Neural Point Rendering回顾
引言
3D Gaussian Splatting这两年非常火,已经取代NeRF成为了计算机视觉、SLAM等领域的新热点,每周都能看到很多3DGS的工作出现。
笔者自己是研究3DGS SLAM的,在学习和做实验的过程中发现,3DGS作为一种显示的表示方法,其几何性质却没有那么好,与传统的点云数据相比,3DGS的点云只捕获了粗糙的几何结构,而且通常存在噪声,这导致3DGS虽然提供了显示的点云,但是在上面做配准很困难。目前笔者了解到在3DGS上做配准的工作只有《GaussReg: Fast 3D Registration with Gaussian Splatting》这一篇,具体可以看笔者的博客文章。
与3DGS相比,笔者认为Neural Point的表示方法在几何上更有优势,因此笔者选择了neural point相关的几篇工作,做一个回顾整理。
相关工作
Neural Point-Based Graphics (ECCV 2020)

如下图所示,该方法使用raw point cloud作为场景几何表示,每个点都带有一个learnable neural descriptor,这个descriptor编码了局部的几何形状和外观;之后根据相机位姿,在不同的分辨率下通过z-buffer对点云进行栅格化,得到不同分辨率下的raw images,这些raw images的像素就是对应点云的descriptor;之后把这一组不同分辨率下的raw images通过类似U-net的Rendering network,可以得到最终渲染的图像。
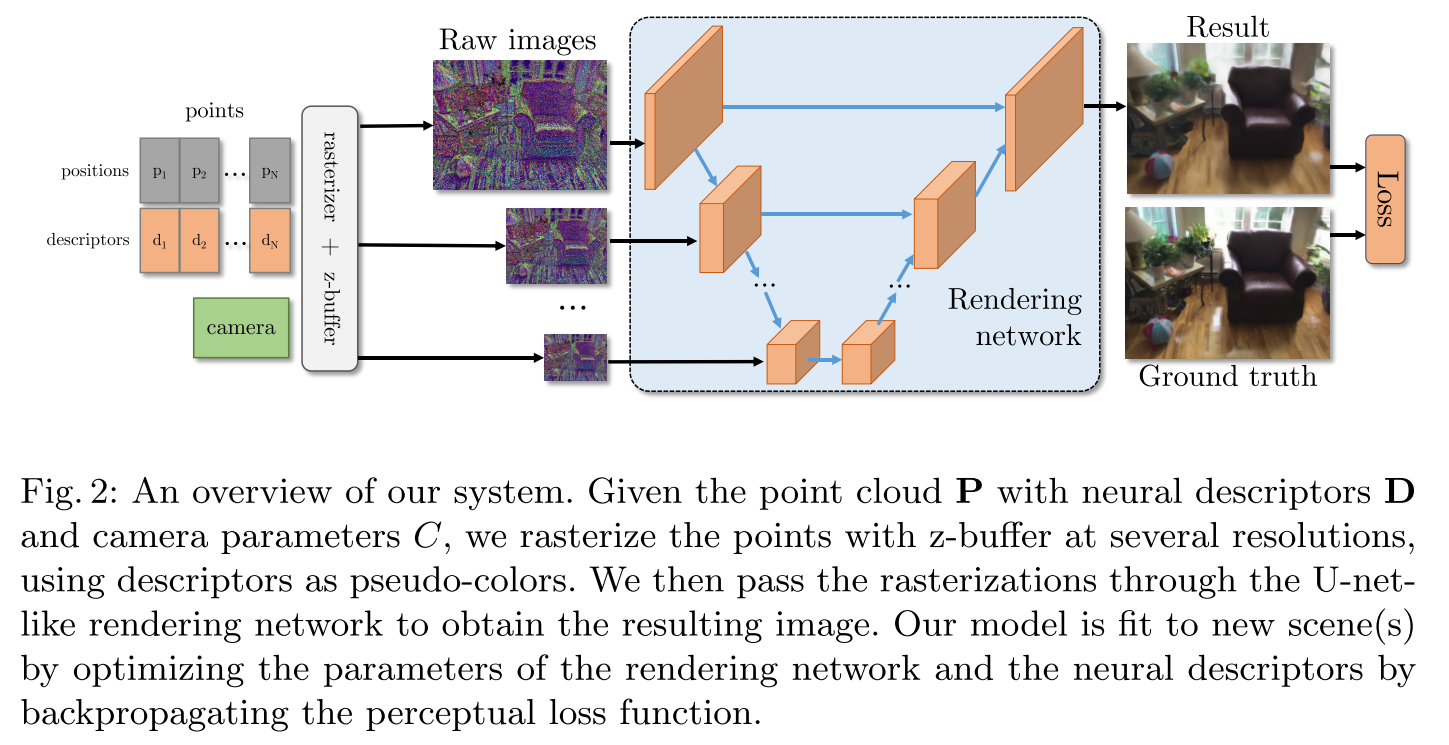
根据论文Method部分的描述,上面的具体流程为:
问题描述:
场景被表示为带有$M$维神经描述符$D = {d_1,d_2,…,d_N}$的点云$P={p_1,p_2,…,p_N}$。需要渲染在相机$C$(提供了相机位姿和内参)下的新视图,新视图具有$W \times H$的像素网格,并且viewpoint为$p_0$。
渲染过程(forward)
创建一个$M$通道、分辨率为$W \times H$的raw image,记为$S(\mathrm {P},\mathrm {D},C)$;
将场景中的点投影到目标视图上,比如对于某个点$p_i$,投影到raw image中的$(x,y)$处:
$$
S(\mathrm {P},\mathrm {D},C)[[x],[y]] = d_i
$$
