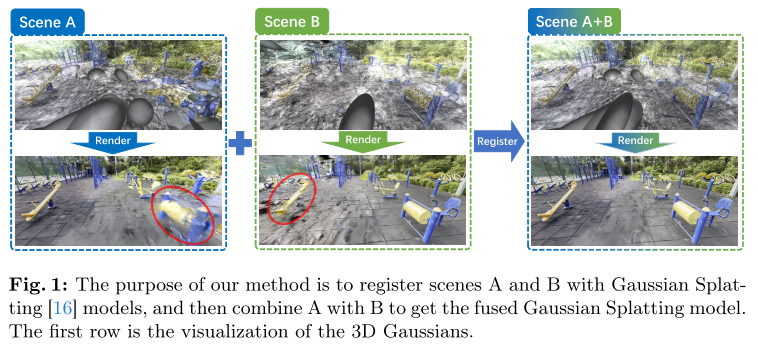
论文阅读《GaussReg: Fast 3D Registration with Gaussian Splatting》
ECCV 2024,第一篇做3DGS配准的工作
Abstract & Introduction
论文提到NeRF在大规模场景重建时的问题:
在考虑基于NeRF的大规模场景重建时,主要面临两个挑战:
- 1)由于现实场景中存在复杂的遮挡,通常需要捕获大量图像或视频进行大规模重建,导致数据收集过程耗时。
- 2)使用大量图像优化NeRF是计算密集型的。
一种直接的方法是将一个大尺度的场景分成几个较小的场景,分别重建,然后用配准将这些小场景组合在一起。
而考虑两个重叠的场景,每个场景都有自己的NeRF模型,根据目前已有的工作,可以分成两种方法:
NeRFuser,渲染图象,再重新跑SfM。这种方法的问题是,耗时过高。
好直白的思路,这也能发paper?
Dreg-NeRF,转成显示的体素,提取特征进行匹配。这种方法的问题有两个:
a)难以将无界场景的NeRF转换为有界体素;
b)体素网格的分辨率限制使得该方法不适合较大的场景。
论文提到了一个有趣的问题:As GS provides a point-like representation, can we conduct GS registration resorting to point-cloud registration methods? 既然GS提供了点云表示,那么我们是否可以借助点云配准方法进行GS配准?
鄙人也很早就考虑到了,这是一个非常有趣的问题,但是很棘手,不好解决。
论文对3DGS点云的评价:
Compared with traditionally collected point cloud data, point clouds from GS only capture rough geometric structure and are usually noisy.
是的是的!与传统采集的点云数据相比,3DGS采集的点云只捕获了粗糙的几何结构,而且通常存在噪声。
除此之外,3DGS采集的点云太过稠密了,存在冗余,但是又从图像渲染的结果来看,其实还存在密度不足的情况。
因此,如果想用简单一些的点云配准方法来配准3DGS,可以做的事情有:
- 让3DGS捕获更好的几何结构;
- 让3DGS在充分表示场景的情况下减少数量(即去除冗余,并且保证局部的密度是合理的);
论文对3DGS配准的设计:
粗配准:从3DGS中提取点云,用基于点云配准的方法进行粗配准,在已有点云配准的基础上考虑了3DGS的额外属性,比如不透明度。
因为3DGS的点云只捕获了粗糙的几何结构,通常还存在噪声,因此粗配准没办法获得足够精确的结果,还需要进行精配准。
精配准:图像引导的精配准pipeline,借助3DGS来渲染少量的图像,Then, the fine registration pipeline projects images into 3D volumetric features for final matching and transformation estimation.
论文称主要想法来自于观察,GS不仅包含几何信息,还包含固有的详细图像信息,这些信息可以支持更精确的对准。
论文的贡献:
- 第一个研究在3DGS上进行配准的;
- 精心设计了一个从粗到细的pipeline,充分考虑了3DGS的特点;
- 提出了一种图像引导的精细配准方法;
- 为他们提出的新任务创建了一个benchmark。
Method
Overview
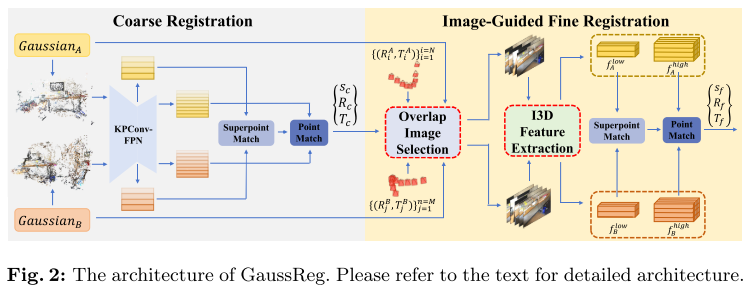
论文在这里对整个过程做了一个简单的介绍。
假设:两个存在overlap的场景A和B,每个场景都有自己的3DGS模型,即$Gaussian_A$和$Gaussian_B$,对应导出的点云为$Points_A$和$Points_B$,并且保留所有训练图像的camera pose,即${C_i^A = (R_i^A,T_i^A)}_{i=0}^N$和${C_j^B = (R_j^B,T_j^B)}_{j=0}^N$。
看起来保留camera pose,是为了根据粗配准,找到能够观察到overlap区域的camera pose,然后渲染图象进行配准。
如果是这样的话,看起来非常的不优雅。理论上不需要保留camera pose,可以自己计算一些overlap区域的视角。
而且既然保留了camera pose,为什么不直接保留图像来进行配准呢?
