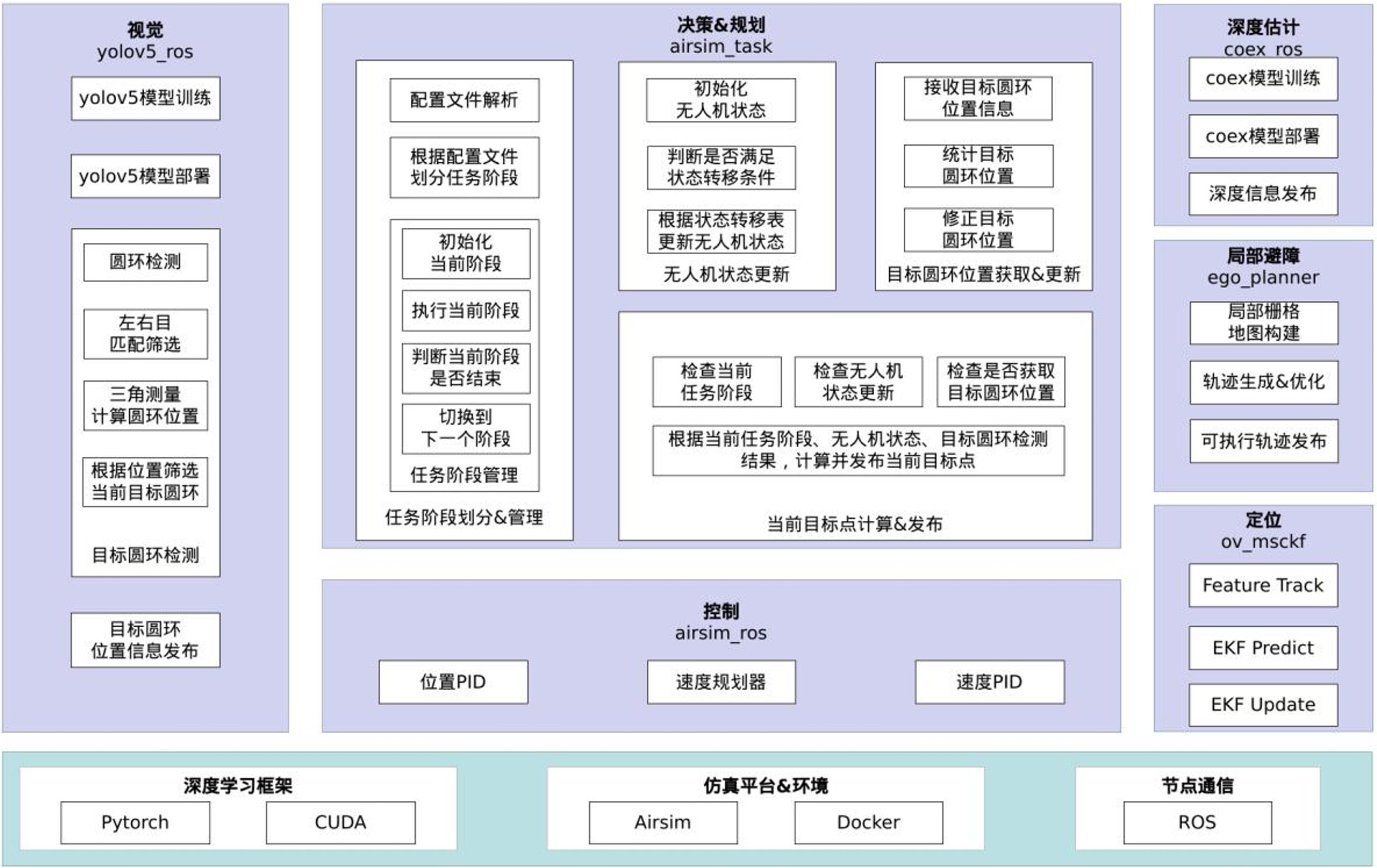
个人认为,Brooks提出的这个框架,基本成为了现在主流的机器人算法框架。整个系统会分为很多个并行的模块,模块之间存在交互。以我参加的RMUA无人机比赛为例,我们当时设计了如下的算法框架,把它套进Figure 3的框架中,那么Level 0应该是控制模块,Level 1应该是局部避障模块,Level 2应该是决策&规划模块,而Level 3应该是视觉、深度估计、定位等模块。后续的机器人系统,我觉得基本都和Brooks的这套框架差不太多。
可能套的不算严谨,Level 1、2、3并没有直接作用到Actuators上,而且Level 0最后发布的其实是一个速度信号,也不会直接被Actuators(无人机的电机)使用。
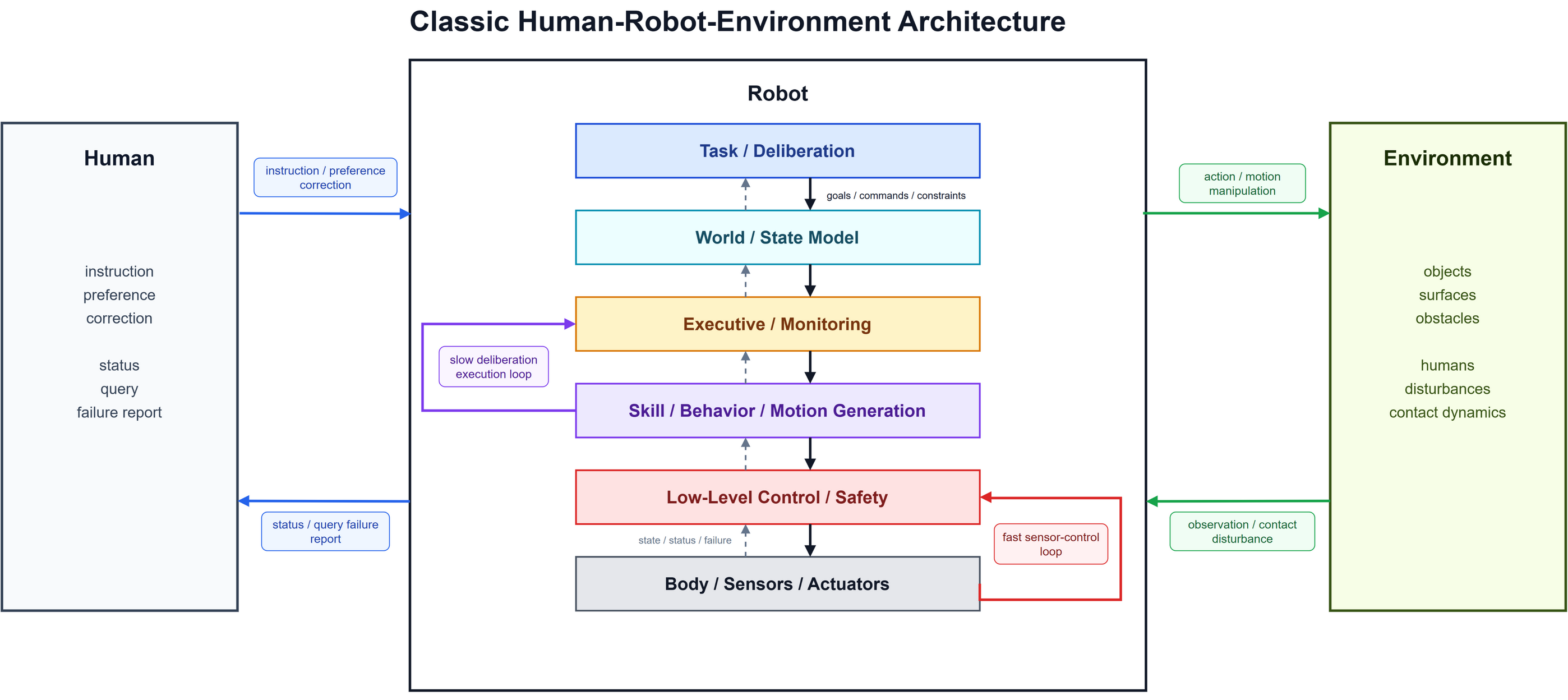
为了方便后续讨论机器人算法框架的变迁,我自己画了一个框图,如下所示。在这个框图中,人给出任务,机器人在环境中执行,与环境进行交互,而环境再通过传感器和状态反馈回到机器人系统。其中Robot里面的几个模块是并行的,后续介绍相关算法的时候,会在这个框图上进行绘制。机器人的框架中:L5负责目标、命令和约束;L4负责世界状态、机器人状态和任务相关记忆;L3负责调度、执行检查、检测和恢复;L2负责生成技能、行为和运动;L1负责底层控制、安全;L0是机器人的身体、传感器和电机。
2. 机器人算法的时代变迁
接下来我们开始讨论机器人算法框架的变迁,我会把每个阶段的算法重新绘制到上面的框图里面。我会从早期基于规则或符号的机器人算法,一直梳理到如今使用VLA、WAM的算法,之后再开始分析,为什么现在我们要研究如何预测action,这样可能更方便理解。
注:下面我只选择了一部分代表性的论文进行介绍。每个阶段更具体的工作可以去找对应的综述。
2.1 基于规则/符号的时代
在早期的机器人研究中[1][2][3][4],以及现在的一些工业流水线或自主机器人中(其实有一些电子游戏也是),机器人的任务会被写成一个结构化的表示,可能会存在目标的状态、机器人的状态、执行任务的条件/状态等等,机器人可能会维护一个状态机或者行为树[29][30]。
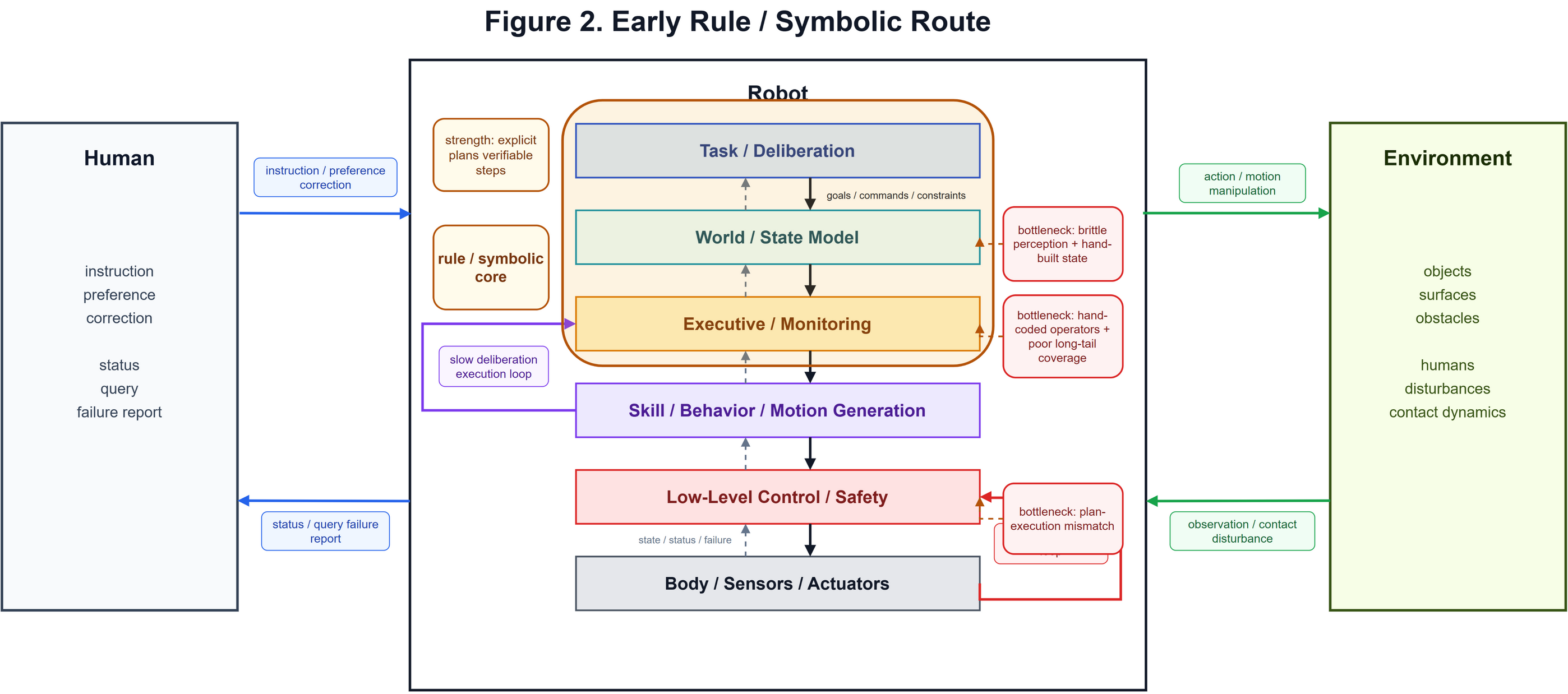
在这个阶段,机器人的智能主要以规则或者符号的形式体现,这也导致机器人的智能被牢牢的束缚在人为设置好的规则或者符号中,基本上只能执行给定的任务,如果工作的环境发生变化,或者进行新的任务,都需要大量的手工维护,而且很难在开放环境中完全自主的运行,因为人为设计的规则、符号几乎不可能完全覆盖现实的世界。
**尽管如此,这一套路线可能已经吃掉了机器人领域最大的一块蛋糕,很多高价值的事情已经被自动化了,这些东西本身不需要非常的智能,工业场景里面的环境也是相对可控的。留给具身智能来做的,可能是一些价值不高、更开放的、更困难的事情[31]**。
2.2 强化学习/模仿学习的时代
我认为基于规则/符号的算法已经能够让机器人做很多事情了,但是执行的动作可能是比较简单的,而更加复杂的动作,或者说运动控制,机器人可能做得并不好,比如骑自行车、乒乓球颠球、端盘子送水等等。当然这也涉及复杂、动态的环境以及一些非结构化任务,之前依赖人工设计规则的算法,在这些场景下很难覆盖所有接触、姿态、反馈等等细节[32]。为了解决传统控制方法难以应对的复杂场景,赋予机器人自主适应和泛化的能力,强化学习/模仿学习走上了舞台。
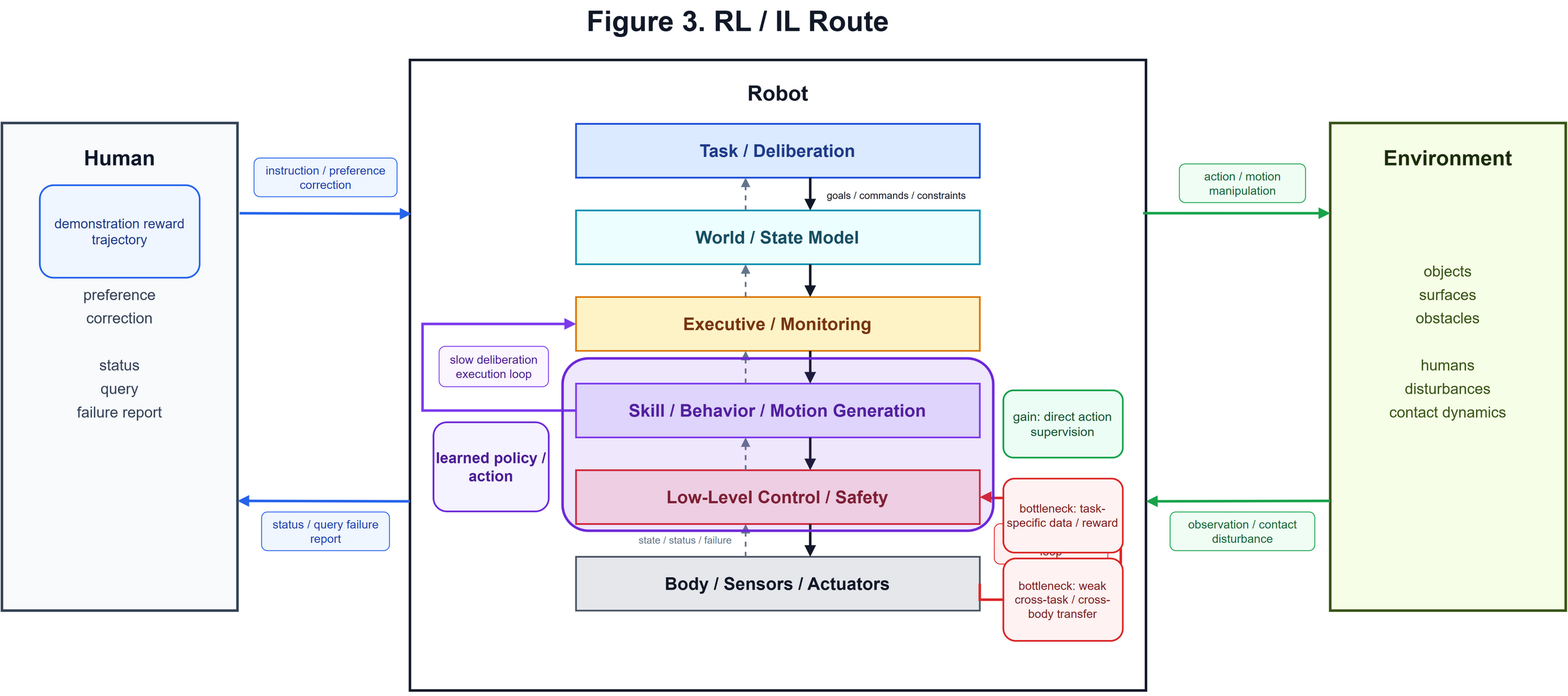
和之前基于规则或者符号的方法不同,强化学习把机器人的行为学习写成了一个“状态、动作、回报、转移”之间的闭环优化问题。最早的工作可以追溯到 Barto、Sutton 和 Anderson 1983 年的 pole-balancing 控制实验:系统只获得失败信号这类较弱的评价反馈,却仍然可以通过联结搜索单元和评价单元学习平衡杆控制,这已经把“机器人怎样从反馈中改善动作”放到了核心位置 [41]。Watkins 和 Dayan 后来给出 Q-learning 的收敛分析,把问题进一步明确为学习每个状态下不同动作的 action-value,并在受控 Markov 过程里通过反复采样动作来逼近最优策略 [42]。这条线随后分成几类关键方向:一类是 temporal abstraction,Sutton、Precup 和 Singh 提出的 options 把动作扩展为可持续一段时间的闭环策略,使 pick up object 这类多步行为也能作为决策对象进入 RL 框架 [43];一类是机器人 policy search 和 model-based RL,Kober、Bagnell 和 Peters 将机器人 RL 总结为通过 trial-and-error 生成难以手工设计的行为,并指出机器人场景的核心困难包括高维连续状态/动作、部分可观测、模型误差、真实试错成本和 reward shaping [44];PILCO 则用概率动力学模型和模型不确定性做数据高效的 policy search,在真实 cart-pole 等系统上用很少交互学习控制器 [45];深度强化学习之后,DQN 证明了神经网络可以从高维像素和分数信号中学习 action-value,依靠 experience replay 和 target network 稳定训练 [46],DDPG 把这条线推向连续动作空间和物理控制 [47],PPO 则用 clipped surrogate objective 在实现复杂度、稳定性和样本效率之间取得更实用的平衡 [48]。

上图来自 Levine 等人的 visuomotor policy 工作,展示了这一时期很有代表性的变化:策略不再只接收人工设计的低维状态,也可以直接从相机观测生成机器人控制信号 [55]。总而言之,强化学习把 action、reward、transition、policy、option 和 long-horizon return 组织进同一个学习框架,能够实现难以手工设计的行为,但是也存在一些明显的缺点:RL 要让机器人自己试错,往往需要大量真实交互,而且放任机器人探索也存在风险;很多任务的 reward 很难写,写得太稀疏会学不动,写得太密又会把人的偏好和工程技巧塞进奖励函数,而且模型很容易钻空子,违背我们设计的初衷。
