Compact 3DGS代码阅读
Gaussian Volume Mask
learn-able mask,用可以学习的掩膜去mask掉冗余的部分高斯函数
定义
gaussian_model.py中def __init__()定义了learn-able mask
def __init__(self, model):
# 与原始3dgs相比,下面两个参数不见了
# self._features_dc
# self._features_rest
# 省略......
self._mask = torch.empty(0) # learn-able mask
# 省略......初始化
``gaussian_model.py中def create_from_pcd()`初始化了learn-able mask
def create_from_pcd(self, pcd: BasicPointCloud, spatial_lr_scale: float):
# 省略......
# 这里的mask对应了论文中的Gaussian Volume Mask,即learn-able mask,用可以学习的掩膜去mask掉冗余的部分高斯函数
self._mask = nn.Parameter(torch.ones((fused_point_cloud.shape[0], 1), device="cuda").requires_grad_(True))
# 省略......如论文3.1节最后讲的一样“Once training is completed, the mask parameter m does not need to be stored since we re moved the masked Gaussians.”``gaussian_model.py中并没有保存这个mask,因此在def load_model()`函数中也没有加载mask的过程。
优化
``gaussian_model.py`中通过Adam优化器优化learn-able mask
l = [
{'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"},
{'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"},
{'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"},
{'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"},
{'params': [self._mask], 'lr': training_args.mask_lr, "name": "mask"}
]
self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15)论文中的损失函数如下,最小化这个损失函数,会尽可能多的mask掉场景中的高斯。

但是这个损失函数不是单独使用的,上面定义优化器的时候,就把mask和其它参数放到一起了,说明它会作为一个总的loss的一部分使用。这样,在给定的权重,和其他loss的共同作用下,它会像论文提的那样“We balance the accurate rendering and the number of Gaussians eliminated during training by adding masking loss”。
在论文的公式中,也体现了这一点,如下所示。

对应到代码中,是train.py中def training()函数如下的部分:
# Loss
gt_image = viewpoint_cam.original_image.cuda()
Ll1 = l1_loss(image, gt_image)
# 与3dgs相比,其实只多了一个mask相关的损失
loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (
1.0 - ssim(image, gt_image)) + opt.lambda_mask * torch.mean((torch.sigmoid(gaussians._mask)))
loss.backward()过滤冗余高斯
在论文中,learn-able mask的公式如下所示。论文写的比较严谨,把stop grad的操作也放到公式里了,看着似乎很复杂。
实际上,公式(1)的意思就是如果$\sigma(m_n)>\epsilon$,对应的$M_n=1$,否则对应的$M_n=0$。
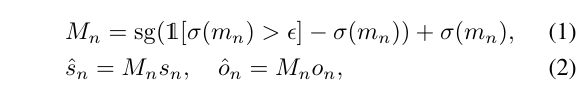
实际实现中有多处用到了learn-able mask,这些用法都包含在gaussian_model.py中。核心其实就是一行代码:torch.sigmoid(self._mask) <= 0.01。
第一处:对3D高斯模型进行致密化或者剪枝操作时使用。
# 对3D高斯分布进行密集化和修剪的操作
def densify_and_prune(self, max_grad, min_opacity, extent, max_screen_size):
grads = self.xyz_gradient_accum / self.denom
grads[grads.isnan()] = 0.0
self.densify_and_clone(grads, max_grad, extent)
self.densify_and_split(grads, max_grad, extent)
# 与3dgs相比,这里考虑了self._mask
# 对于每个3dgs,如果对应的sigmoid(mask)<=0.01 或 opacity<min_opacity就会被剪枝
# 这部分是在no_grad下进行的,对应了论文中的公式1
prune_mask = torch.logical_or((torch.sigmoid(self._mask) <= 0.01).squeeze(),
(self.get_opacity < min_opacity).squeeze())
if max_screen_size:
big_points_vs = self.max_radii2D > max_screen_size
big_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extent
prune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws)
self.prune_points(prune_mask)
torch.cuda.empty_cache()对应train.py下面的内容。
# Densification
if iteration < opt.densify_until_iter:
# Keep track of max radii in image-space for pruning
gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter],
radii[visibility_filter])
gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)
if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:
size_threshold = 20 if iteration > opt.opacity_reset_interval else None
# ============= 在这里调用 =============
gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold)
if iteration % opt.opacity_reset_interval == 0 or (
dataset.white_background and iteration == opt.densify_from_iter):
gaussians.reset_opacity()
else: # 新增内容,间隔一定次数通过可学习的mask筛选一遍高斯
if iteration % opt.mask_prune_iter == 0:
gaussians.mask_prune()第二处:如果不进行致密化或剪枝,但迭代了一定次数之后,会执行def mask_prune()过滤掉冗余高斯。
def mask_prune(self):
# 这部分是在no_grad下进行的,对应了论文中的公式1
prune_mask = (torch.sigmoid(self._mask) <= 0.01).squeeze()
self.prune_points(prune_mask)
torch.cuda.empty_cache()对应train.py下面的内容。
# Densification
if iteration < opt.densify_until_iter:
# Keep track of max radii in image-space for pruning
gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter],
radii[visibility_filter])
gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)
if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:
size_threshold = 20 if iteration > opt.opacity_reset_interval else None
gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold)
if iteration % opt.opacity_reset_interval == 0 or (
dataset.white_background and iteration == opt.densify_from_iter):
gaussians.reset_opacity()
else: # 新增内容,间隔一定次数通过可学习的mask筛选一遍高斯
if iteration % opt.mask_prune_iter == 0:
# ============= 在这里调用 =============
gaussians.mask_prune()第三处:最终训练结束,准备导出3D高斯模型的时候使用。
def final_prune(self, compress=False):
# 这部分是在no_grad下进行的,对应了论文中的公式1
prune_mask = (torch.sigmoid(self._mask) <= 0.01).squeeze()
self.prune_points(prune_mask)
# 省略。。。。。。对应train.py下面的内容。
if iteration == opt.iterations:
# 完成迭代之后保存结果,保存的结果要进行一次最终的剪枝
storage = gaussians.final_prune(compress=comp)
with open(os.path.join(args.model_path, "storage"), 'w') as c:
c.write(storage)
