3D Gaussian Splatting学习笔记
视频笔记:Point-based NeRF
【【综述】基于点的神经辐射场,用点云实现真实的新视角渲染】 https://www.bilibili.com/video/BV1LX4y1H7a1/?share_source=copy_web&vd_source=5040c17d0665f566f786d3874bbfd13d
PCD to NeRF:

NeRF to PCD:

弹幕讨论:这里说的点云更容易接入SLAM的优势不成立,现在很多SLAM的前端也都是基于2D Image来估计位姿的
相关工作:
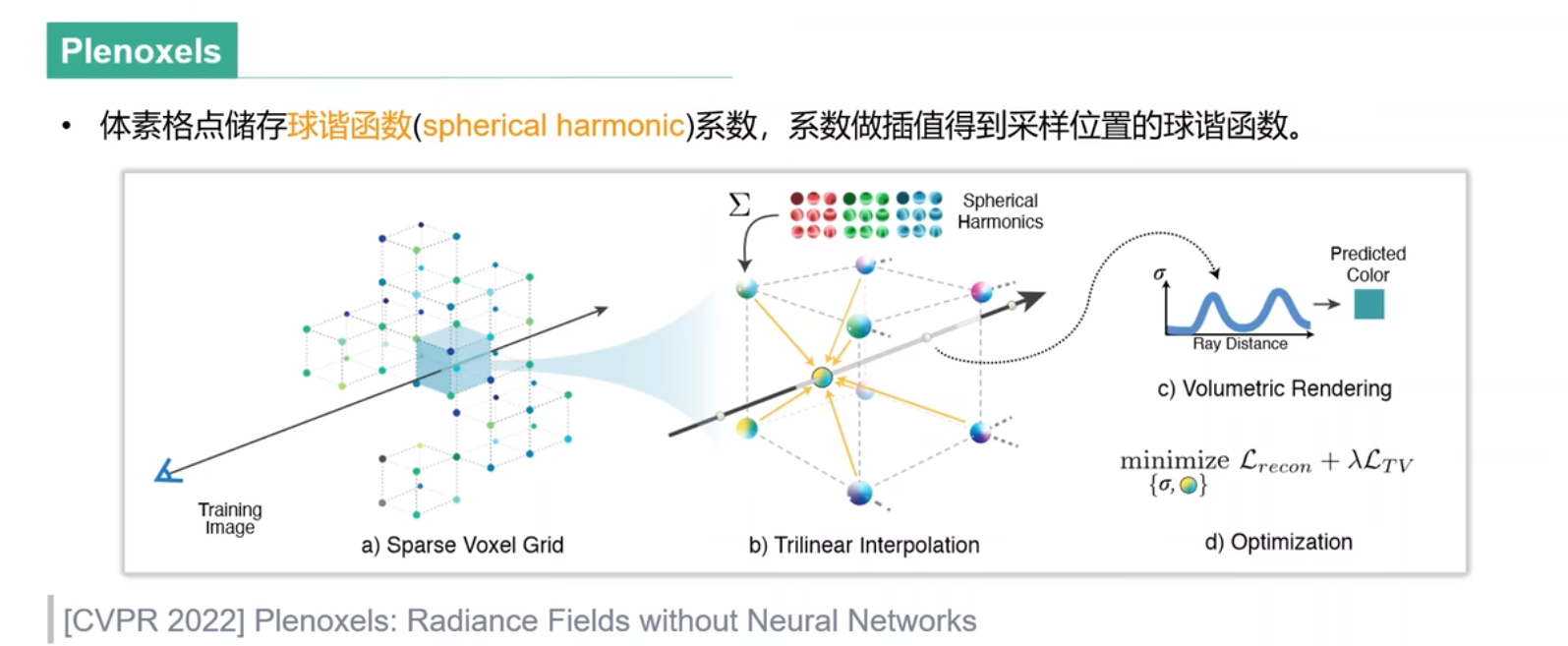
我觉得这里面最重要的是Plenoxels和Point-NeRF,这两个工作后面还需要好好了解。