因为这些瓶颈,强化学习很自然地转向模仿学习。模仿学习的思想非常直接:让人演示,记录 observation-action 轨迹,让模型学习“看到这种状态时该怎样动”。Pomerleau 1989 年的 ALVINN 就是很早的代表性工作,它用摄像头和激光测距输入,输出车辆应该行驶的方向,用神经网络学习道路跟随,这是非常经典的 perception-to-action 学习范式 [49]。Argall 等人的 LfD survey 将 Learning from Demonstration 概括为从示例 state-action mapping 中得到 policy,并系统整理了 teleoperation、imitation、policy derivation、dynamics model、plans 等多种形式 [50]。这条路线解决了 RL 的一部分现实困难:人类演示能减少盲目探索,能把有用状态区域、动作风格和恢复方式直接带进数据;同时,模仿学习也暴露出自己的核心问题,即演示数据只覆盖了有限状态。当 learned policy 离开专家轨迹分布时,小误差会把机器人带到训练集中没有见过的状态,错误会随着时间累积。DAgger 正是针对这个 covariate shift / compounding error 问题提出 dataset aggregation,让学习器在自己诱导出的状态分布上继续获得专家标注 [51]。另一条重要路线是 inverse reinforcement learning / apprenticeship learning:Abbeel 和 Ng 不直接克隆动作,而是从演示中恢复能解释专家行为的 reward 或 cost,再用 RL 求策略 [52];GAIL 进一步把 imitation learning 写成 occupancy measure matching,用类似 GAN 的方式直接从专家轨迹学习 policy,避免显式地先恢复 cost 再做完整 RL 的间接流程 [53];Guided Cost Learning 则把深度 cost learning 和 policy optimization 结合起来,服务更复杂的连续控制和机器人任务 [54]。在机器人操作里,Levine 等人的 guided policy search / visuomotor policy 工作把视觉输入直接接到 torque-level policy 上,展示了从 camera observation 到 motor command 的端到端训练可能性 [55]。再往后,Diffusion Policy 把模仿学习推进到生成式 action 分布建模:它把 visuomotor policy 表示为条件去噪扩散过程,可以表达多模态 action 分布、高维 action sequence,并用 receding-horizon control 支持闭环执行 [56]。
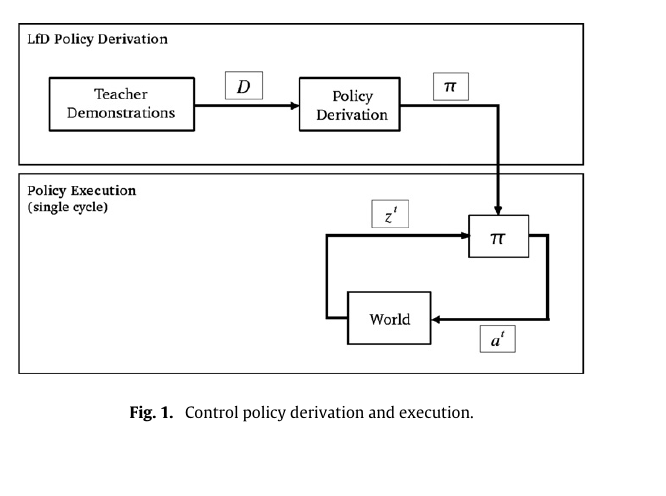
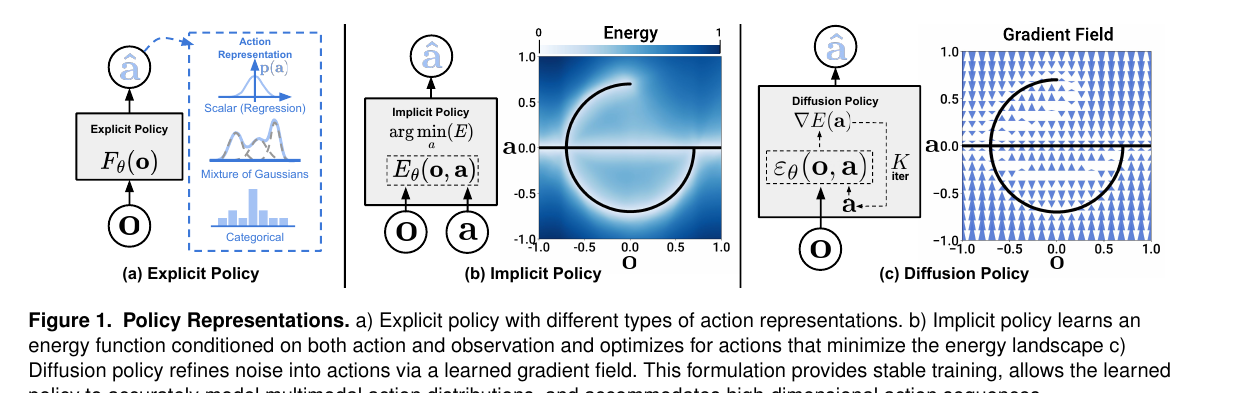
这两张图分别对应 LfD 的 policy derivation / policy execution 框架,以及 Diffusion Policy 对 explicit policy、implicit policy 和 diffusion policy 的对比。前者说明模仿学习怎样从演示数据得到可执行策略,后者说明现代的模仿学习方法已经开始直接建模更复杂的 action distribution [50][56]。
强化学习/模仿学习的优势在于:机器人不再完全依赖人工写的规则,可以从环境交互和人类演示中学习可执行 policy,而且这两种方法基本形成了 observation/state -> action/policy的pipeline,为后续的VLA、WAM等方法打下了基础。
强化学习/模仿学习的问题在于:强化学习依赖探索和奖励,真实机器人上代价高、风险大、样本效率难保证;模仿学习依赖演示覆盖,容易受到数据分布、演示质量和错误累积影响。更重要的是,这两种方法都是task-specific的,跨任务、跨物体、跨身体的泛化性差。
其实也有一些sim-to-real的工作这里没有讨论,比如:Tobin et al. 2017
2.3 LLM/VLM + Skill/Code
自然语言处理(NLP)早期其实有点像机器人,都是由 task-specific pipeline 组成的工程系统。典型流程是:为一个具体任务定义输入和标签,设计特征,训练一个分类器或序列标注器,再把多个模块串起来。例如分词、词性标注、命名实体识别、句法分析、机器翻译、问答、信息抽取往往有各自的数据集、特征、模型和评测方式。优点是可解释、可调试、局部模块可以单独优化;缺点是跨任务迁移弱,pipeline error 会传播,系统很难通过简单扩大数据和模型获得一致提升。
此处略过1w字。。。(时代变了,也许我应该说:1w token)
随着大语言模型(LLM)的成功,以及VLM的发展,人们开始尝试如何把LLM、VLM的泛化能力放到机器人上。比较有意思的是,最早期尝试在机器人中使用LM、VLM的方式很像基于规则或符号的方法,把 LLM/VLM 放在高层或中间层,让它们负责理解语言、分解任务、选择 skill、调用 API,最后再交给已有的 skill library、policy、controller、MPC 或 motion planner 执行。
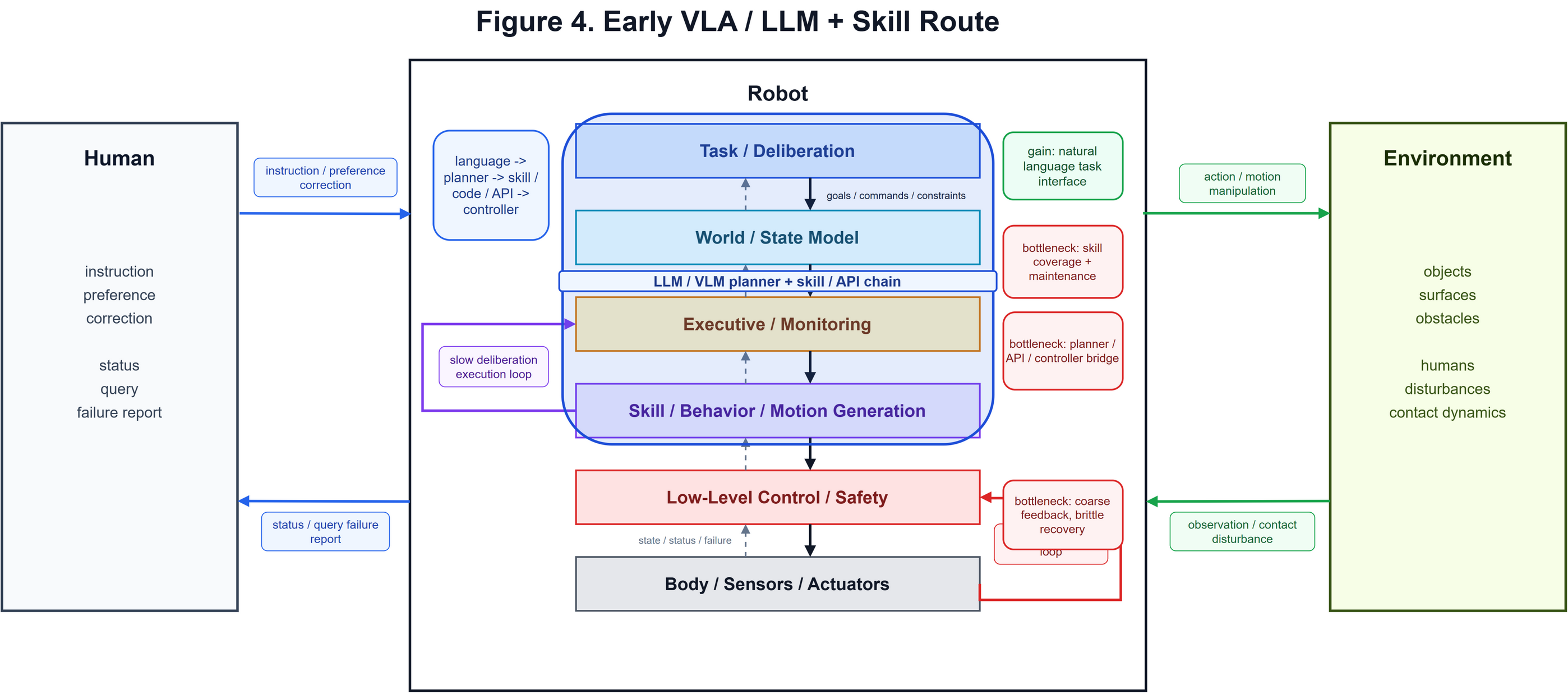
这个阶段,大家进行了非常多的探索,大致可以分为三条路线。
