论文阅读《Compact 3D Gaussian Representation for Radiance Field》
问题:3DGS需要大量的3D高斯来保持渲染图像的高保真度,这需要大量的内存和存储空间。
解决方案:
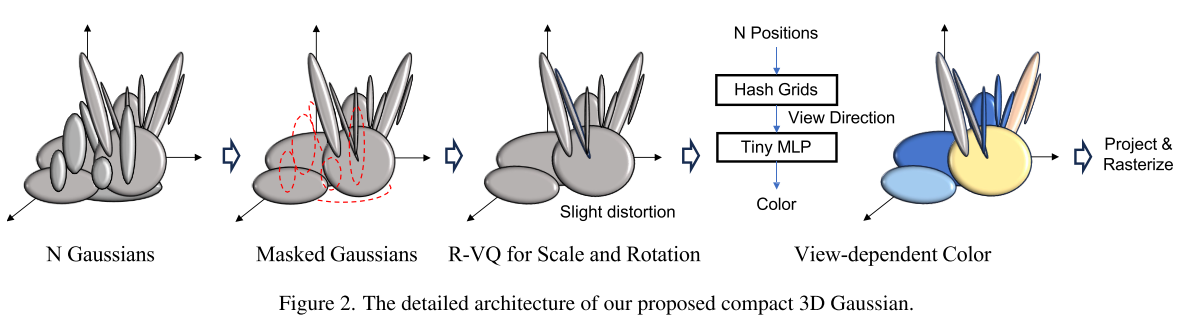
- 为了解决3DGS中关键的大内存和存储问题,我们提出了一个紧凑的3D高斯表示框架。该方法显著提高了内存和存储效率,同时具有高质量的重构、快速的训练速度和实时的渲染效果,如图1所示。我们特别强调两个关键目标。首先,我们的目标是在不牺牲性能的情况下减少场景表示所需的高斯点数量。高斯函数的数量随着由克隆和分裂高斯函数组成的规则致密化过程的增加而增加,它是表示场景精细细节的关键组成部分。然而,我们观察到,目前的致密化算法产生了许多冗余和不必要的高斯分布,导致内存和存储需求高。我们引入了一种新的基于体积的掩蔽策略,该策略可以识别和去除对整体性能影响最小的非必要高斯值。利用所提出的掩蔽方法,我们学会了在训练过程中减少高斯数的同时获得高性能。除了有效的内存和存储使用,我们可以实现更快的渲染速度,因为计算复杂度与高斯数成线性比例。
- 其次,我们提出压缩高斯属性,如视图相关的颜色和协方差。在原始的3DGS中,每个高斯函数都有自己的属性,并且没有利用空间冗余,这在各种类型的信号压缩中得到了广泛的应用。例如,相邻的高斯函数可能具有相似的颜色属性,我们可以重用相邻高斯函数的相似颜色。考虑到这个动机,我们结合了一个基于网格的神经场来有效地表示与视图相关的颜色,而不是使用每个高斯颜色属性。当提供查询高斯点时,我们从紧凑的网格表示中提取颜色属性,避免了为每个高斯单独存储颜色属性的需要。对于我们最初的方法,由于其紧凑性和快速的处理速度,我们从几个候选中选择了基于哈希的网格表示(Instant NGP[30])。这种选择大大降低了3DGS的空间复杂性。
- 与颜色属性相反,大多数高斯函数具有相似的几何形状,在尺度和旋转属性上具有有限的变化。3DGS代表了一个由无数小高斯元集合而成的场景,每个高斯原语都不期望表现出很高的多样性。因此,我们引入了一种基于码本的方法来建模高斯函数的几何形状。它学习寻找在每个场景中共享的相似模式或几何形状,并且只存储每个高斯的码本索引,从而产生非常紧凑的表示。此外,由于码本的大小可能非常小,因此训练期间的空间和计算开销并不显著。
Method
Background
建立在3DGS的基础上,Each Gaussian represents 3D position, opacity, geometry (3D scale and 3D rotation represented as a quaternion), and spherical harmonics (SH) for view-dependent color.
看起来就是经典的3DGS
Overall architecture
我们的主要目标是1)减少高斯函数的数量,2)在保持原始性能的同时紧凑地表示属性。为此,在优化过程中,我们屏蔽掉对性能影响最小的高斯函数,并通过码本表示几何属性,如图2所示。我们使用基于网格的神经场来表示颜色属性,而不是在每个高斯分布中直接存储它们。对于几何属性,如尺度和旋转,我们建议使用基于码本的方法,可以充分利用这些属性的有限变化。最后,在随后的渲染步骤中使用少量具有紧凑属性的高斯函数,包括投影和栅格化来渲染图像。
Gaussian Volume Mask