由于可能存在很多点投影到相同的像素上,因此论文使用z-buffer算法来过滤被遮挡的点,只保留距离像素平面最近的那个点。但是点云缺乏拓扑信息,很容易出现孔洞,这会导致被遮挡表面的点或来自背景的点被投影到了图像上,即bleeding problem。
可以看这个链接,简单了解一下texture bleeding的现象
论文提到,传统的解决思路是通过splatting,而他们选择创建很多不同分辨率的raw image,$S[1],S[2],…S[T]$,其中对于第i张raw image,分辨率为$\frac{W}{2^t} \times \frac{H}{2^t}$。这样的话,分辨率越高的raw image,包含的细节最多,但是bleeding的问题越严重,而分辨率越低的图像,包含了粗糙的几何细节,同时bleeding的问题越轻微。
splatting?3D Gaussian Splatting启动!
话说这里的splatting是什么?也没有见它引用文献。。。
可以看看这篇文章:
Splatting 抛雪球法简介 - bo233的文章 - 知乎
https://zhuanlan.zhihu.com/p/660512916
得到不同分辨率的raw images之后,就可以通过论文的rendering network,得到最终的RGB图像了。

训练过程(backward)

论文是通过优化rendering network的参数$\theta$和神经描述符$D = {d_1,d_2,…,d_N}$来拟合场景的。
值得注意的是,论文提到rendering network的训练被分为两个阶段:第一阶段是在一组特定类型的场景上进行预训练,第二个阶段是在新场景上进行fine-tune。因此对于新场景的拟合,是fine-tune预训练好的rendering network和从头开始训练每一个点的descriptor。
实验部分
略,看原论文吧~
局限性
论文提到他们的模型不能填补较大的空洞,另外也没有研究在动态场景中的性能。
看论文中的TABLE2,每一个点的descriptor也不大,descriptor的长度和点的数量对场景的影响似乎较小。从这里看的话,这个工作渲染质量的瓶颈应该是Pipeline中的Rendering network。

Point-NeRF: Point-based Neural Radiance Fields (CVPR 2022)
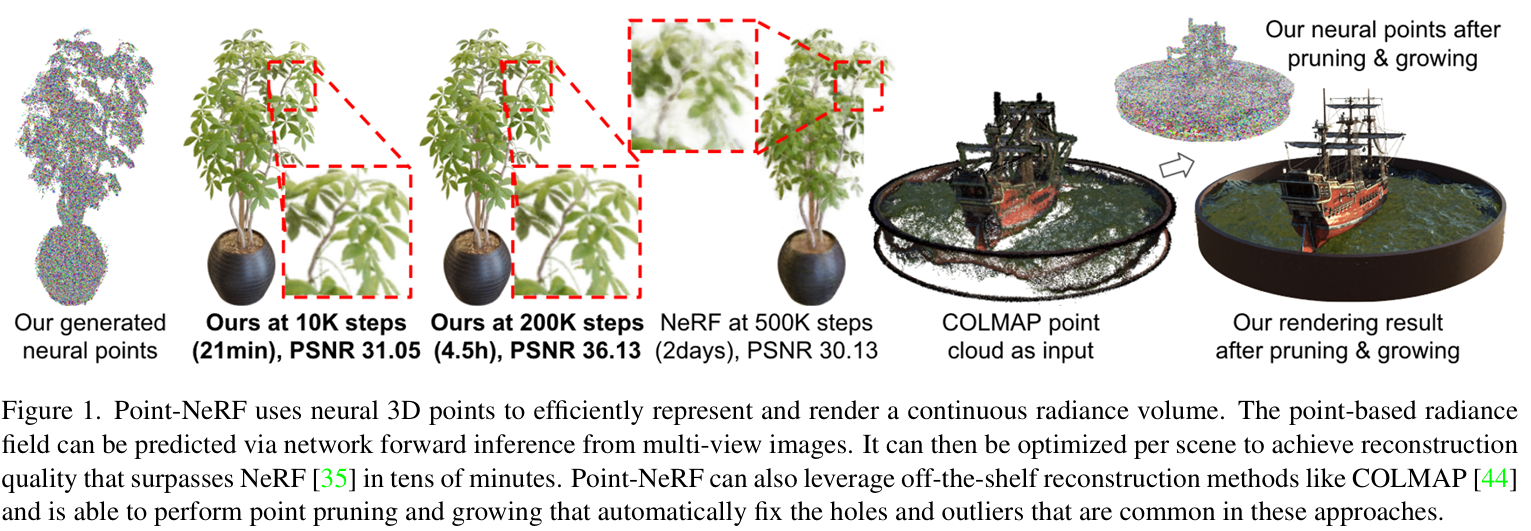
论文的Motivation:long reconstruction times due to the slow per-scene network fitting and the unnecessary sampling of vast empty space.