第一条路线是“语言规划 + skill grounding”。Language Models as Zero-Shot Planners 说明,大语言模型可以在没有额外训练的情况下,把高层任务分解成中层步骤,但这些步骤经常无法精确映射到环境允许的 admissible actions,所以论文又引入 semantic translation,把自然语言计划翻译到可执行动作集合里 [57]。SayCan 把这个问题推进到真实的机器人上:LLM 负责判断某个 skill 对完成任务是否有用,skill 对应的 value function/affordance 负责判断它在当前物理状态下是否可行,两者相乘后再选择下一步 [5]。LM-Nav 在导航任务里采用类似的模块组合:GPT-3 从自由语言里抽取 landmark,CLIP 把 landmark ground 到拓扑图节点,ViNG 负责真实机器人导航执行;这个系统不需要语言标注的机器人数据,也不需要在目标环境 fine-tuning [58]。Inner Monologue 则把成功检测、场景描述、人类反馈等信息转成语言,再放回 LLM prompt,让系统能够 retry、replan 或询问人类 [8]。这些工作共同说明,大模型已经进入机器人的任务中,人们开始探索如何把大模型的知识和机器人已有的控制能力连接起来,其中语言模型提供任务常识,机器人 skill 和 value function 提供当前场景中的执行约束。
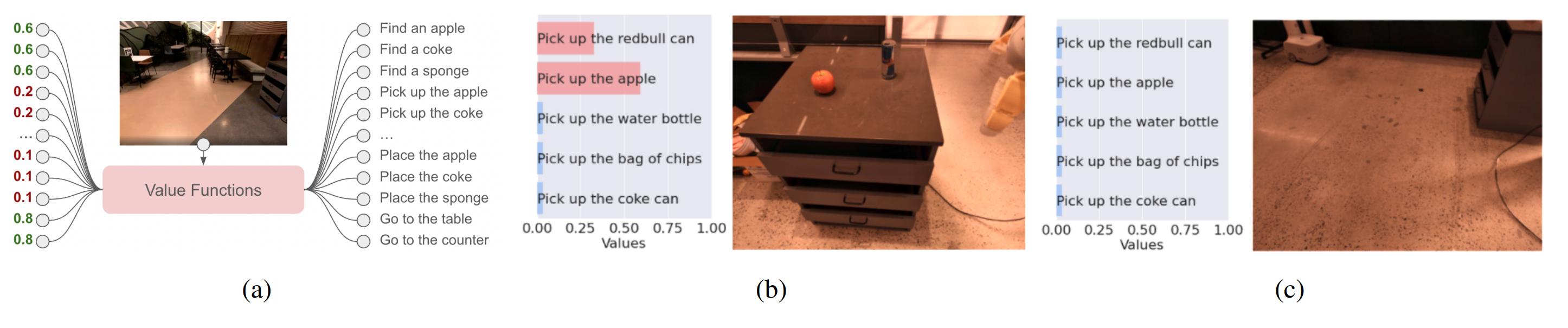
SayCan 这张图很典型:LLM 给出“这个 skill 对任务是否合理”的语义分数,value function 给出“这个 skill 在当前世界里是否可能成功”的物理分数。机器人最终执行的是 skill。然而这也要求 skill 集合必须提前存在,skill 的覆盖范围、粒度和维护成本会直接决定系统能做什么。
第二条路线是“代码/API/程序接口”。Socratic Models 提出用语言作为不同预训练模型和外部模块之间的交换媒介,把 LLM、VLM、API、数据库甚至 robot actions 组合起来做 zero-shot multimodal reasoning,其中也包含机器人感知和规划示例 [59]。Code as Policies 进一步把 LLM 的输出变成 Python policy code:模型根据自然语言指令生成程序,程序可以调用 perception APIs、control APIs,使用 if/else、for/while、几何库和递归函数,表达 reactive policies、waypoint policies 或更高层的策略逻辑 [6]。ProgPrompt 把可用 actions、objects 和示例任务组织成程序化 prompt,让 LLM 生成可执行 plan program,并通过 assertions 和 recovery actions 引入状态反馈 [60]。Language to Rewards 则把中间接口从程序动作换成 reward:LLM 将语言任务或人类修正翻译成 reward code/parameters,再由 MuJoCo MPC 实时优化低层动作 [61]。这几类方法的共同点是把大模型的生成能力约束在一个机器可解释的接口内,比如函数调用、程序代码等等。
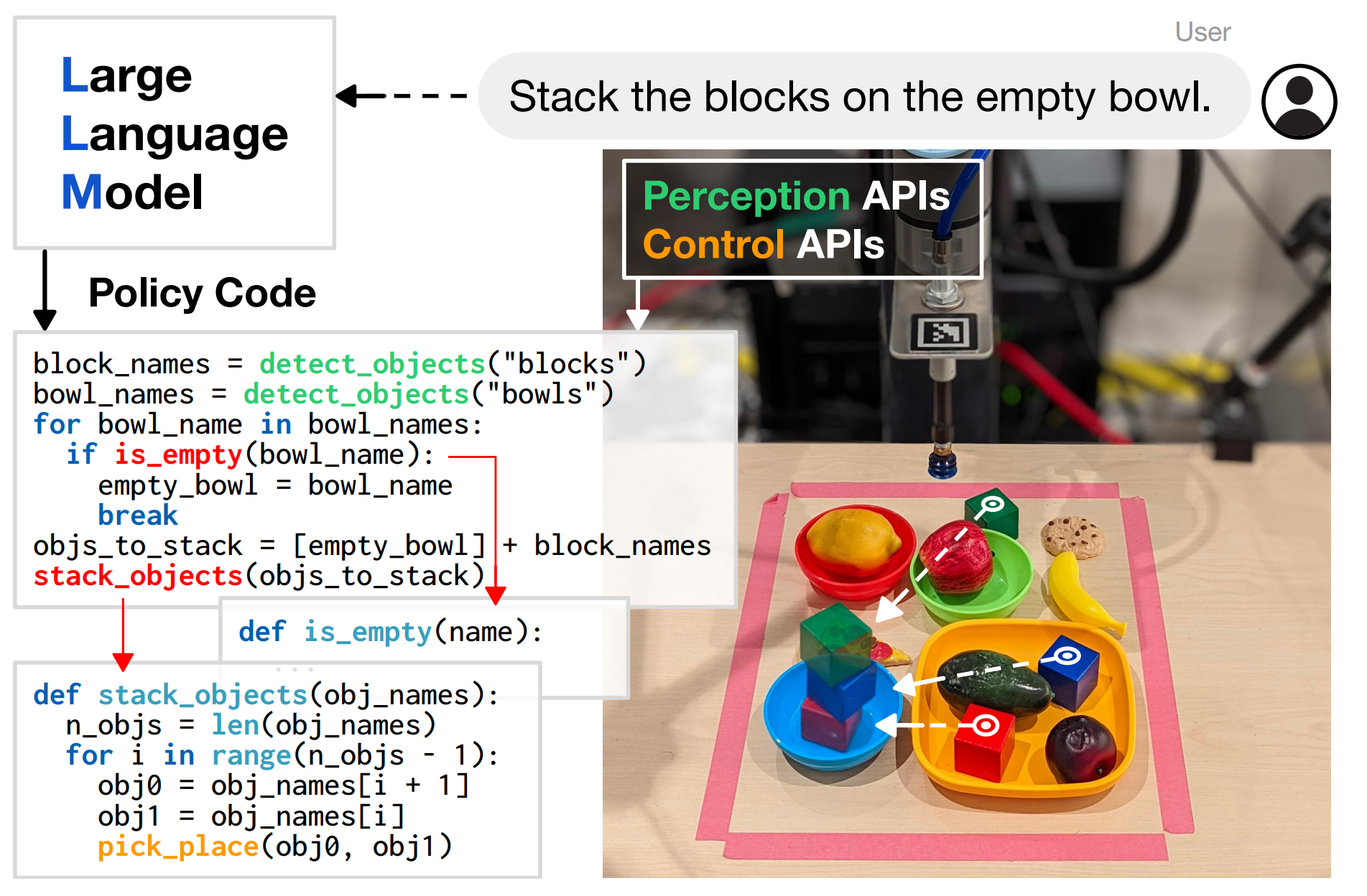
Code as Policies 的意义在于,它让 LLM 可以生成会被解释器执行的程序,比固定 skill 序列更灵活。但这种灵活性严重依赖 API 的覆盖范围,系统能够调用什么 perception/control primitive,程序就只能在这些能力上组合;如果 perception API 识别不到对象,control API 没有对应,代码写得再合理也无法落到真实动作。
第三条路线是“视觉-空间 grounding 与 multimodal prompt”。CLIPort 是一个很关键的节点,它把 CLIP 的语义先验和 Transporter 的空间精度结合起来,用 semantic pathway 处理“what”,用 spatial pathway 处理“where”,将桌面操作建模成语言条件下的 pick-and-place affordance prediction [7]。PaLM-E 把图像、连续状态估计、3D 表征等非文本输入插入到 LLM 的 token 序列中,形成 multimodal sentence,用一个模型处理 embodied reasoning、机器人规划、VQA 和 captioning 等任务 [10]。VoxPoser 则把 LLM/VLM 带到了 3D 空间:LLM 根据任务推断 affordance 和 constraint,并生成代码调用 VLM 与数组操作,把这些语义落成 3D value maps;随后 motion planner/MPC 根据 value map 合成 6-DoF end-effector waypoint 轨迹 [9]。这类工作开始把语言、视觉、空间约束和轨迹生成放到一起,从“任务怎么说”推进到“目标、约束和可行空间怎么被机器人使用”。

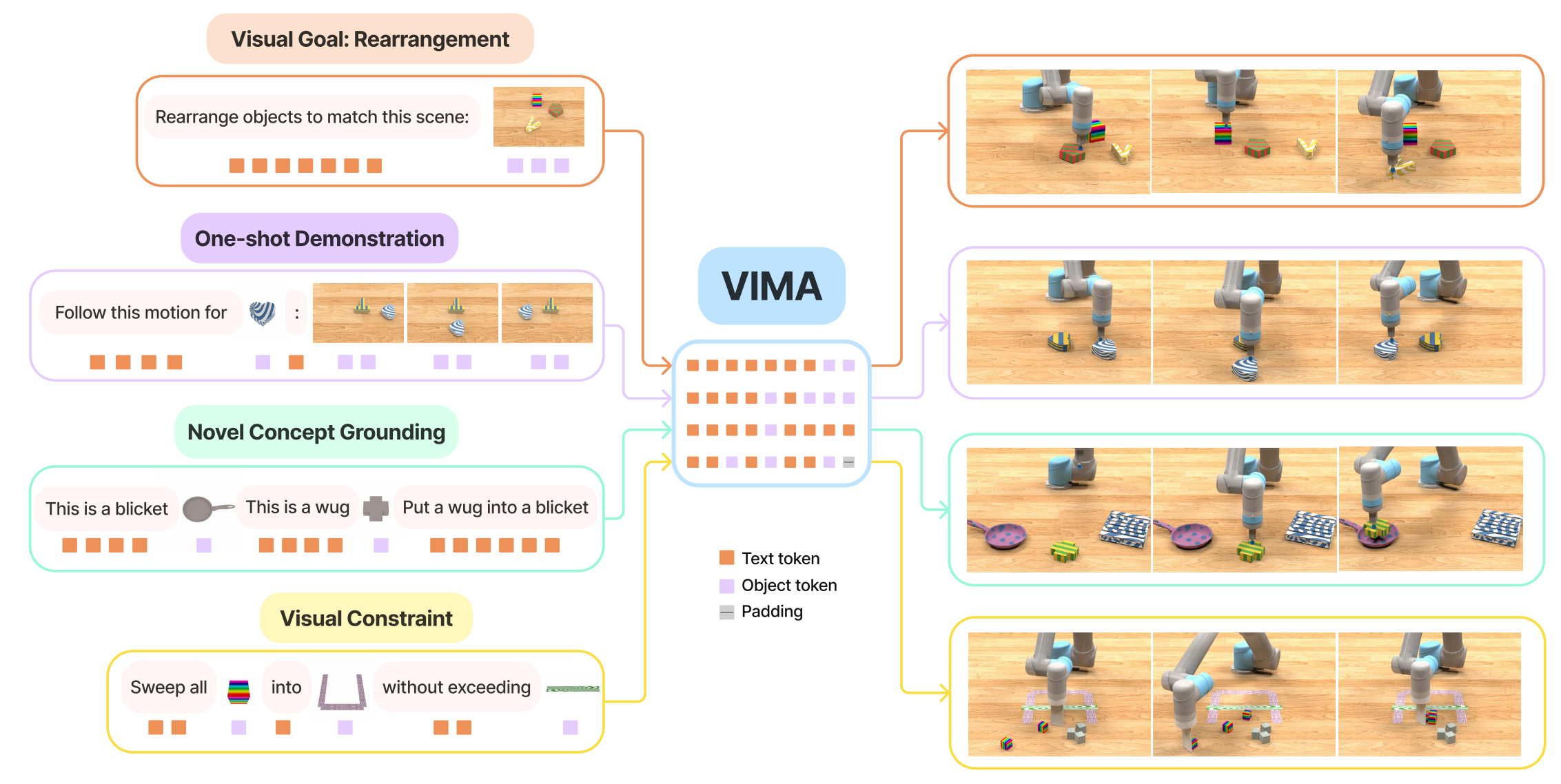
VIMA把文字、图像、视频帧交错成 multimodal prompts,用同一个 transformer agent 处理视觉目标、one-shot demonstration、新概念 grounding、视觉约束等任务,并 autoregressively 输出 motor actions [11]。VIMA把任务表达和动作生成放进同一个序列建模框架里,使多种任务规格能够共享模型和数据流程;这已经非常接近后来的 VLA 方向。它同时也说明,问题并不只是让模型“理解任务”,还要让任务表达、当前观测、动作空间、训练数据和评估协议能够共同组成一个可扩展的学习闭环。
