论文阅读:Scaffold-GS和Octree-GS
Scaffold-GS: Structured 3D Gaussians for View-Adaptive Rendering
我感觉有点类似point-nerf,本质上似乎,非常接近。。。
论文的motivation:While this approach(3DGS) offers several advantages, it tends to excessively expand Gaussian balls to accommodate every training view, thereby neglecting scene structure. This results in significant redundancy and limits its scalability, particularly in the context of complex large-scale scenes. Furthermore, view-dependent effects are baked into individual Gaussian parameters with little interpolation capabilities, making it less robust to substantial view changes and lighting effects.
论文的贡献:In conclusion, our contributions are
- Leveraging scene structure, we initiate anchor points from a sparse voxel grid to guide the distribution of local 3D Gaussians, forming a hierarchical and region-aware scene representation;
- Within the view frustum, we predict neural Gaussians from each anchor on-the-fly to accommodate diverse viewing directions and distances, resulting in more robust novel view synthesis;
- We develop a more reliable anchor growing and pruning strategy utilizing the predicted neural Gaussians for better scene coverage.
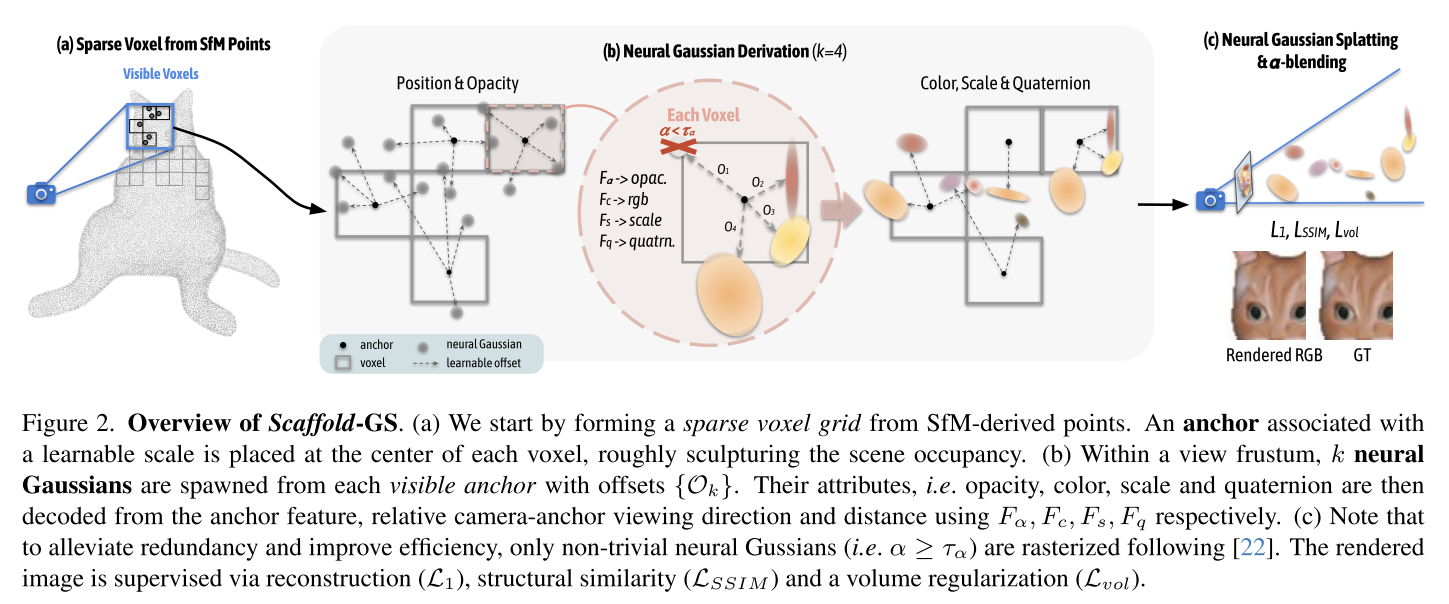
看起来,voxel仅仅是表示哪儿应该有点,sfm points没有被初始化为高斯,而是处理成voxel。每个voxel的中心作为锚点,然后具有一些可学习的参数。
MLP用来解码这些锚点,根据锚点的参数,获得锚点附近指定数量的高斯的参数。
point-nerf的既视感,并且指定了每个锚点生成几个高斯。
那为什么不做一个grid feature,解码这个feature拿到高斯。。。
致密化本质上还是3dgs的那一套,计算没有锚点的体素中gaussians的平均梯度,如果大于阈值就建立一个锚点。而如果某个锚点生成的gaussian不透明度偏低,那就删除这个锚点。
20241018更新:
每一个anchor包括的数据有:
param detail num $v$ 点坐标 3 $l_v$ scaling factor 3 $O_v$ learnable offsets 3k $f_v$ feature 32 38+3k 高斯点数相同时:
- $k < 4$,用gaussian进行表示更节省空间
- $k \geq 4$,用anchor更节省空间
从anchor到gaussian:
$\mu = x_v + O_v l_v$
其他参数通过网络解码feature拿到

anchor的生长:
看论文描述,还是类似于Gaussian Splatting的ADC,平均梯度大于阈值,才会生长一个新的锚点。