论文的Pipeline:
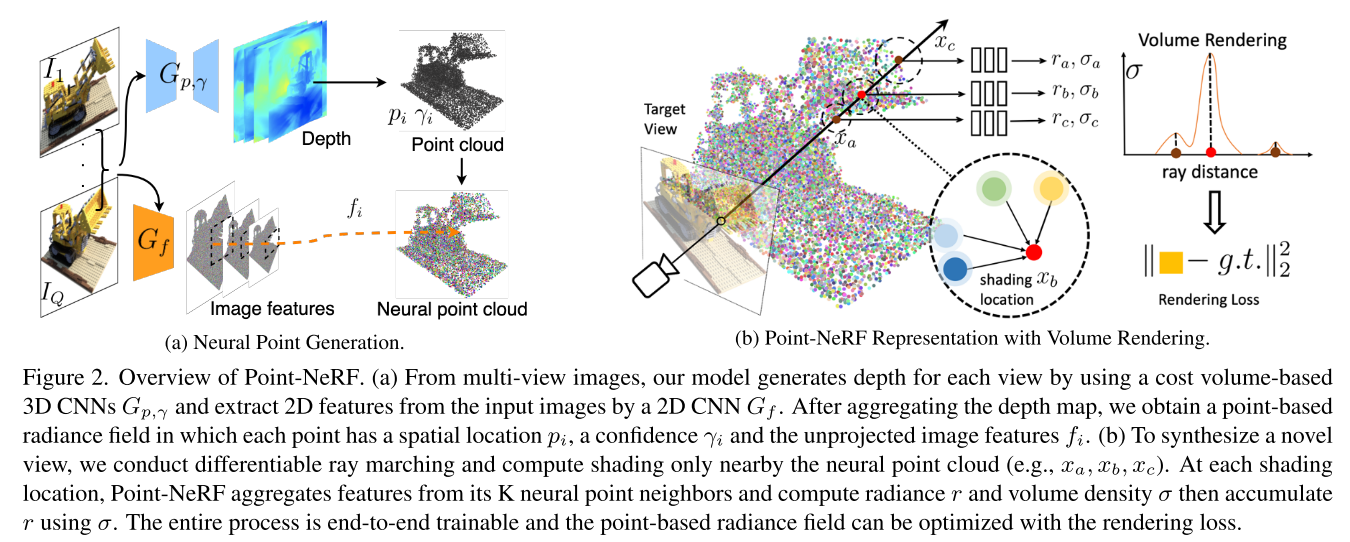
论文在这张图里把自己的工作分成了两个部分,(a) Neural Point Generation和(b) Point-NeRF Representation with Volume Rendering。不过论文是按照Point-NeRF Representation和Point-NeRF Reconstruction来讲的,下面笔者也按照论文的思路来介绍。
Point-NeRF Representation
场景表征:使用neural point cloud表示场景
$$
P = {(p_i, f_i, \gamma_i)|i = 1,…,N}
$$
对于第$i$个neural point,$p_i$表示该点的坐标,$f_i$是对应的neural feature vector,编码了局部场景的信息,$\gamma_i$是scale confidence value,表示该点位于实际场景表面附近的可能性。
对于三维空间中任意的一个点$x$,Point-NeRF会在半径$R$内查询周围$K$个相邻neural point,之后通过该点的坐标$x$、观察方向$d$和$K$个相邻的neural point,得到$x$处的volume density $\sigma$和view-dependent radiance $r$。这个过程对应的公式为:
$$
(\sigma,r) = \text{Point-NeRF}(x,d,p_1,f_1,\gamma_1,…,p_K,f_K,\gamma_K)
$$
Per-point processing:对于相邻点的neural feature vector,Point-NeRF不是直接拿过来就给位置$x$处用的,而是过了一个MLP网络$F$,相当于是根据距离加权,做一个插值,拿到插值之后的neural feature vector。
个人感觉这一步没必要,下面还有一个类似的处理。
$$
f_{i,x} = F(f_i,x-p_i)
$$
View-dependent radiance regression:Point-NeRF使用逆距离加权来得到位置$x$处的neural feature vector。

之后通过一个MLP网络$R$根据特征$f_x$和观察方向$d$回归得到位置$x$的radiance $r$。
$$
r = R(f_x,d)
$$
Density regression:和上面的过程类似,不过是先计算每个相邻点的体密度,再通过逆距离加权来得到最终的体密度。
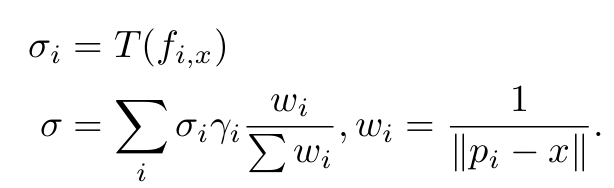
Point-NeRF Reconstruction
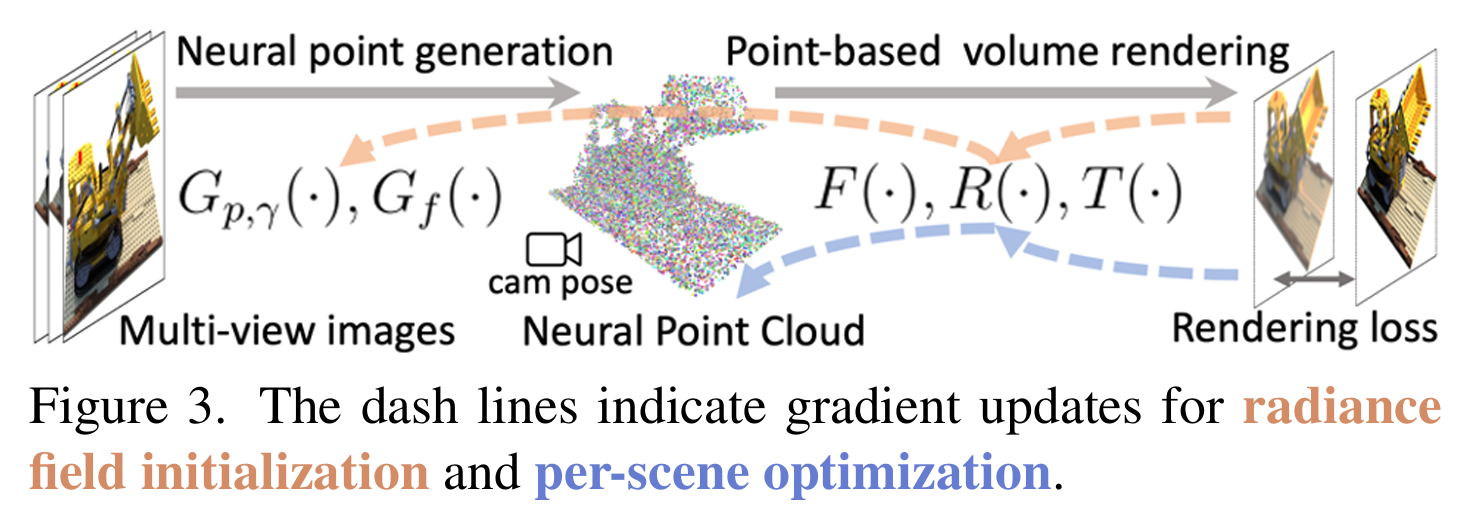
初始化:Generating initial point-based radiance fields
论文提到完全从头开始训练随机初始化的neural feature和MLP可能会非常慢,因此他们设计了这个初始化的模块。这里放一个哔哩哔哩UP主意の茗的总结:

优化:Optimizing point-based radiance fields