总体来看,LLM/VLM + Skill/Code的优势非常明显。第一,它让机器人快速接入互联网规模的语言、视觉和代码先验,自然语言任务不再完全依赖手写符号规则。第二,它能复用已有机器人系统,把高层大模型能力接到 skill library、API、reward、value map、planner 和 controller 上,工程落地成本低于从零训练通用机器人策略。第三,它把机器人接口从单一任务脚本扩展到更丰富的组合形式:语言计划可以被 skill value 约束,程序可以调用 perception/control API,reward 可以被 MPC 优化,3D value map 可以指导轨迹,multimodal prompt 可以表达目标、示范和约束。
而这种方法的问题在于,它们的训练信号、执行语义、失败模式和评估方式并不统一。SayCan 的瓶颈会落到 skill 覆盖和 value function 质量上;Code as Policies 的瓶颈会落到 API 能力、程序可靠性和感知模块上;Language to Rewards 的瓶颈会落到 reward 表达和优化器上;VoxPoser 的瓶颈会落到 3D grounding、value map 组合和规划稳定性上;VIMA 则把任务表达和动作输出放进同一个模型,但仍需要明确的动作空间、数据分布和评估协议支撑。
2.4 预测 action 的时代
由于强化学习、模仿学习,以及LLM/VLM + Skill/Code等等方法的发展,机器人数据越来越多地以 observation, language/task, action, next observation 的形式组织。与其希望把分散在 skill、API、reward、value map 和 planner等等里面,不如寻找一种更容易训练、比较、部署和闭环评估的东西:action。于是,VLA、WAM等等方法出现了,VLA 试图从观测和语言直接产生可执行动作,WAM 进一步把动作和未来后果联系起来;二者都致力于解决前面一些方法没有解决的问题:让机器人行为的生成、执行、反馈和泛化进入统一的学习与评估框架。终于,我们来到了预测action的时代!
可以看看下图[62],简单区分一下VLA、WAM、WM等等名词。VLA 直接输出 action,World Model 预测下一步或未来 observation,WAM 同时关心 action 与 future observation。
这个其实不影响后续我们的讨论,本文主要是讨论“为什么现如今大家要选择去预测action”。
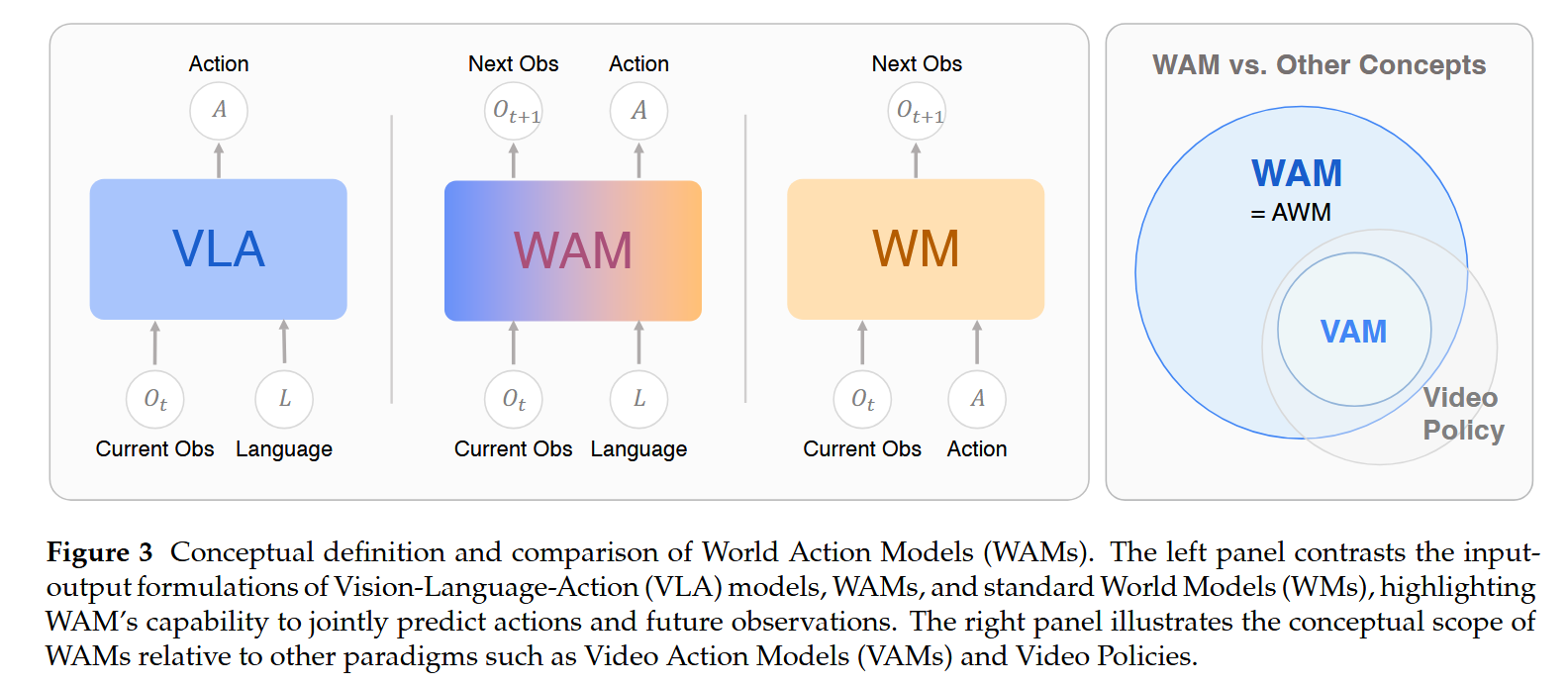
VLA:从 observation + language 到可执行动作
RT-1 应该算是第一篇VLA的工作。它把自然语言指令、相机图像和机器人动作组织成 Transformer 可以处理的序列,输出离散化的 base/arm/gripper action,并在真实机器人上以约 3 Hz 闭环运行 [12]。RT-1 的意义不只在模型结构本身,还在数据组织方式:论文使用 17 个月、13 台机器人、约 13 万条真实机器人 episode、700 多个任务的数据,证明真实机器人轨迹可以被组织成大规模 instruction-conditioned action learning 问题。它把“机器人在当前观测下应该怎样动”变成一个可训练、可评估、可部署的序列建模问题。
RT-2 进一步把 action 接进 VLM/LLM 的 token 空间。它把 robot action 表示为文本 token,和自然语言输出放在同一种训练格式中,让视觉语言模型在 web-scale 视觉语言任务和机器人轨迹上共同微调 [13]。推理时,模型生成的 action token 会被反 token 化成机器人控制量。这个设计的核心价值,是把 VLM 的语义泛化能力和机器人 action 输出接到同一个生成接口里:模型既能理解“拿起离苹果最近的物体”这类语义关系,也能把输出落到机器人可消费的动作格式。
Open X-Embodiment/RT-X 把问题从单一机器人推向跨身体数据。该数据集由 21 个机构贡献,覆盖 22 种机器人、527 类技能和 160266 个任务,并进一步整理出 100 万级真实机器人轨迹 [15]。这非常重要,因为 action prediction 要泛化,不能只依赖某一台机器人、某一个场景或某一个实验室的数据分布。OpenVLA 延续这条路线,用 Open X-Embodiment 中约 97 万条机器人 manipulation trajectory 训练 7B 开源 VLA,并在 29 个任务和多个 embodiment 上超过 RT-2-X 16.5% 绝对成功率 [17]。这些工作反映了VLA研究中存在的一些问题:多机器人数据格式、action adapter、以及把视觉语言先验转成动作输出的模型结构。
π0使用预训练 VLM backbone,并加入 action expert,通过 flow matching 生成连续动作,支持最高 50 Hz 的高频 action chunk,用于更灵巧的真实机器人任务 [18]。真实机器人执行并不总适合逐 token 生成单步离散动作。灵巧操作、双臂协作、移动操作和接触丰富任务往往需要短时间内平滑、连续、频率较高的控制片段。π0 的 action expert 把VLA从离散 action token 推到了连续 action chunk。
VLA直接、高效、可闭环部署,能复用大规模 VLM/LLM 先验,也能吸收真实机器人轨迹监督。然而VLA可能在物理一致性、长时序闭环等等问题上做的并不好。
从 World Model for VLA 到 WAM