The scale attribute of each Gaussian determines its 3D volume, which is then reflected in the rendering process. Small-sized Gaussians, due to their minimal volume, have a negligible contribution to the overall rendering quality, often to the point where their effect is essentially imperceptible. In such cases, it becomes highly beneficial to identify and remove such unessential Gaussians.
这里认为小尺寸的高斯,因为体积很小,对渲染的贡献可以忽略不计,可以识别和去除他们。
这里就提出了一个用来处理尺度、透明度的learn-able mask,学习的向量是$m_n$,最终的mask是$M_n$,如下公式所示:
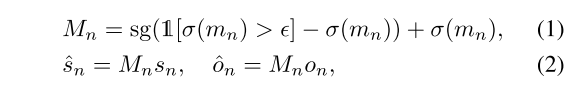
通过添加掩蔽损失Lm来平衡准确渲染和训练过程中消除的高斯数:
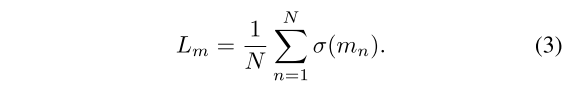
与Compact GSSLAM相同的疑问:为什么要使用这个损失函数?
看这个损失函数的意思,它想要mask掉所有东西啊,这样肯定有问题吧???
感觉,这个L_m不是单独使用的,给个权重,放到一个大的loss function里。
在每一次致密化中,我们根据二值掩模消除高斯分布。此外,与原始3DGS在训练中间停止致密化并保留高斯数直至结束不同,我们在整个训练过程中始终保持掩码,有效地减少了不必要的高斯数,并确保在整个训练阶段使用低GPU内存进行高效计算(图3)。一旦训练完成,由于我们删除了掩码高斯数,因此不需要存储掩码参数m。
Geometry Codebook
参考资料:
关于VQ
关于VAE
关于VQ-VAE
R-VQ
论文说他们观察到,大多数高斯的几何形状是非常相似的,显示只有微小的差异在规模和旋转特性。此外,一个场景是由许多小高斯组成的,并且每个高斯原语都不期望表现出广泛的多样性。因此他们想到了使用R-VQ:
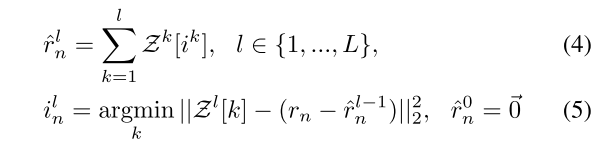
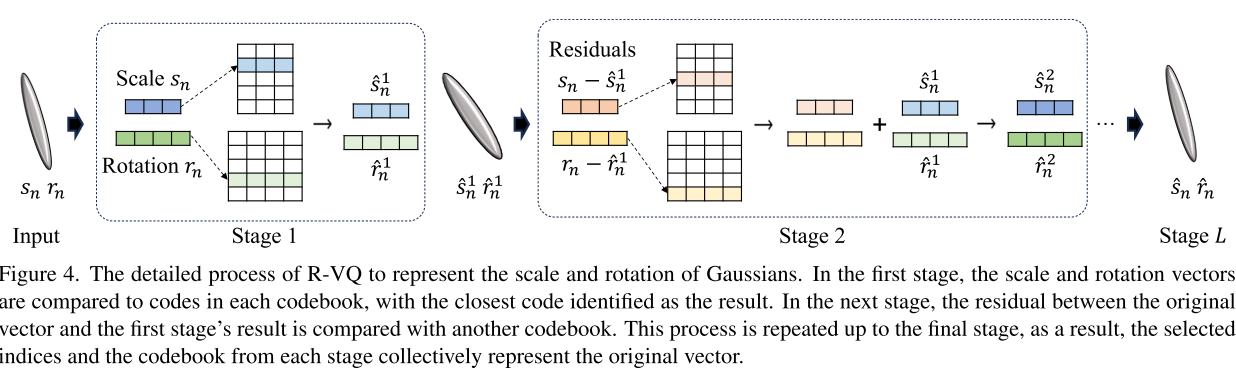
我找到一个算法框图,写的很简单很清楚:

这个codebook也是需要训练的,对应的损失函数如下:
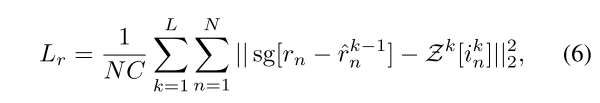
如果考虑论文里面提到的公式4、5,主要是公式5,这个损失函数还挺好理解的,就是希望每一个阶段的残差和对应的codebook的欧氏距离最小。
Compact View-dependent Color
这里说3DGS的每个高斯总共有59个参数,其中48个用来表示SH(max 3 degrees)。论文认为用基于网格的神经辐射场方法表示每个高斯视图相关的颜色会比较好:

Training

总结
这篇文章应该算看懂了。他就做了三个东西:
1、【Gaussian Volume Mask】,就是learn-able mask,用可以学习的掩膜去mask掉冗余的部分高斯函数
2、【Geometry Codebook】,就是应用了R-VQ来归并那些形状、旋转很相似的高斯
3、【Compact View-dependent Color】,就是不使用3DGS的球谐去表示视图相关的颜色了,而是用了类似instant-ngp的方法去表示视图相关的颜色