论文在这里提到初始的点云,特别是其他重建方法的点云(比如Metashape或者COLMAP等方法),通常会包含孔洞和异常值,为了解决这个问题,Point-NeRF尝试过直接优化现有点的位置,但是发现这样会导致训练不稳定。因此最终的解决思路是:设计新颖的point pruning和point growing策略。
3DGS优化了点的位置欸
Point pruning
每个neural point都保存了自己的置信度$\gamma$,这个置信度表示该点是否靠近场景的表面。Point-NeRF利用这些置信度来修剪异常点,置信度低说明该点附近的区域可能是空的。因此Point-NeRF每10k次迭代就修剪掉那些$\gamma < 0.1$的点。
针对每个点的置信度,论文设计了一个sparsity loss,这个损失函数会强迫每个点的置信度接近0或1。

论文作者认为这种剪枝技术可以去除异常点,减少相应的伪影。
Point growing
Point growing的目的是在不存在点的空白区域恢复信息,核心思路是逐步增长在点云边界附近的点。
具体的思路是,把每次沿着射线采样的点作为新的候选点,计算这条射线不透明度最高的位置$x_{jg}$,以及该位置到最近neural point的距离。

如果不透明度$\alpha_j$和最近neural point的距离都大于设定的阈值,就说明位置$x_{jg}$位于场景的表面附近,但是这个位置附近又缺少neural point,Point-NeRF就会在位置$x_{jg}$新增一个neural point。
通过重复这种生长策略,Point-NeRF可以逐渐扩展并覆盖初始点云中缺失的区域,比如下图这种比较极端的情况,也可以通过该策略逐步增长新的neural point,从而覆盖整个物体表面。

实验部分
只写几个个人感兴趣的实验,其他部分看原论文吧~
Table 1这里可以发现,Point-NeRF初始化之后就有了一个不错的结果,而经过一段时间的优化之后,各项指标都很突出。
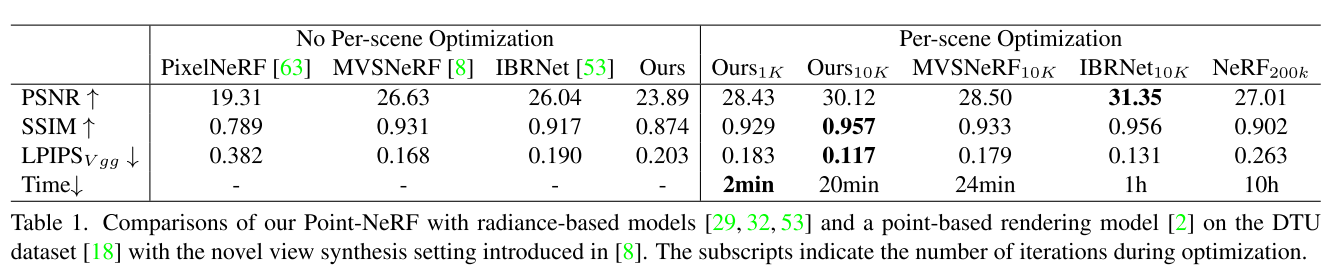
论文的Table 4还对比了点云点修剪和生长的效果,并且展示了在Point-NeRF初始化的点和COLMAP提供的点上的效果。可以看到点云修建和生长策略可以给各项指标带来很大的提升,而且使用Point-NeRF初始化的上限比COLMAP要更高
也许因为本质上还是走的体渲染流程,初始化的点全部在表面上,采样不了几个点,所以论文P&G其实主要是在物体内部疯狂生成新的点?或者在表面附近生成很多个点?

局限性
查询MLP的次数和原版NeRF差不多,渲染速度上没有提升
点云密度和渲染质量之间需要平衡,大场景重建可能会比较吃力
- 点云密度高,显存占用增加
- 降低点云密度,会降低渲染质量
INPC: Implicit Neural Point Clouds for Radiance Field Rendering
2024年3月25日,在3D Gaussian Splatting浪潮席卷下,一篇Neural Point相关的工作被挂在了arxiv上~
都年底了,这篇文章怎么还没中稿?

论文的Motivation:当前新视角生成的研究主要分为了两个方向,一个是implicit radiance fields的方法,一个是explicit point-based的方法。然而前者依赖intensive ray-marching,后者则需要a-priori point proxies。对此论文希望创建一种新的场景表示方法,结合这两种方法的优点,同时绕过ray-marching和explicit priors。
看起来是在尝试结合3DGS和Zip-NeRF,原论文是这么说的:
More specifically, we take inspiration from current state-of-the-art approaches 3D Gaussian Splatting and Zip-NeRF: We decompose and optimize a scene into two parts, which constitutes a concept that we dub implicit point cloud.
论文对Zip-NeRF的评价:The current state-of-the-art in this field, Zip-NeRF, combines ideas from both quality and efficiency directions: It augments the underlying gridbased data structure with anti-aliasing through conical sampling, the addition of scaling information, and refined empty space skipping. While Zip-NeRF is comparably fast in training (taking about 5 hours), the rendering speed for novel views is limited to ∼ 0.2 fps on consumer-grade hardware. This approach is closest in mind to our method, as we also recombine grid-based appearance information with implicit density formulation for scene reconstruction. In contrast to Zip-NeRF, however, our method enables rasterization-based rendering, making it faster in inference.
论文对3DGS的评价:Especially important here is 3D Gaussian Splatting (3DGS) which extends point rendering with anisotropic 3D Gaussians as a radiance field rendering paradigm. Apart from removing the need for a CNN to fill holes, this formulation allows them to start with a sparser point cloud that is densified by repeatedly splitting large Gaussians during the optimization.