为了解决这些问题,world model 开始以辅助模块的形式进入 VLA 学习和评估流程。它可以生成或过滤 imitation learning 轨迹,可以在 reinforcement learning 中提供 imagined interaction 和 reward-guided optimization,可以作为 reward model,也可以作为 policy evaluation 的虚拟环境 [62]。这类方法还没有把 world prediction 和 action generation 完全合成一个模型,但已经说明 world model 的价值最终要回到 action:它需要帮助选择动作、评估动作、优化动作或判断动作是否会成功。
这些工作呼应了非常早期的机器人研究:
1969年,Nils J. Nilsson[1]把这个过程分为了三步:(1) problem-solving, (2) modelling, and (3) perception。其中modelling指的是“A body of knowledge about the effects of actions is a type of model of the world.”。
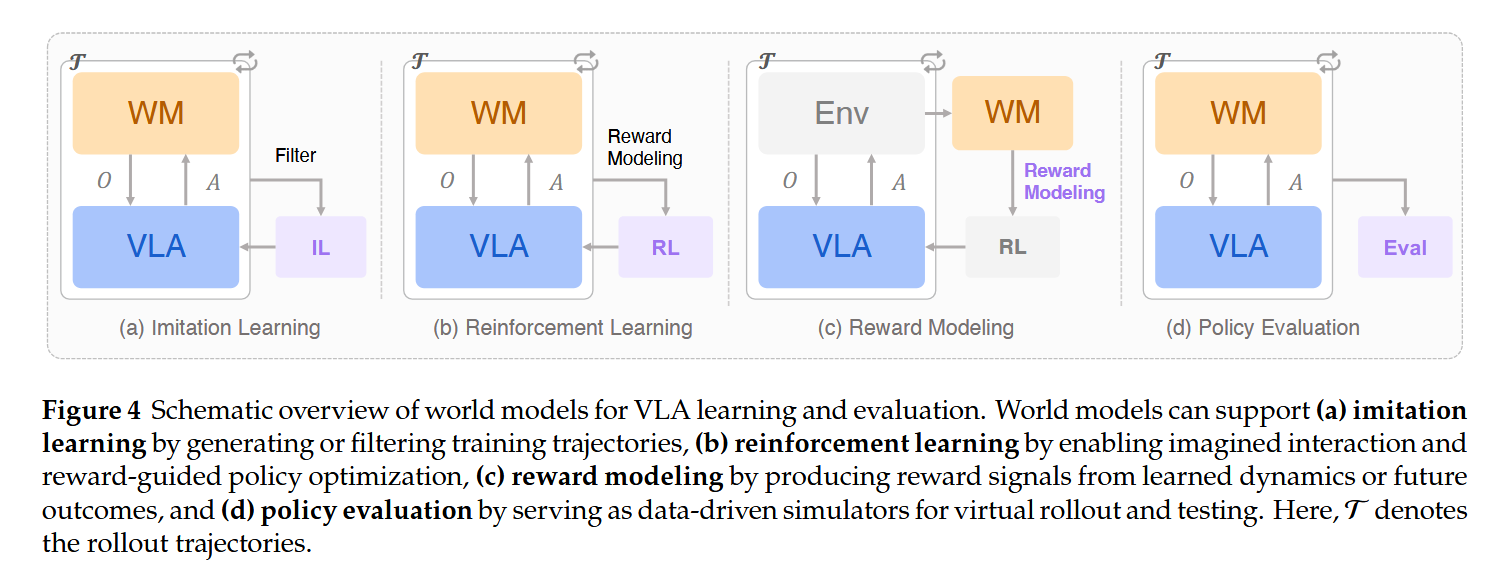
之后,人们干脆把 world prediction 和 action generation 做到了一起,即World Action Model(WAM)。最近的一篇综述把WAM 定义为统一 predictive state modeling 与 action generation 的 embodied foundation model,目标是联合建模 future states 和 actions,并把已有工作分成 cascaded WAM 与 joint WAM 两类 [62]。Cascaded WAM 更像“先预测未来,再把未来交给 action decoder”;joint WAM 更像“在同一生成过程中同时预测 future state 与 action”。二者本质上都是研究同一个问题:动作选择能否受未来后果约束。
DreamZero 是 joint video-action WAM 的代表。它基于预训练 video diffusion backbone,联合生成 future video 和 continuous actions,并通过系统优化让 14B autoregressive video diffusion model 在真机部署上达到约 7 Hz [19]。论文报告了对新任务和新环境的泛化提升,也展示了来自其他机器人或人类的 video-only demonstration 可以帮助目标机器人适应。

WorldVLA 把 image、text 和 action 分别 token 化,并让它们共享同一个 LLM 式生成框架 [63]。World model component 根据图像和动作预测未来视觉表示,action model 根据图像观测生成后续动作;论文强调二者互相增强,并报告 WorldVLA 相比独立 action model 和独立 world model 有更好的表现。它也暴露了 autoregressive action generation 的一个工程问题:连续生成 action chunk 时,早期动作误差会传播到后续动作。WorldVLA 因此提出 action attention masking,选择性屏蔽历史动作,减少 chunk 生成中的错误累积 [63]。这其实反映了WAM研究的难点:预测好未来、稳定生成action序列、避免或者减少长时序误差传播。
Fast-WAM 讨论了WAM 的收益来自推理时显式想象未来,还是来自训练时 world/video modeling 对表示的塑形?它保留 video co-training,但在测试时跳过 explicit future generation,让 video DiT 在单次前向中提供 latent world representation,再由 action DiT 生成动作 [64]。论文在 LIBERO、RoboTwin 和真实任务中报告了有竞争力的结果,同时把延迟降到约 190 ms,比已有 imagine-then-execute WAM 快 4 倍以上;更关键的是,移除 video co-training 带来的性能下降比移除测试时 future generation 更明显 [64]。
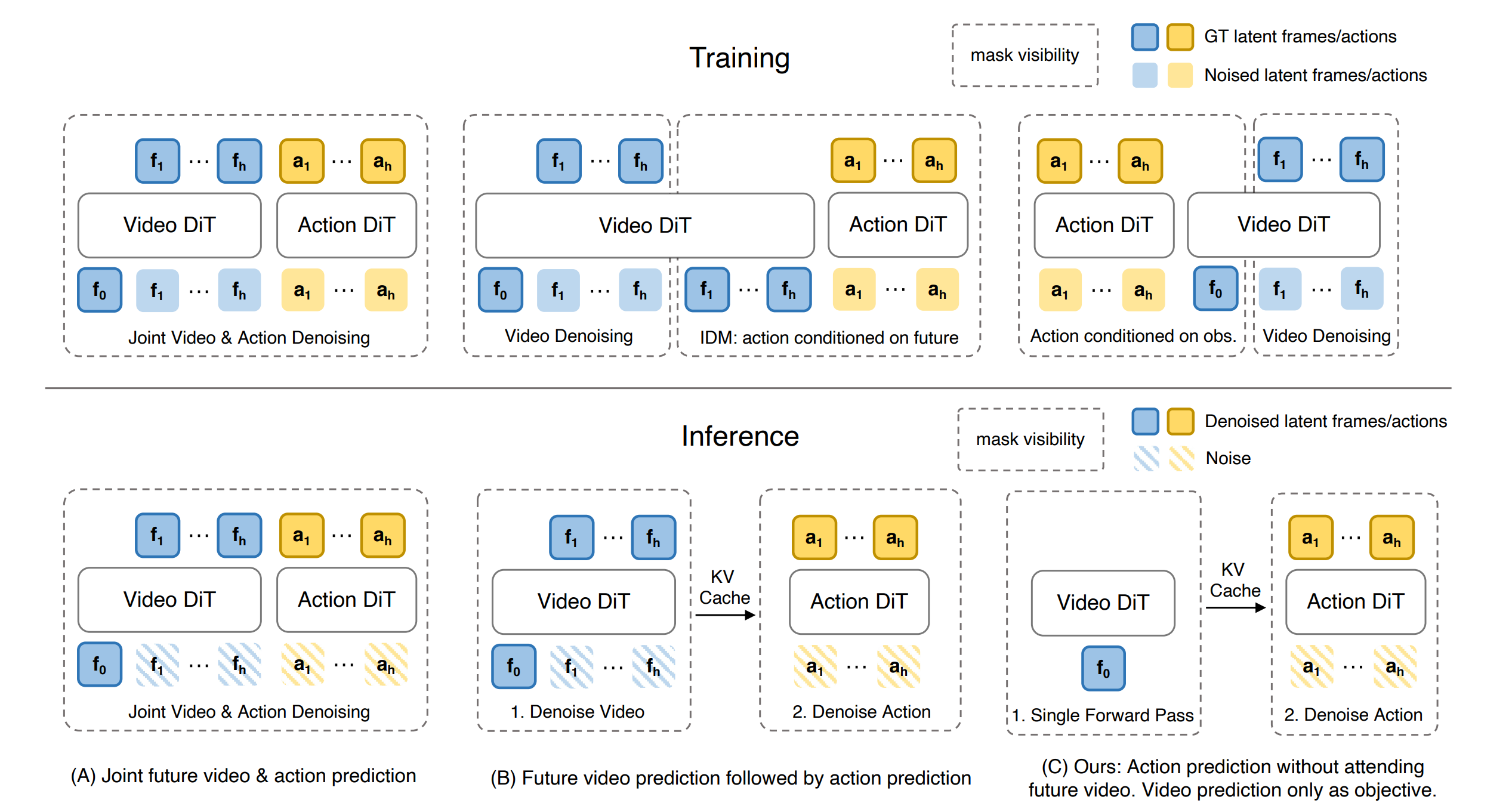
除了RGB video prediction的一些工作,VLA-JEPA 把未来帧作为 latent supervision target,学生路径只看当前观测,在 latent 空间学习 action-relevant state transition,避开逐像素预测对背景变化和相机运动的过度敏感 [65]。TesserAct 把 world state 推向 4D embodied world model:它生成 RGB、depth、normal 视频,重建 4D scene,并用更显式的几何信息支持 inverse dynamics 和 downstream policy learning [66]。3DFlowAction 则把 object-centric 3D optical flow 作为跨身体 action guidance,让模型预测物体在 3D 空间中的未来运动,再把 3D flow 作为约束求解 action chunk [67]。Cosmos Policy 进一步把预训练 video model 改造成同时生成 actions、future state images 和 value 的策略模型,并用 predicted value 做 best-of-N 规划 [68]。
3. action 是什么?
前面讨论了这么多的内容,我们其实都没有讨论action究竟是什么?
action是发给机器人某个电机的位置、速度、还是电流信号吗?所有VLA、WAM的工作预测的action都一样吗?所有带机械臂的机器人接收action之后都能做相同的操作吗?