同时论文还会对新的锚点进行随机淘汰(看起来是类似Compact 3DGS的learnable mask)。
anchor的删除:
如果某个anchor一直在生成不透明度比较低的高斯,就把他删掉。
看这个实验,确实是SSIM会稍微好一些:
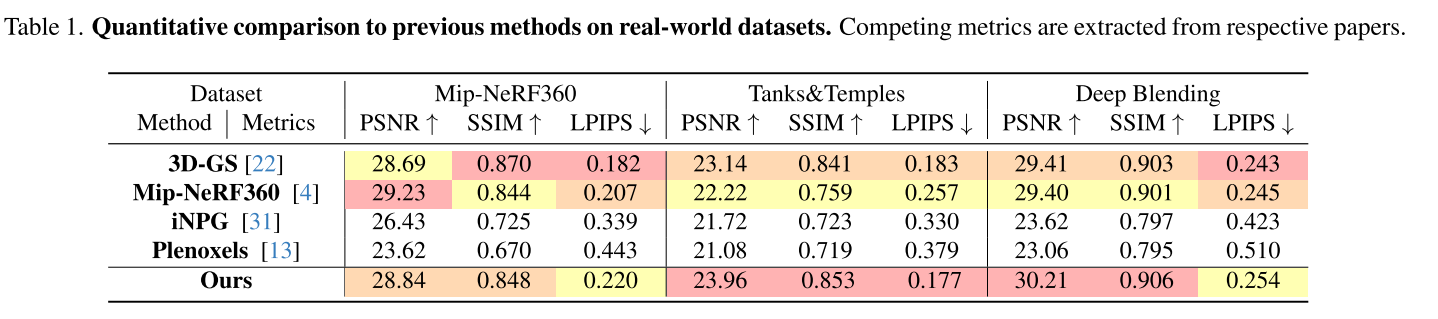
这个实验用的3D-GS不会是sh degree=3的吧???自己用sh degree=0,3DGS不改回去的话,这么比较就不是很有意义了。
不如在这里比较一下锚点数和高斯的点数,并且说明k设置的多少,即每个锚点产生多少个gaussian。
论文里面没找到scaffold保存的是什么,如果是anchor+MLP的话,那确实可以做到还挺小的。。。
如果是最终保存的ply,用ply来对比,那就非常不合适了。
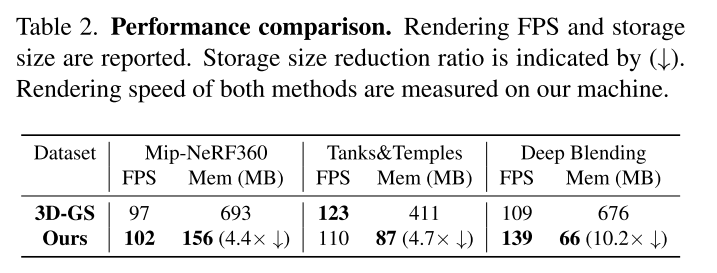
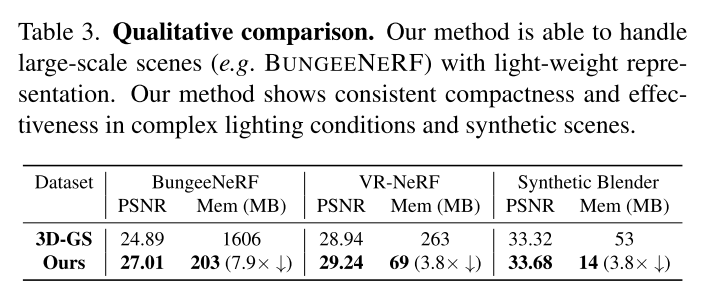
这个实验就更有意思了,看起来最终一个锚点只会产生3-5个高斯。这样的话,锚点的方法和高斯的方法,参数量其实是差不多的。
不过这个实验也挺有意义的,说明scaffold倾向于去生成不冗余的高斯。
Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians
论文的motivation:However, both of them(Scaffold-GS、Mip-Splatting等工作) inherit the view-frustum-only based Gaussian selection strategy, which gives rise to two primary issues. Firstly, this requires rendering every details of an object presented within the view frustum, regardless of whether it is observed from a near or far viewpoint. This redundancy in computation can result in potential inefficiencies and inconsistencies in rendering speed, especially in scenarios involving zoom-out trajectories in large-scale, detail-rich scenes. Secondly, the agnostic approach to LOD implies that all 3D Gaussians must compete to represent the scene across all observed views, leading to compromised rendering quality across different levels of detail.
论文的贡献:We found it 1) further enhances the alignment of 3D Gaussians with the content presented in the training images, improving the rendering quality without increasing performance overhead; 2) enables consistent rendering speed by dynamically adjusting the fetched LOD on-the-fly. We demonstrate its superiority in modeling large-scale scenes and extreme-view sequences.

看图注,创建的是有界的八叉树。不过用八叉树来控制细节,还挺方便的。
感觉和scaffold-gs相比,就是在它上面加了个八叉树,锚点通过八叉树来获取,根据观看距离和场景的丰富程度来给定lod的级别?其他并没有什么很新颖的内容了。