论文的Pipeline:
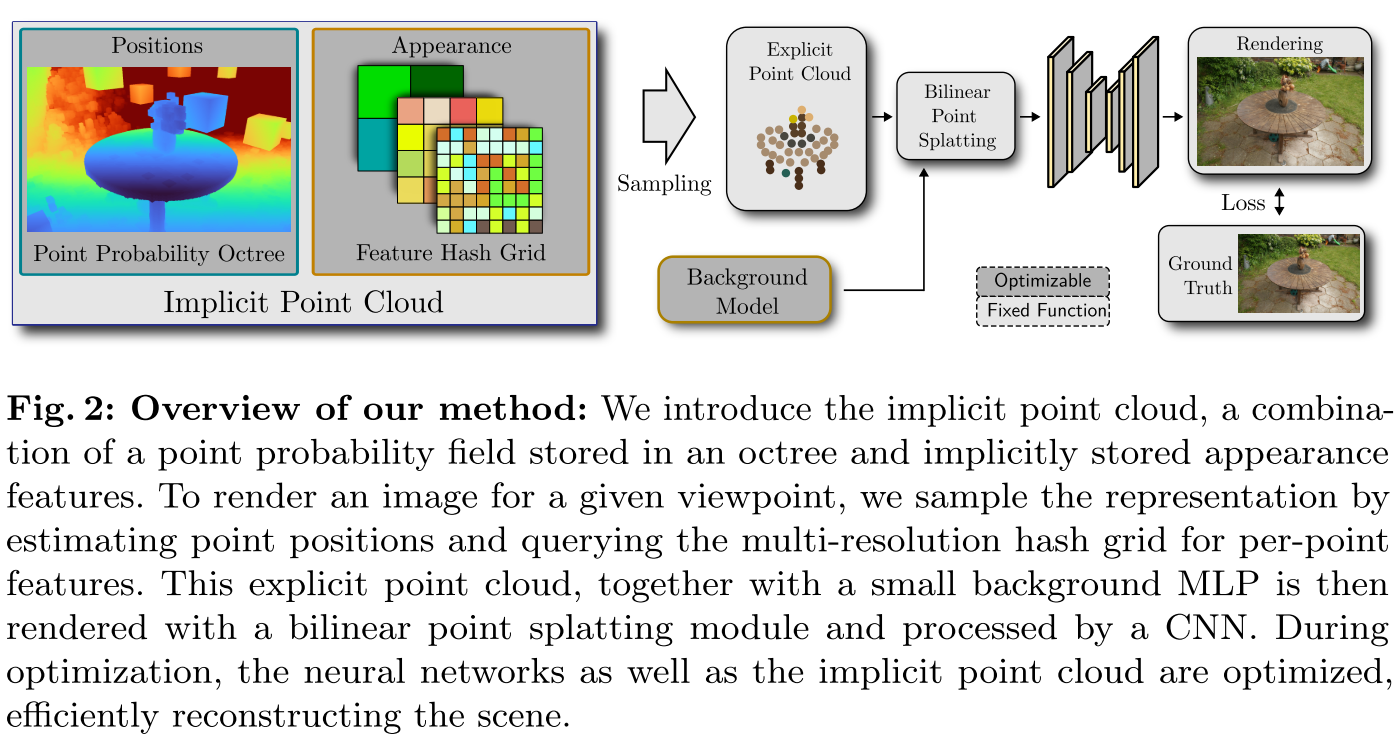
与上面的两个工作不同,INPC的neural point是隐式的,点的位置被保存在基于八叉树的概率场中,点的外观(颜色、特征、不透明度)被保存在类似于instant-ngp的neural field中。
对于某个给定的视角,INPC会对Implicit Point Cloud进行采样,得到显示的点云(位置和特征向量),之后通过Bilinear Point Splatting得到多分辨率的2D feature map,再和Background Model的输出进行$\alpha$-blending,最后通过U-Net结构的渲染网络渲染得到该视角下的图像。
Neural Point-Based Graphics是创建很多不同分辨率的raw image,不使用splatting。
这个工作怎么又splatting,又多分辨率?