下面我们会先解释一些名词,然后再选择一些代表性的论文和benchmark来进行解释。
注:因为我们讨论的是现如今预测action的工作(VLA、WAM),后续也主要是介绍这些工作所预测的action是什么。
3.1 常见的一些名词
codex实在是太能写了,列了这么多名词。。。我几乎都给保留下来了,有些部分稍微改了改。。。
| 名词 | 含义 | 和 action / 执行的关系 |
|---|---|---|
| End-Effector / EEF / EE | 末端执行器,通常是机械臂末端的夹爪、吸盘、工具或手爪。 | 很多 manipulation policy 直接输出 EEF 的位置、姿态、速度或增量,再由控制器转成关节运动。 |
| Pose | 位姿,包含位置和朝向。机械臂常见 6-DoF pose:x, y, z 加 roll, pitch, yaw,也可以用 quaternion、axis-angle、rotation matrix 或 6D rotation 表示。 |
EEF pose 可以作为运动目标。部署时还要明确 reference frame、单位和旋转表示。 |
| Delta Pose / Relative Action | 相对当前 pose 或当前 state 的增量,例如 EEF 向前移动 2 cm、绕某轴旋转 5 度。 | 常用于闭环策略和跨场景学习。执行后根据新 observation 再预测下一步。 |
| Joint | 机器人关节,例如肩关节、肘关节、腕关节。一个 7-DoF 机械臂有 7 个主要关节自由度。 | joint-space action 直接给 joint position、velocity、acceleration 或 torque 目标,通常更接近底层控制。 |
| Joint Position / Velocity / Torque | 关节角度、角速度和力矩。 | position control 稳定易用;velocity control 更适合速度命令;torque control 接近动力学和接触,但对模型误差、频率和安全要求更高。 |
| Cartesian Action | 在笛卡尔空间或 task space 中定义的动作,例如 EEF position、EEF orientation、EEF velocity、EEF wrench。 | 需要 IK、Jacobian、operational space control 或 motion planner 转成关节空间命令。 |
| Gripper Action | 夹爪开合命令,可以是 binary open/close,也可以是连续开度、夹爪宽度或夹持力。 | 许多 7D action 的最后一维就是 gripper。不同数据集对 open/close 的数值方向和范围可能相反。 |
| Base Command | 移动底盘命令,例如 x/y/yaw 速度、位移或目标。 |
mobile manipulation 需要同时控制机械臂、夹爪和底盘。RT-1 这类工作会把 base movement 放入 action。 |
| Skill / Option | 可调用的高层行为单元,例如 pick up the can、go to the counter、open gripper。 |
高层系统选择 skill,具体运动由 skill policy、motion planner、controller 或脚本完成。 |
| Waypoint | 路径上的中间目标点或目标位姿。 | 模型或 planner 可以输出若干 EEF waypoints,控制器再生成连续可跟踪运动。 |
| Trajectory | 一段随时间变化的位置、速度、姿态、关节参考或控制序列。 | 轨迹比 path 更接近可执行命令,因为它包含时间组织和控制参考。 |
| Controller | 把目标命令转成实际驱动信号的模块,例如 joint controller、operational space controller、PD controller、MPC、impedance controller。 | action 的可执行性取决于 controller 能否稳定、安全、实时地跟踪它。 |
| IK / Inverse Kinematics | 逆运动学,把 EEF 目标位姿转换成 joint configuration。 | 当 action 在 EEF space,而机器人接口需要 joint targets 时,IK 是常见 adapter。 |
| FK / Forward Kinematics | 正运动学,把 joint configuration 转换成 EEF pose。 | 用于从 proprioception 计算 EEF 状态,也用于相对动作、误差计算和控制反馈。 |
| Proprioception | 本体感知,包括关节角、关节速度、夹爪状态、EEF pose、力/力矩、IMU 等机器人自身状态。 | relative action、closed-loop policy 和 adapter 都需要当前 state。 |
| Action Token | 连续 action 被离散化后映射到 tokenizer 词表中的 token。 | 模型生成 token;部署时还要反 token 化和反归一化成连续控制量。 |
| Action Chunk | 一次预测多步未来动作,形状常写成 (action_horizon, action_dim)。 |
机器人执行 chunk 的前几步,再重新查询模型;适合降低推理延迟并保持短时动作连续性。 |
| Action Horizon / Prediction Horizon | 模型一次预测的未来动作步数。 | horizon 决定单次推理覆盖的时间长度。长 horizon 降低查询频率,也会降低对新观测的反应速度。 |
| Execution Horizon | 从一个 action chunk 中实际执行的步数。 | 实际系统经常预测 H 步,只执行前 s 步,再用新 observation 重规划。RTC 将这个问题写成异步 chunk 生成和 inpainting [93]。 |
| Control Frequency | 控制命令发送频率,例如 3 Hz、15 Hz、30 Hz、50 Hz 或更高。 | 同样的 delta action 在不同频率下物理含义不同。频率直接影响速度、平滑性、接触稳定性和安全边界。 |
| Reference Frame | action 所在坐标系,例如 robot base frame、world frame、camera frame、gripper frame。 | 两个同为 7D 的 action,如果 reference frame 不同,执行效果会完全不同。 |
| Normalization / De-Normalization | 训练时把 action 映射到标准范围,推理时再按数据统计量还原。 | OpenVLA 这类模型会把 action 分箱或归一化;部署必须按目标数据集/机器人统计量还原 [13]。 |
3.2 VLA 和 WAM 里预测的 action 是什么
| VLA | 机器人/环境实际收到的 action/control quantity | 维度、坐标、频率和时间组织 | 执行链路 | 模型内部如何表示/生成 |
|---|---|---|---|---|
| RT-1 [12] | arm movement、base movement、gripper opening 和 mode。arm 部分包含 x, y, z, roll, pitch, yaw, gripper opening;base 部分包含 x, y, yaw;mode 选择 arm、base 或 terminate。 |
每个连续 action 维度离散成 256 bins;真实机器人约 3 Hz 闭环执行;机器人本体是带 7-DoF arm、two-fingered gripper 和 mobile base 的 Everyday Robots 平台。 | Transformer 输出离散 action tokens;tokens 按 256-bin 反量化为 arm/base/gripper 数值和 mode;机器人每步接收 3 Hz action command,并由 mode 决定本步控制 arm、base 或结束 episode。 | 根据图像历史和语言指令自回归预测离散 action tokens;token 是连续控制量的量化编码。 |
| RT-2 [13] | 6-DoF EEF positional/rotational displacement、gripper extension 和 terminate command。 | 8 个字段:terminate Δposx Δposy Δposz Δrotx Δroty Δrotz gripper_extension;除 terminate 外的连续维度离散到 256 bins;大模型约 1-3 Hz,小模型约 5 Hz。 |
VLM 输出被约束到有效 action token vocabulary;action string 解析为 8 个 action tokens,再反量化为 EEF displacement、gripper extension 和 terminate command;机器人接收这些字段做 direct closed-loop control。 | 将 robot action 编码成自然语言 token 空间中的 token 序列,使 VLM 在 web-scale VQA 数据和机器人 trajectory 数据上共同学习 next-token prediction。 |
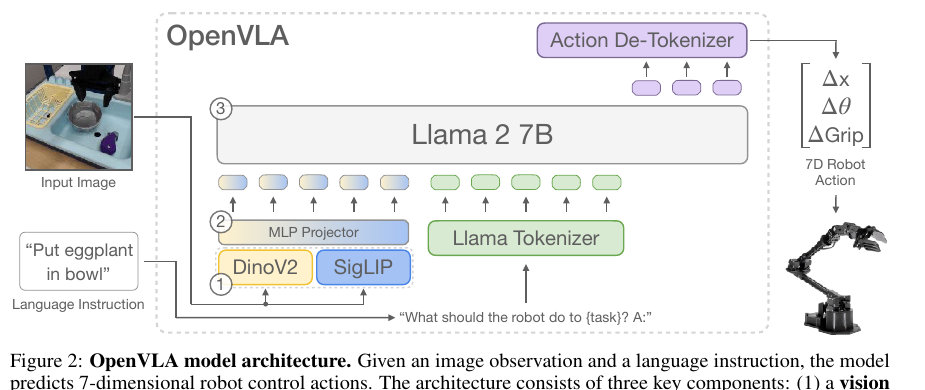
| OpenVLA [17] | single-arm 7D EEF action,包含 translation delta、rotation delta 和 gripper command。 | 每个 action 维度按训练数据 1st-99th percentile 范围离散到 256 bins;训练数据主要筛为 single-arm end-effector control;真实 Franka 评测包含 5 Hz 和 15 Hz non-blocking controllers。 | VLM 生成 action tokens;action detokenizer 将 tokens 反量化为连续 7D robot action;目标 Franka controller 每步接收 translation delta、rotation delta 和 gripper command。 | 复用 Llama tokenizer 中 256 个低频 token 表示 action bins;模型以自回归方式输出每个 action 维度的离散 token。 |
| Diffusion Policy [56] | 连续 action sequence,具体物理量由任务 action space 决定。真实 UR5 Push-T 使用 EEF-space positional command;Franka 双臂任务使用 desired EEF pose/velocity command 和 gripper command。 | 每次用最近 To 步 observation 预测 Tp 步 action,再执行前 Ta 步;真实任务常用 Tp=16、Ta=6/8;UR5 policy/demo command 为 10 Hz,机器人 EEF command 为 125 Hz;Franka learned policy/teleop 约 10 Hz,中层 controller 约 1 kHz。 |
diffusion policy 输出 Tp 步 action sequence;系统执行前 Ta 步后用新 observation 重查。UR5 将 10 Hz policy/demo command 线性插值到 125 Hz EEF-space positional command;Franka 中层 controller 将 desired EEF pose/velocity 转成 desired joint positions。 |
条件 denoising diffusion 在 robot action space 中生成整段 action sequence;模型学习 action distribution 的 denoising/score 过程。 |
| π0 / openpi [18] | 连续 action chunk;每步是 robot-specific action/config vector,可覆盖 single-arm、dual-arm、gripper、mobile base 和 vertically actuated torso 等控制维度。 | action chunk A_t=[a_t,...,a_{t+H-1}],论文任务中 H=50;action/config vector 统一 pad 到最大 18 维。UR5e 为 7D,bimanual UR5e/Trossen/ARX 为 14D,Franka 为 8D,mobile Trossen/ARX 为 16D,mobile Fibocom 为 17D;20 Hz 机器人执行 16 步后重查,50 Hz 机器人执行 25 步后重查。 |
action expert 生成 H=50 continuous chunk;部署时按时间展开为逐步 a_t,机器人在每个控制周期接收对应 embodiment 的 action vector;UR5e/Franka 执行 16 步后重查,其他 50 Hz 机器人执行 25 步后重查。 |
在预训练 VLM backbone 上加入 action expert,用 flow matching 生成连续 action chunk;zero-padding 用于统一多 embodiment 张量维度。 |
OpenVLA 的图很好地说明了 token action 的执行关系:模型输出的是 action token,真正给机器人的仍然是 7D robot action。
| WAM | 机器人/环境实际收到的 action/control quantity | 维度、坐标、频率和时间组织 | 执行链路 | 模型内部如何表示/生成 |
|---|---|---|---|---|
| DreamZero [19] | continuous action chunk;默认 action representation 使用 relative joint positions,训练中动作以 normalized action 形式进入模型。 | AgiBot G1 数据为 30 Hz、H=48;DROID/Franka 数据为 15 Hz、H=24;每个 chunk 覆盖约 1.6 秒;真实系统约 7 Hz 生成 action chunks。 |
模型生成 action chunk;chunk 经过 upsampling、Savitzky-Golay filtering 和 downsampling 平滑;motion controller 按当前时间戳执行最近调度的 relative joint-position action,同时 inference module 用最新 observation 生成下一段。 | 基于 video diffusion backbone,同步预测 future video frames 和 actions;训练中对 noisy normalized actions 做 flow-matching denoising。 |
| WorldVLA [63] | LIBERO 设置中的 7D action:3 个 relative position、3 个 relative angle、1 个 absolute gripper state。 | 每个连续 robot action 维度离散到 256 bins;每步 action 表示为 7 个 action tokens;LIBERO Long 使用 action chunk size K=10,其他 LIBERO 任务默认 K=5。 |
action model 根据 text instruction 和图像生成 K 步 action tokens;tokens 反量化为 LIBERO controller 接收的连续 7D action sequence。 |
image、text、action 都 token 化;自回归框架中同时训练 action model 和 world model,action tokenizer 将连续 action 映射到离散 token。 |
| Fast-WAM [64] | a_{1:h} 形式的 action chunk;每步 action 的物理 schema 继承 LIBERO、RoboTwin 2.0 或真实 Galaxea R1 Lite towel-folding setup。 |
主实验 action horizon h=32;真实 towel-folding 系统报告约 190 ms inference latency;LIBERO/RoboTwin/Galaxea 分别接收各自任务设置下的 action vector sequence。 |
推理时 video backbone 只处理当前 observation context,action expert 生成 h=32 action chunk;LIBERO/RoboTwin simulator 或 Galaxea robot setup 按时间消费该 chunk 中的逐步 action vector。 |
训练时对 action tokens 和 future video latents 做 joint flow matching;测试时移除 future video branch,用 world-grounded latent features 支撑 direct action generation。 |