# TODO 这里在做什么?
gaussians.precompute()Geometry Codebook
应用了R-VQ来归并那些形状、旋转很相似的高斯
定义&初始化
gaussian_model.py中def __init__()定义了R-VQ
# ====================== 新增内容 ======================
# 对应论文中的Geometry Codebook
# 应用R-VQ来归并那些尺度scale、旋转rot很相似的高斯,下面这个RVQ甚至还是现成的
# 只看这个文件,RVQ似乎只对最后导出npz或ply的时候有用,过程中似乎没有办法降低高斯的内存占用???毕竟尺度和旋转这两个向量还在这里放着???
# TODO:可以用相同的数据集,对比一下3dgs和compact 3dgs内存的占用情况!
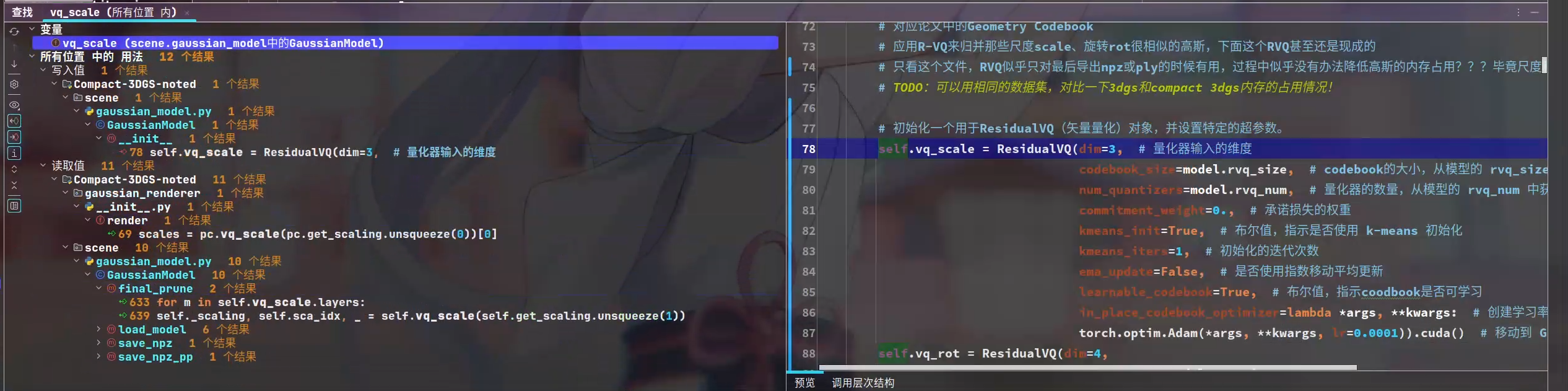
# 初始化一个用于ResidualVQ(矢量量化)对象,并设置特定的超参数。
self.vq_scale = ResidualVQ(dim=3, # 量化器输入的维度
codebook_size=model.rvq_size, # codebook的大小,从模型的 rvq_size 中获取
num_quantizers=model.rvq_num, # 量化器的数量,从模型的 rvq_num 中获取
commitment_weight=0., # 承诺损失的权重
kmeans_init=True, # 布尔值,指示是否使用 k-means 初始化
kmeans_iters=1, # 初始化的迭代次数
ema_update=False, # 是否使用指数移动平均更新
learnable_codebook=True, # 布尔值,指示coodbook是否可学习
in_place_codebook_optimizer=lambda *args, **kwargs: # 创建学习率为 0.0001 的 Adam 优化器
torch.optim.Adam(*args, **kwargs, lr=0.0001)).cuda() # 移动到 GPU 上
self.vq_rot = ResidualVQ(dim=4,
codebook_size=model.rvq_size,
num_quantizers=model.rvq_num,
commitment_weight=0.,
kmeans_init=True,
kmeans_iters=1,
ema_update=False,
learnable_codebook=True,
in_place_codebook_optimizer=lambda *args, **kwargs:
torch.optim.Adam(*args, **kwargs, lr=0.0001)).cuda()
# 通过取codebook大小的以2为底的对数,计算表示码书索引所需的比特数。这个参数只用在计算内存大小上了。
self.rvq_bit = math.log2(model.rvq_size)
# 存储模型中的量化器数量,以备后用。这个参数也是只用在计算内存大小上了。
self.rvq_num = model.rvq_num关于ResidualVQ
这部分实现对应的仓库为:https://github.com/lucidrains/vector-quantize-pytorch
更详细的用法也可以参考这个仓库。
优化更新?
很奇怪,我查找了文件,但是没有找到更新的地方。可能还得去上面的仓库里面学习一下。。。
我猜测,每次使用RVQ,它就会迭代更新一次,毕竟初始化的时候就给定了优化器。而且看起来,每次渲染的时候才有可能会进行一次更新。
这样的话,我还是感觉RVQ的作用只是保存结果的时候,让存储空间的占用更小,训练过程中没办法让显存占用变小???
归并形状、旋转相似的高斯?
似乎只有渲染、最终保存的时候,会进行。
Compact View-dependent Color
不使用3DGS的球谐去表示视图相关的颜色了,而是用了类似instant-ngp的方法去表示视图相关的颜色
略,暂时没去看~