Sparse Point Probability Octree
作者在这部分开头又提到,现有的NeRF方法不需要明确的几何形状,相比之下基于点的方法在优化过程中需要长期保存显示的点云。之后又重申了本工作的一个目标是,在point-based neural rendering pipeline中消除对长期保存显示点云的需求。
质疑:看到这里仍然不理解为什么作者的目标是”One goal of this work is removing the need for a persistent set of point positions within a typical point-based neural rendering pipeline.“
这个工作似乎在追求完全隐式的场景表示方法,感觉有点极端了。这样有什么优势呢?这篇论文并没有多少篇幅进行介绍,而且也没有说清楚explicit point-based的方法需要a-priori point proxies为什么是不好的。
也许这样可以避免point-nerf、3DGS需要的致密化?这是笔者唯一能想到的一个点了,显示的方法需要明确某个地方有多少个点,点的数量或者密度会影响最后渲染的结果,点的数量过多会导致显存占用上升。
初始化:使用3D体素网格初始化概率场,稀疏八叉树的初始叶节点概率设置为1。也可以将点云作为先验来计算初始叶节点的概率。
概率更新:叶节点的概率表示相对于其他的叶节点,场景几何占据它体积的多少。论文对此设计了一种更新策略,通过如下的公式更新所有叶节点的概率。
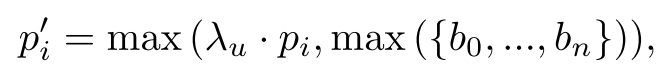
其中${b_0,…,b_n}$是使用第$i$个叶节点生成的所有点的$\alpha \text{-blending}$权重的集合,而$\lambda_u$是超参数,论文设置为0.9968。
叶节点细分:上面的概率更新公式,会使得只有一部分被场景占据的叶子节点获得比较高的概率。论文的策略是对概率大于设定阈值的所有叶节点进行细分,并且叶子节点总数不能超过$256^3$。
剪枝:通过上面的概率更新公式,没有覆盖到场景的叶子节点概率会指数衰减到0,删除小于指定阈值的叶子节点即可实现剪枝。
Point Sampling Strategies
该部分的核心思路是对Sparse Point Probability Octree进行采样,论文设计了两种采样策略:基于特定视角的采样方案(Viewpoint-Specific Sampling)和独立于视角的采样方案(Viewpoint-Independent Sampling)。对于训练,可以生成特定视角下的点云;而全局的、独立于视角的点云可以增加时间稳定性和渲染的性能,不需要对隐式的点云进行逐帧采样。
Viewpoint-Specific Sampling:针对特定视角的加权方案主要考虑以下三点:1)不能在相机视锥体外采样;2)远离相机的区域少采样;3)具有较高细分级别的叶子,即代表较小体积的叶子,需要少采样。对应的公式如下:

其中$\mathbb{1}_{visible}$是一个指示函数,可见叶子节点返回1,不可见叶子节点返回0。$\lambda_l$表示应该采样多少较小的体素,论文设置为0.5,$d_i$表示叶子中心到图像平面之间的距离。
Viewpoint-Independent Sampling:作者观察到在推理的过程中,点云采样占用了一半以上的时间,因此作者希望为所有的视角预先提取一个全局点云。这里仍然是使用上面Viewpoint-Specific Sampling的公式,不过忽略了$\mathbb{1}_{visible}$和$d_i$。
Appearance Representation
采样之后,对于每个点,从多分辨率哈希网格中检索$M+1$个appearance feature,第一个feature会被转换为不透明度:
$$
\alpha_h = 1 - e^{-e^x}
$$
剩下的M个feature会用来计算球谐系数。
对于background model,论文使用了一个小型MLP,使用相应的sh编码的观看方向作为输入,计算每个像素的4D特征。