| VLA-JEPA [65] | 7D EEF-control action:EEF delta position、delta axis-angle rotation 和 binary gripper command。论文对 joint-position-control baseline 另用 joint-space delta positions。 | action dimension 为 7,state dimension 为 8,future action horizon 为 7;EEF delta/action 和 joint delta action 做 min-max normalization 到 [0,1];gripper command 二值化为 {0,1};action head 使用 4 个 denoising timesteps。 |
latent world model 预测 action-relevant future latent state;flow-matching DiT action head 输出 future EEF action;执行时还原为 EEF delta position、delta axis-angle rotation 和 binary gripper command,LIBERO/SimplerEnv/Franka 接收这一 7D EEF action。 | Qwen3-VL、V-JEPA2 encoder 和 JEPA-style latent world model 产生 future latent supervision;action head 在 embodied action token 条件下用 flow matching 生成 EEF action trajectory。 |
| TesserAct [66] | inverse dynamics model 输出 7-DoF action;物理含义继承对应数据集/机器人 action interface,包括 RLBench Franka Panda、RT-1 Google Robot 和 Bridge WidowX。 | 先生成 RGB、depth、normal future,再重建 4D scene;action prediction 阶段过滤背景/地面并采样 8192 个 point-cloud points;PointNet 与 language embedding 送入 MLP 输出 7-DoF action。 | input image/instruction -> RGB-DN future -> 4D scene/point cloud -> inverse dynamics -> 7-DoF action;RLBench/RT-1/Bridge 对应环境接收各自 action interface 下的 7-DoF command。 | 4D world model 学习 RGB/depth/normal future 和 4D scene;inverse dynamics 用当前 state、预测 future state 和 instruction 估计 action。 |
3.3数据集里的 action
| 数据集 | 实际 action schema | 坐标、频率或 controller 信息 |
|---|---|---|
| RLBench [27] | Franka Panda manipulation benchmark 支持多种 action spaces:absolute/delta joint velocities、absolute/delta joint positions、absolute/delta joint torque、absolute/delta EEF velocities、absolute/delta EEF poses。 | observation 包含 joint angles、joint velocities、joint torques、gripper pose 和多视角 camera observations;研究者通过 action mode 选择要学习和执行的控制接口。 |
| Meta-World [78] | Sawyer 机器人 4D action:EEF 在 3D 空间中的位移变化量,加 gripper fingers 的 normalized torque command。 | action 范围为 [-1,1];50 个 manipulation tasks 共享统一 observation/action space;observation 包含 EEF、gripper openness、object position/quaternion 和 goal 等状态。 |
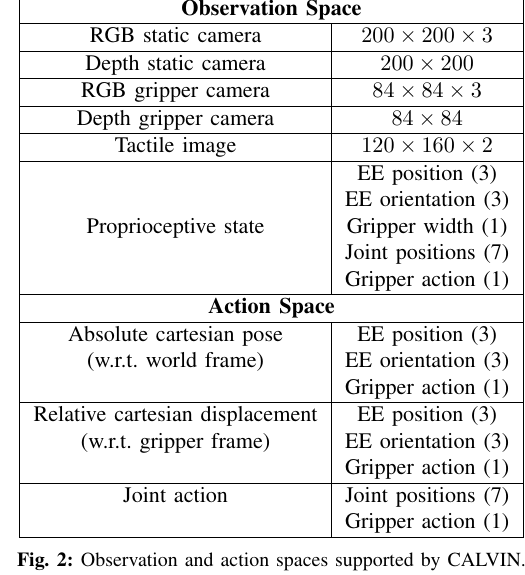
| CALVIN [26] | 支持 7D Cartesian action 和 8D joint action。Cartesian action 包含 EE position 3D、EE orientation 3D、gripper action 1D,可作为 absolute Cartesian pose 或 relative Cartesian displacement;joint action 包含 7 个 joint positions 和 1 个 gripper action。 | absolute Cartesian pose 以 world frame 为参考;relative Cartesian displacement 以 gripper frame 为参考;continuous actions 以 30 Hz 发送;baseline 常用 world-frame absolute Cartesian action。 |
| LIBERO [16] | benchmark 形式化为 finite-horizon MDP,S 和 A 分别是 robot state/action spaces;论文 baseline 通常从 GMM policy 中采样 continuous end-effector manipulation action。 |
observation 包含 perceptual observation、robot joints 和 gripper;demonstrations 由 human experts 通过 3Dconnexion SpaceMouse 采集;策略执行时从输出分布采样 continuous end-effector action。 |
| DROID [14] | 记录 equivalent robot control commands,包括 joint-space action、EEF-space action 和 continuous gripper command;policy evaluation 中常输出 absolute EEF translation、rotation 和 gripper actions。 | Franka Panda + Robotiq gripper,低层使用 Polymetis;trajectory 以 15 Hz 记录;数据包含 7D joint position/velocity、robot-base-frame EEF pose/velocity 和 1D gripper position/velocity;teleoperation 用 Meta Quest 控制 6D arm pose 和 continuous gripper。 |
| Open X-Embodiment / RT-X [15] | 跨 22 种 robot embodiments 保留异构原始 action spaces;RT-1-X/RT-2-X 将实验 mixture 中的原始 action coarsely aligned 到 7-DoF EEF action:x/y/z/roll/pitch/yaw/gripper。 |
action 坐标和语义随 robot setup 变化,可表示 absolute、relative 或 velocity;每个数据集的 action 做 normalization;推理按目标机器人需要运行在约 3-10 Hz。 |
| RoboCasa [28] | 厨房 manipulation policy 围绕 workspace end-effector control action 展开,并根据任务/机器人包含 gripper 和 mobile base 相关 command;policy observation 包含 EEF pose 和 mobile base pose。 | 基于 robosuite/RoboSuite controller 体系;simulation 中 Franka Panda + Omron mobile base 使用 Operational Space Control,控制频率 20 Hz;真实 DROID-based Franka 系统使用 DROID controller,控制频率 15 Hz;BC-Transformer 输出未来 10 个 actions 后执行第 1 个并重查,Diffusion Policy 使用 prediction horizon 16、action horizon 8。 |
| BEHAVIOR-1K [77] | 提供两类执行接口:original continuous low-level action space 用于 visuomotor control,控制 base、arm、gripper;discrete high-level action primitives 包含 navigate、pick、place、push、dip、wipe。 | action primitives 是 time-extended actions,由 sampling-based motion planner 展开为 whole-robot navigation、arm trajectory to 6D EEF pose 或 joint configuration、Cartesian line trajectory、gripper open/close;PPO baseline 输出 primitive,SAC/RL-VMC 输出 continuous low-level joint/control action。 |
CALVIN 的图直接列出 environment 中的 observation、action space 和 language goal。它说明 benchmark 本身就在塑造 action:同样是 manipulation,环境可以选择 absolute Cartesian、relative Cartesian 或 joint action。
4. 为什么偏偏是action?
其实看到这个地方,大家应该也比较清楚为什么我们要预测action,以及为什么偏偏是预测action这个量了。
第一,action数据天然存在于机器人中,比较好获取。打一个不恰当的比方,大部分人都会说话,会产生language,大部分机器人也会执行动作,会产生action。
第二,action 是机器人数据里最自然的监督信号。模仿学习和 Learning from Demonstration 长期把机器人学习写成从 demonstration 中学习 policy:给定 observation 或 state,学习专家在该状态下选择的 action [50]。
第三,预测 action 可以把机器人学习接到大模型训练范式上。RT-1 把图像、语言和动作都放进 sequence modeling 框架,模型输入图像和自然语言指令,输出离散化的 base/arm action,并在真实机器人上以约 3 Hz 执行 [12]。RT-2 更明确地把动机说成:一个端到端模型需要同时学习从 robot observations 到 actions 的映射,并利用 web-scale vision-language pretraining;为了把自然语言输出和机器人动作放进同一种格式,RT-2 把 robot actions 表示成 text tokens [13]。OpenVLA 延续这条路线,用 Open X-Embodiment 中的大规模机器人数据训练开源 VLA,让模型直接输出 robot action tokens [17]。这几篇论文的共同点是:action 变成了 foundation model 可以预测、可以 token 化、可以和视觉语言数据一起训练的目标。这样做带来了可以被scaling up的希望。正如第一点所讲的,人会产生language,而机器人会产生action,而LLM现在很成功,这样的话,预测action的大模型是否也能成功呢?这个问题非常诱人。而且action tokenization的设计看起来也很合理。
第四,预测的action更接近机器人的底层控制。之前一些研究探索的手工规则、Skill、Code或 value map 等等都可以给机器人提供信息,但它们最后被机器人执行还需要经过很多处理。而action 的优势在于它已经处在更靠近能够被执行的层级:可以是 EEF delta pose、joint target、trajectory 或 action chunk。action把模型训练目标放到了机器人“理解世界”和“真实执行”之间最关键的地方。
第五,action 数据正在成为规模化机器人学习的公共组织方式。Open X-Embodiment 汇集多机构、多机器人数据,面对的核心难点正是不同 robot embodiment 的 observation/action spaces 不一致;RT-X 的做法是把多机器人数据整理到可共同训练的格式中,让模型输出可反归一化到目标机器人的 action [15]。DROID 也把真实机器人 manipulation 数据组织成 observation、language、state 和 action logs,记录 joint-space、EEF-space 和 gripper command,使后续 policy 可以直接学习可执行行为 [14]。OpenVLA 在这些数据基础上进一步显示,大规模 robot action data 可以成为通用 VLA 预训练和下游 fine-tuning 的基础 [17]。
5. 预测 action 能够解决具身智能的问题吗?
下面是一些比较发散而且不太严谨的讨论。
简单写了些我认为VLA、WAM存在的问题,以及3D Vision存在的问题(我认为预测action和预测pose、预测depthmap是比较类似的)。简单来说,我比较倾向于认为VLA、WAM可以提供一个比较好的action prior,直接使用它们预测的action可能不是一个很好的选择。
详细来说,首先,VLA、WAM等工作,我觉得可能还存在两个比较重要的问题没有解决:
第一,action 接口本身还没有统一。比如Open X-Embodiment 汇集了 60 个数据集、22 种 robot embodiments 和 100 万级真实机器人轨迹,论文里面有提到不同机器人 observation/action spaces 差异很大[15]。这意味着,预测 action 的困难不只在网络模型的训练本身,也在机器人身体、相机坐标系、控制接口和数据采集协议上。
第二,action token 这类表示方式仍然比较脆弱。以 OpenVLA 为例,它把连续动作每维离散到 256 bins,用 Llama tokenizer 的低频 token 表示 action;它把训练数据限制到 single-arm end-effector control,并在真实 Franka setup 上评测 5 Hz 和 15 Hz controller [17]。这条路线能把 VLM 接到机器人动作上,但论文同时报告 DROID action token accuracy 学得很慢,最终从训练后段移除 DROID;它也承认当前模型只支持 single-image observation,并且推理吞吐会限制 ALOHA 这类 50 Hz 高频控制场景 [17]。也就是说,action token可能对数据清洗、action schema、推理频率和目标机器人设置都很敏感。
所以,预测 action 能提供一种粗粒度的 action prior,模型可以学到朝哪里动、什么时候抓放、怎样根据语言和视觉选择短时动作片段[56][18][19][63][64]。这个能力已经足以支撑不少桌面操作、移动操作和一部分长任务[12][18][19]。但是,它无法独自解决机器人具有“智能”这个问题。
此外,language 是 1D的,而且是Generative的,它不是自然的,自然界没有language。我们接触不到、看不见language,这一切都是非常generative的;而world 是 3D的,而且不是Generative的,如果还要加上时间,那就是4D的。这本身是一个组合上更困难的问题[94]。
而感知3D世界的方式是投影,无论生物的视觉、还是相机都是投影,这是一个物理的过程。三维视觉的一些任务里面,单目深度估计、MVS、3D Foundation Model等等其实都是对这个物理过程的学习[71][72][73][74],而VLA、WAM本质上也是学习机器人做动作这么一个物理过程[17][18][19][63][64]。我觉得二者非常相似。
比如给一组图像,VGGT会预测每一张图像的pose,而VLA可能会根据语言指令去预测机器人末端的pose,它们其实都是一个预测物理量的过程[13][17][74]。
回顾DUSt3R、VGGT、VGGT_Omega等论文[73][74][25],尤其是VGGT_Omega,似乎已经把3D Reconstruction的scaling law给证明了,depth+pose投影得到的3D Reconstruction结果确实是存在scaling law的[25],但仔细看的话,pose的实验数据没有展示完全[25]。我认为pose可能是最关键的、最底层的,因为只要有了pose,我们其实什么都有了。我认为pose可能难以被scaling up,但是这么简单类比的话,VLA、WAM应该也难以scaling up,不过我相信它们应该是有能力做到一个比较低精度的action预测的,做一个比较粗糙的执行。而后续再结合传统方法,也许这样才能解决具身的问题?