目标:找出让场景B能和A对齐的刚性变换${s,R,T}$,其中$s$是比例因子,$R$是旋转矩阵,$T$是平移向量。
粗配准阶段:输入$Points_A$和$Points_B$,输出粗变换${s_c,R_c,T_c}$。
精配准阶段:根据粗配准结果找到highly overlapping region,在这个区域周围选择合适的camera pose渲染图象。之后根据Image-Guided 3D(I3D) Feature Extraction来提取volumetric features,用于后续的local matching,最终输出粗变换${s_f,R_f,T_f}$。
Coarse Registration
选择不透明度$\alpha$大于0.7(经验参数)的高斯点,根据位置和球谐,得到彩色点云$(x,y,z,r,g,b)$。
!!!之前我设计3DGS配准的时候,不透明度用不上,现在看来其实是可以用来做一个简单的过滤,只用不透明度高的来配准。
粗配准这边遵循了GeoTransformer的流程。
==TODO:这部分目前不感兴趣,先略过了。这部分看起来应该就是直接用的GeoTransformer==
Image-Guided Fine Registration
论文在这里提到因为3DGS训练过程中没有添加特定的几何约束,因此产生的点云可能会出现一定程度的失真。
这里个人认为,在RGBD SLAM里面,尽管有深度的输入,但是本质上和sfm输入还是差不多的,仍然存在一定程度的失真。
这还是因为,训练过程中没有添加几何约束,3DGS甚至可能会为了渲染的更好把某些正确位置的点云往不正确的位置移动。
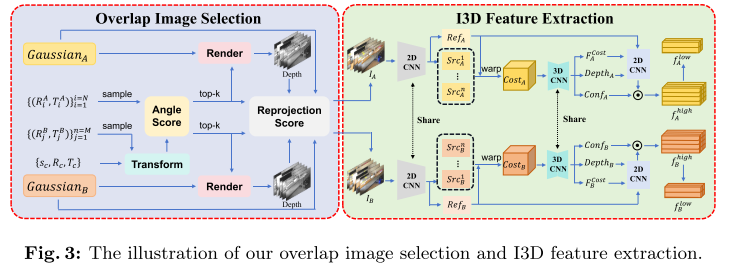
核心思路如下所示,分为两个步骤:Overlap Image Selection和Image-Guided 3D Feature Extraction。
结合论文和这张图就可以把这部分看得很明白了,全是干货,都不用写笔记。
不过这个过程看起来还是比较僵硬,似乎可以总结成:
- 确定重叠的视角
- 渲染图象
- 生成深度图
- 选择合适的点,得到点云
- 按照粗配准的步骤,点云和点云之前配准
并且这个fine registration network还需要训练。。。(因为,类似单目深度估计?)
Gaussian Splatting Fusion and Filtering
这确实是两个场景的3DGS配准之后需要做的事情,不过我不太关注这部分,略过了。
不过这里提到了球谐函数的旋转,以后有需求可以回来看一眼。
emmm,简单看了一遍,这里写的很少,看起来仅仅是旋转了一下gaussian,,,这个代码我也写过,,,球谐的旋转确实要注意。回头检查一下自己旋转的Gaussian,把球谐部分的旋转考虑上!(不过有其他方法可以避免旋转高斯,旋转高斯太慢了,不如旋转点云再处理,,,)
Discussion
论文提到了,他们融合gaussian的策略是简单的。
深表认同,我也会,不过球谐我没考虑,这里回头注意一下。
其他
论文提到的一些工作:
NeRFuser
NeRFuser[10]中提出的方法,我们可以为每个场景渲染大量的图像,然后从SfM (structure-from-motion)中恢复所有这些图像的姿态。然而,这种方法非常耗时;
Dreg-NeRF
与DReg-NeRF方法[6]一样,我们可以从两个场景的NeRF中查询体素网格,将隐式亮度场转换为显式体素,提取特征,建立匹配关系进行配准。但该方法面临两个问题:a)难以将无界场景的NeRF转换为有界体素;B)体素网格的分辨率限制使得该方法不适合较大的场景。
GeoTransformer
徐凯组的工作,也是这篇论文粗配准的pipeline
这里面应该是用了Transformer,看来很多东西我想躲的躲不掉了,都得看。。。
NeRF2NeRF
利用人工注释的关键点获得初始转换,并使用从预训练的NeRF中提取的表面场对其进行细化。
个人评价:
做的非常有意思,和我想解决的问题一样,但是走了完全不一样道路。
我认为3DGS还存在太多的问题,因此需要逐步解决这些问题,然后用传统的点云配准方法进行配准;
而论文认为3DGS固然有很多的问题,但是可以精心设计一些解决方法,用传统的点云配准方法进行粗配准,再用基于图像引导的方法进行精配准。
因为3DGS的表示目前还不完美,因此论文其实做了一些妥协。
渲染图象再根据图像进行配准,其实放到SLAM里面来说,非常的合适,后面可以考虑一下。
但是为什么要渲染图象呢?其实还是因为3DGS的表示目前还有很多小问题,只能进行妥协。但是渲染图象本质上还是在把3DGS当成隐式的表示方法,最后做出来个人觉得不是直接基于3DGS的配准。