Differentiable Bilinear Point Splatting
论文提到之前关于point rasterization的工作(包括3DGS)可以证明,对辐射场的点渲染可以非常迅速,但是单像素点渲染(将多个点投影并离散到一个像素)会导致混叠,并且需要近似梯度。
为了避免这个情况,论文使用双线性公式,在投影之后将每个点与其最近的$2\times2$个相邻点相接。对于采样点$p_w = (x,y,z)^T$,将其投影到图像坐标$p=(u,v,d)^T$中:
$$
p = P \cdot V \cdot p_w
$$
其中$P$是相机内参,$V$是相机外参。对于最接近的$2 \times 2$像素点$p_{i \in {0…3}} = (u_i,v_i)^T$,通过如下公式计算不透明度:
$$
\alpha = \alpha_h \cdot (1 - |u-u_i|) \cdot (1 - |v - v_i|)
$$
这种方法可以让每个点能根据它们投影的位置被正确加权。
这种双线性喷溅方法有三个优点:(1)可以获得更鲁棒的梯度,(2)提高渲染的时间稳定性,(3)栅格化后的图像包含的孔洞更少,这使得填充孔洞的CNN工作更容易。
Post-Processing & Optimization Loss
这篇工作使用U-Net架构的网络进行解码,得到最终渲染的图像。
受到Plenoptic-points和3DGS的启发,这篇工作结合了逐像素损失和两个图像控件的损失函数:
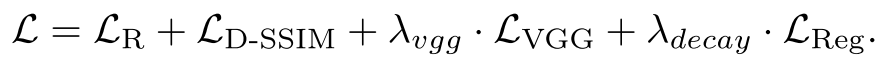
实验部分
只写几个个人感兴趣的实验,其他部分看原论文吧~
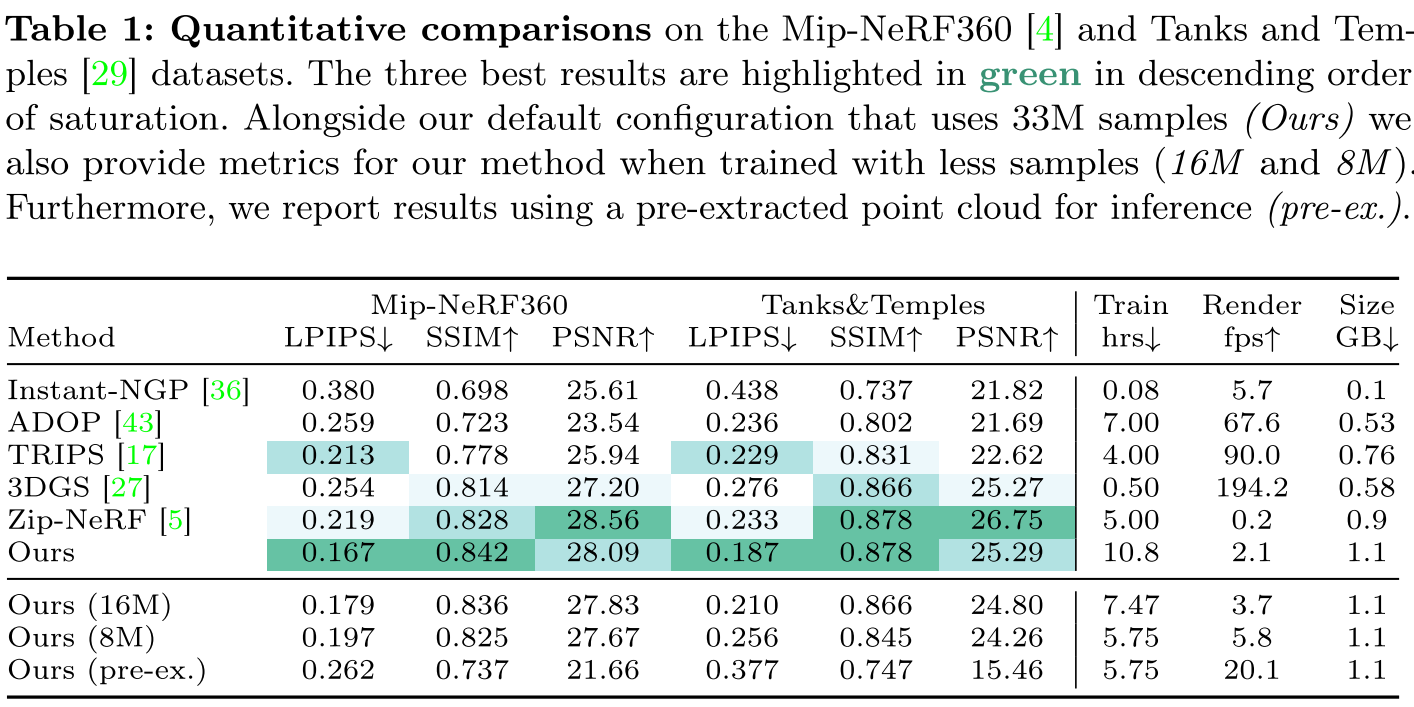
论文在Mip-NeRF360和Tanks&Temples数据集上与多种方法进行了定量对比,在渲染质量上,这篇工作是比较有竞争力的。这里也放出了训练时间、渲染速度和存储占用的情况,在这三个点上,这篇工作表现得不太好。
论文消融实验的结果如下所示。对于”G) No SfM Prior”,对LPIPS、SSIM、PSNR这三项指标的影响不是很大,说明这篇工作不需要初始点云也可以work,这里还是挺不错的。

局限性
如论文Fig5所示,这篇工作在相机附近缺乏更精细的几何细节,并且在高光度变化的数据集上表现较差。

总结&讨论
本文回顾了Neural Point Rendering相关的几篇工作。
其中Neural Point-Based Graphics和INPC都是将场景中的neural point投影到新视角的图像平面上,得到多分辨率的feature map,之后通过U-Net解码得到最终渲染的图像。投影的过程和3DGS很类似,渲染质量的瓶颈主要在于U-Net网络,neural point特征向量的维度对渲染质量的影响较小。
而Point-NeRF结合了传统点云和NeRF的优点,通过neural point表示场景,避免对空白区域的采样。渲染质量主要取决于点云密度。
参考资料
【论文讲解】Point-NeRF:用点云做NeRF重建,既抽象又具体,既新奇又传统(2022 CVPR Oral)
【论文讲解】用点云结合3D高斯构建辐射场,成为快速训练、实时渲染的新SOTA!
day4:Z-buffering(深度缓冲)
https://supercodepower.com/docs/toy-renderer/day4-Z-buffering
How to avoid texture bleeding in a texture atlas?
https://gamedev.stackexchange.com/questions/46963/how-to-avoid-texture-bleeding-in-a-texture-atlas
Splatting 抛雪球法简介 - bo233的文章 - 知乎
https://zhuanlan.zhihu.com/p/660512916
注:本文是笔者学习研究过程中的思考整理,如有错误疏漏,请各路大佬批评斧正!