注1:本文中的框图是使用codex+drawio绘制的,如果你对这个流程感兴趣,可以看看我的GitHub仓库:
https://github.com/Immortalqx/my_codex_skills/tree/main/drawio-image2-pipeline
注2:本文中的内容主要是我先进行整理,再使用codex辅助调研得到的,有一些内容可能AI味比较重,调研主要使用的skill在:
https://github.com/Immortalqx/my_codex_skills/tree/main/research-survey-loop
以及
参考链接
[1] Nils J. Nilsson. A Mobile Automaton: An Application of Artificial Intelligence Techniques. https://ai.stanford.edu/~nilsson/OnlinePubs-Nils/PublishedPapers/mobileautomaton.pdf
[2] Richard E. Fikes and Nils J. Nilsson. STRIPS: A New Approach to the Application of Theorem Proving to Problem Solving. https://ai.stanford.edu/~nilsson/OnlinePubs-Nils/PublishedPapers/strips.pdf
[3] Rodney A. Brooks. A Robust Layered Control System for a Mobile Robot. https://people.csail.mit.edu/brooks/papers/AIM-864.pdf
[4] Rodney A. Brooks. Intelligence without Representation. https://people.csail.mit.edu/brooks/papers/representation.pdf
[5] Michael Ahn et al. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. https://arxiv.org/abs/2204.01691
[6] Jacky Liang et al. Code as Policies: Language Model Programs for Embodied Control. https://arxiv.org/abs/2209.07753
[7] Mohit Shridhar, Lucas Manuelli, and Dieter Fox. CLIPort: What and Where Pathways for Robotic Manipulation. https://arxiv.org/abs/2109.12098
[8] Wenlong Huang et al. Inner Monologue: Embodied Reasoning through Planning with Language Models. https://arxiv.org/abs/2207.05608
[9] Wenlong Huang et al. VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models. https://arxiv.org/abs/2307.05973
[10] Danny Driess et al. PaLM-E: An Embodied Multimodal Language Model. https://arxiv.org/abs/2303.03378
[11] Yunfan Jiang et al. VIMA: General Robot Manipulation with Multimodal Prompts. https://arxiv.org/abs/2210.03094
[12] Anthony Brohan et al. RT-1: Robotics Transformer for Real-World Control at Scale. https://arxiv.org/abs/2212.06817
[13] Anthony Brohan et al. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. https://arxiv.org/abs/2307.15818
[14] Alexander Khazatsky et al. DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset. https://arxiv.org/abs/2403.12945
[15] Open X-Embodiment Collaboration. Open X-Embodiment: Robotic Learning Datasets and RT-X Models. https://arxiv.org/abs/2310.08864
[16] Bo Liu et al. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. https://arxiv.org/abs/2306.03310
[17] Moo Jin Kim et al. OpenVLA: An Open-Source Vision-Language-Action Model. https://arxiv.org/abs/2406.09246
[18] Physical Intelligence et al. π0: A Vision-Language-Action Flow Model for General Robot Control. https://arxiv.org/abs/2410.24164
[19] Seonghyeon Ye et al. World Action Models are Zero-shot Policies. https://arxiv.org/abs/2602.15922
[20] Yiran Qin et al. WorldSimBench: Towards Video Generation Models as World Simulators. https://arxiv.org/abs/2410.18072
[21] Dacheng Li et al. WorldModelBench: Judging Video Generation Models As World Models. https://arxiv.org/abs/2502.20694
[22] Yaxuan Li et al. WorldEval: World Model as Real-World Robot Policies Evaluator. https://arxiv.org/abs/2505.19017
[23] Julian Quevedo et al. WorldGym: World Model as An Environment for Policy Evaluation. https://arxiv.org/abs/2506.00613
[24] Yaxuan Li et al. dWorldEval: Scalable Robotic Policy Evaluation via Discrete Diffusion World Model. https://arxiv.org/abs/2604.22152
[25] Jianyuan Wang et al. VGGT-Ω. https://arxiv.org/abs/2605.15195
[26] Oier Mees et al. CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks. https://arxiv.org/abs/2112.03227
[27] Stephen James et al. RLBench: The Robot Learning Benchmark & Learning Environment. https://arxiv.org/abs/1909.12271
[28] Soroush Nasiriany et al. RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots. https://arxiv.org/abs/2406.02523
[29] 如何理解游戏设计中的行为树和状态机? - 一杆老李的回答 - 知乎 https://www.zhihu.com/question/304808447/answer/3259345003
[30] 决策树、状态机、行为树之间的区别 - qwe qwer的文章 - 知乎 https://zhuanlan.zhihu.com/p/448895599
[31] 【许华哲再次具身创业:不想错过最大的西瓜【晚点聊 LateTalk】】 https://www.bilibili.com/video/BV1PVVF6rER7/?share_source=copy_web&vd_source=5040c17d0665f566f786d3874bbfd13d
[32] 为什么要用强化学习控制机械臂呢? - CyberSoma的回答 - 知乎 https://www.zhihu.com/question/417460012/answer/1958267849626854154
[33] Alan M. Turing, Computing Machinery and Intelligence. https://redirect.cs.umbc.edu/courses/471/papers/turing.pdf
[34] John McCarthy, Marvin L. Minsky, Nathaniel Rochester, Claude E. Shannon, A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence. https://people.csail.mit.edu/brooks/idocs/DartmouthProposal.pdf
[35] Norbert Wiener, Cybernetics: Or Control and Communication in the Animal and the Machine. https://archive.org/details/cyberneticsorcon0000wien
[36] W. Grey Walter, An Imitation of Life. https://archive.org/details/sim_scientific-american_1950-05_182_5/page/42/mode/2up
[37] W. Ross Ashby, Design for a Brain: The Origin of Adaptive Behavior. https://www.ashby.info/Ashby%20-%20Design%20for%20a%20Brain%20-%20The%20Origin%20of%20Adaptive%20Behavior.pdf
[38] Valentino Braitenberg, Vehicles: Experiments in Synthetic Psychology. https://library.agnescameron.info/artificial%20intelligence/Vehicles%2C%20Experiments%20in%20Synthetic%20Psychology%2C%20Valentino%20Braitenberg%20%281984%29.pdf
[39] Linda B. Smith, Michael Gasser, The Development of Embodied Cognition: Six Lessons from Babies. https://www.cs.indiana.edu/~gasser/papers/six-lessons.pdf
[40] Tongtong Feng, Xin Wang, Wenwu Zhu, Self-evolving Embodied AI. https://arxiv.org/abs/2602.04411
[41] Andrew G. Barto, Richard S. Sutton, and Charles W. Anderson. Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems. http://incompleteideas.net/papers/barto-sutton-anderson-83.pdf
[42] Christopher J. C. H. Watkins and Peter Dayan. Q-learning. https://www.gatsby.ucl.ac.uk/~dayan/papers/cjch.pdf
[43] Richard S. Sutton, Doina Precup, and Satinder Singh. Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning. https://people.cs.umass.edu/~barto/courses/cs687/Sutton-Precup-Singh-AIJ99.pdf
[44] Jens Kober, J. Andrew Bagnell, and Jan Peters. Reinforcement Learning in Robotics: A Survey. https://www.ri.cmu.edu/publications/reinforcement-learning-in-robotics-a-survey/
[45] Marc Peter Deisenroth and Carl Edward Rasmussen. PILCO: A Model-Based and Data-Efficient Approach to Policy Search. https://mlg.eng.cam.ac.uk/pub/pdf/DeiRas11.pdf
[46] Volodymyr Mnih et al. Human-level Control through Deep Reinforcement Learning. https://www.nature.com/articles/nature14236
[47] Timothy P. Lillicrap et al. Continuous Control with Deep Reinforcement Learning. https://arxiv.org/abs/1509.02971
[48] John Schulman et al. Proximal Policy Optimization Algorithms. https://arxiv.org/abs/1707.06347
[49] Dean A. Pomerleau. ALVINN: An Autonomous Land Vehicle in a Neural Network. https://papers.nips.cc/paper_files/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf
[50] Brenna D. Argall, Sonia Chernova, Manuela Veloso, and Brett Browning. A Survey of Robot Learning from Demonstration. https://www.cs.cmu.edu/~mmv/papers/09ras-survey.pdf
[51] Stéphane Ross, Geoffrey J. Gordon, and Drew Bagnell. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. https://proceedings.mlr.press/v15/ross11a/ross11a.pdf
[52] Pieter Abbeel and Andrew Y. Ng. Apprenticeship Learning via Inverse Reinforcement Learning. https://ai.stanford.edu/~ang/papers/icml04-apprentice.pdf
[53] Jonathan Ho and Stefano Ermon. Generative Adversarial Imitation Learning. https://arxiv.org/abs/1606.03476
[54] Chelsea Finn, Sergey Levine, and Pieter Abbeel. Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization. https://proceedings.mlr.press/v48/finn16.html
[55] Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-End Training of Deep Visuomotor Policies. https://arxiv.org/abs/1504.00702
[56] Cheng Chi et al. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. https://arxiv.org/abs/2303.04137
[57] Wenlong Huang et al. Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. https://arxiv.org/abs/2201.07207
[58] Dhruv Shah et al. LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action. https://arxiv.org/abs/2207.04429
[59] Andy Zeng et al. Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language. https://arxiv.org/abs/2204.00598
[60] Ishika Singh et al. ProgPrompt: Generating Situated Robot Task Plans using Large Language Models. https://arxiv.org/abs/2209.11302
[61] Wenhao Yu et al. Language to Rewards for Robotic Skill Synthesis. https://arxiv.org/abs/2306.08647
[62] Siyin Wang et al. World Action Models: The Next Frontier in Embodied AI. https://arxiv.org/abs/2605.12090
[63] Jun Cen et al. WorldVLA: Towards Autoregressive Action World Model. https://arxiv.org/abs/2506.21539
[64] Tianyuan Yuan et al. Fast-WAM: Do World Action Models Need Test-time Future Imagination? https://arxiv.org/abs/2603.16666
[65] Jingwen Sun et al. VLA-JEPA: Enhancing Vision-Language-Action Model with Latent World Model. https://arxiv.org/abs/2602.10098
[66] Haoyu Zhen et al. TesserAct: Learning 4D Embodied World Models. https://arxiv.org/abs/2504.20995
[67] Quanxi Wu et al. 3DFlowAction: Learning Cross-Embodiment Manipulation from 3D Flow World Model. https://arxiv.org/abs/2506.06199
[68] Bryan Zhang et al. Cosmos Policy: Learning Generalist Manipulation Policies from Pretrained World Models. https://arxiv.org/abs/2601.16163
[69] Jared Kaplan et al. Scaling Laws for Neural Language Models. https://arxiv.org/abs/2001.08361
[70] Jordan Hoffmann et al. Training Compute-Optimal Large Language Models. https://arxiv.org/abs/2203.15556
[71] Lihe Yang et al. Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data. https://arxiv.org/abs/2401.10891
[72] Lihe Yang et al. Depth Anything V2. https://arxiv.org/abs/2406.09414
[73] Shuzhe Wang et al. DUSt3R: Geometric 3D Vision Made Easy. https://arxiv.org/abs/2312.14132
[74] Jianyuan Wang et al. VGGT: Visual Geometry Grounded Transformer. https://arxiv.org/abs/2503.11651
[75] Hritik Bansal et al. VideoPhy: Evaluating Physical Commonsense for Video Generation. https://arxiv.org/abs/2406.03520
[76] Zhipeng Cai et al. VLM3: Vision Language Models Are Native 3D Learners. https://arxiv.org/abs/2605.30561
[77] Chengshu Li et al. BEHAVIOR-1K: A Benchmark for Embodied AI with 1,000 Everyday Activities and Realistic Simulation. https://arxiv.org/abs/2403.09227
[78] Tianhe Yu et al. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning. https://arxiv.org/abs/1910.10897
[79] Robert Geirhos et al. Shortcut Learning in Deep Neural Networks. https://arxiv.org/abs/2004.07780
[80] Oriane Simeoni et al. Unsupervised Object Localization: Observing the Background To Discover Objects. https://openaccess.thecvf.com/content/CVPR2023/html/Simeoni_Unsupervised_Object_Localization_Observing_the_Background_To_Discover_Objects_CVPR_2023_paper.html
[81] Lanyun Zhu et al. Addressing Background Context Bias in Few-Shot Segmentation through Iterative Modulation. https://openaccess.thecvf.com/content/CVPR2024/html/Zhu_Addressing_Background_Context_Bias_in_Few-Shot_Segmentation_through_Iterative_Modulation_CVPR_2024_paper.html
[82] Jingguo Tian et al. Pay Attention to the Foreground in Object-Centric Learning. https://openaccess.thecvf.com/content/CVPR2025/html/Tian_Pay_Attention_to_the_Foreground_in_Object-Centric_Learning_CVPR_2025_paper.html
[83] Cheng Shi and Sibei Yang. Vision Transformers Need More Than Registers. https://arxiv.org/abs/2602.22394
[84] LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries. https://arxiv.org/abs/2601.15197
[85] BPP: Long Context Robot Imitation with Semantic Keyframes. https://arxiv.org/abs/2602.15010
[86] Mechanistic Interpretability for Steering Vision-Language-Action Models. https://arxiv.org/abs/2509.00328
[87] Sparse Autoencoders Reveal Interpretable and Steerable Features in Vision-Language-Action Models. https://arxiv.org/abs/2603.19183
[88] 零基础理解 VLA 原理 3:机器人是如何生成动作的? - 机器人技术笔记的文章 - 知乎 https://zhuanlan.zhihu.com/p/2039196138125922751
[89] 港大具身智能课程/Embodied AI的 Aha-moments 1/2 - 黄奇浩的文章 - 知乎 https://zhuanlan.zhihu.com/p/2042965991836095791
[90] Embodied AI: Perception, Representation, and Action(HKU DATA8010 & ELEC8111) https://embodied-ai-hku.github.io/DATA8010/
[91] Cheng Chi et al. Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots. https://arxiv.org/abs/2402.10329
[92] Tony Z. Zhao et al. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. https://arxiv.org/abs/2304.13705
[93] Kevin Black et al. Real-Time Execution of Action Chunking Flow Policies. https://arxiv.org/abs/2506.07339
[94] Fei-Fei Li: Spatial Intelligence is the Next Frontier in AI https://youtu.be/_PioN-CpOP0?si=ma9lMZ5_gWBuvadw