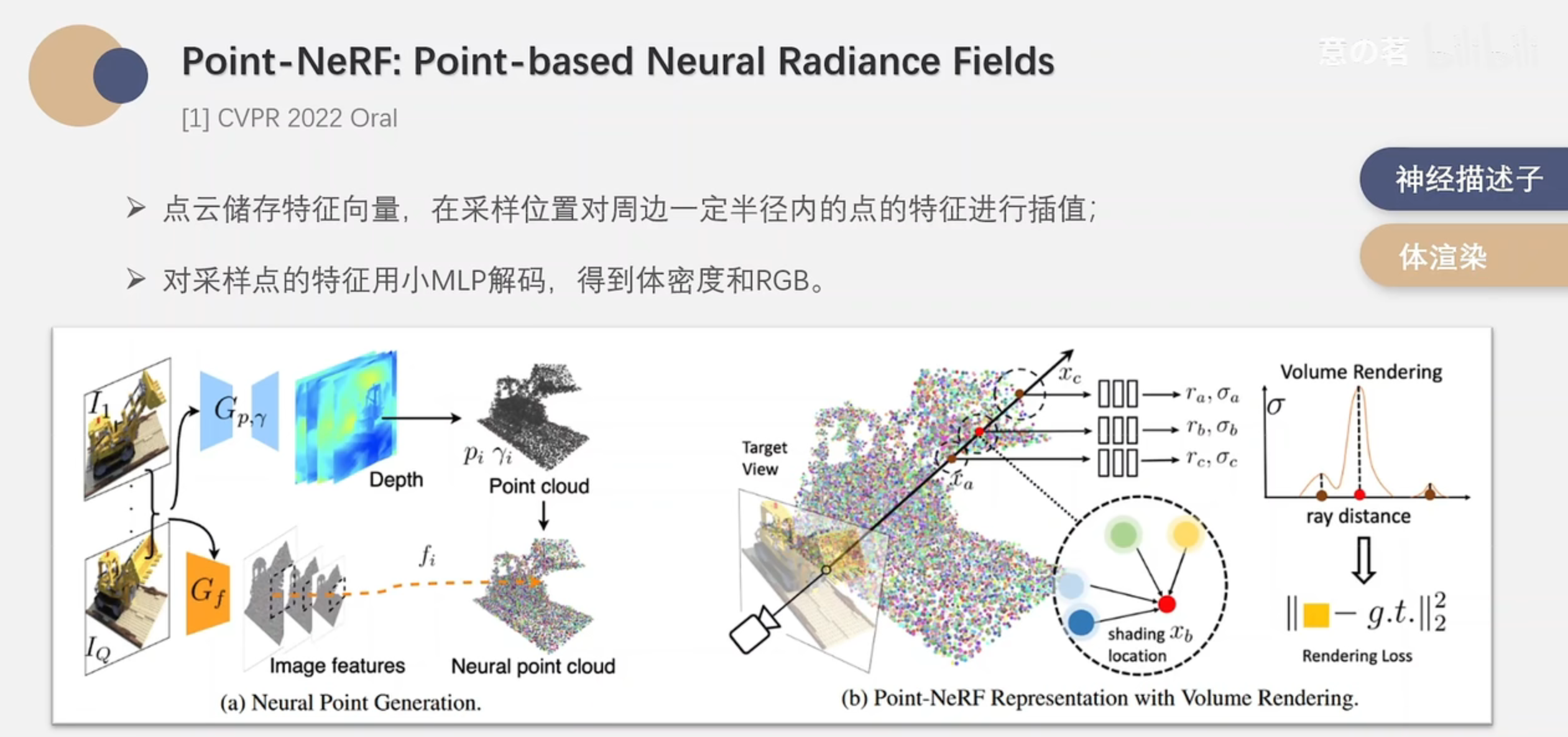
感觉就像是,把feature grid换成了点云,取采样点一定半径内的点云特征向量进行插值,再用小MLP解码。

问题:
查询MLP的次数和原版NeRF差不多,拖慢了渲染速度;
比如,这里可以用上SNeRG[20] Baking Neural Radiance Fields for Real-Time View Synthesis. ICCV 2021. 这样的延迟渲染模型来加速,把一条射线上的采样点的特征融合之后再拿去解码,从而减少MLP查询次数;
点云密度和渲染质量之间需要平衡;
- 点云密度高,显存占用增加
- 降低点云密度,会降低渲染质量
小模型这样的问题不明显,但是场景扩大就有问题了;

随着地图的扩展,需要合适的策略平滑点云的密度,并且自适应的对点云分布进行调整;
Point-NeRF里面有对点云的生长和修建,但这是为了补全模型、剔除外点,而且效率并不高,因为点的变动就意味着这个局部位置相关的神经描述子都得再次优化。
Point-SLAM的遗憾:
- 没有针对Point-NeRF的问题做些什么;
- 没有用上基于特征点的视觉里程计来进行位姿估计,后端已经是点云估计模型了,而前端还在用基于优化的这种很低效的方法
- 不过使用视觉里程计前端,那么前端的几何特征怎么和后端的神经描述子相统一或融合,也是值得研究的问题
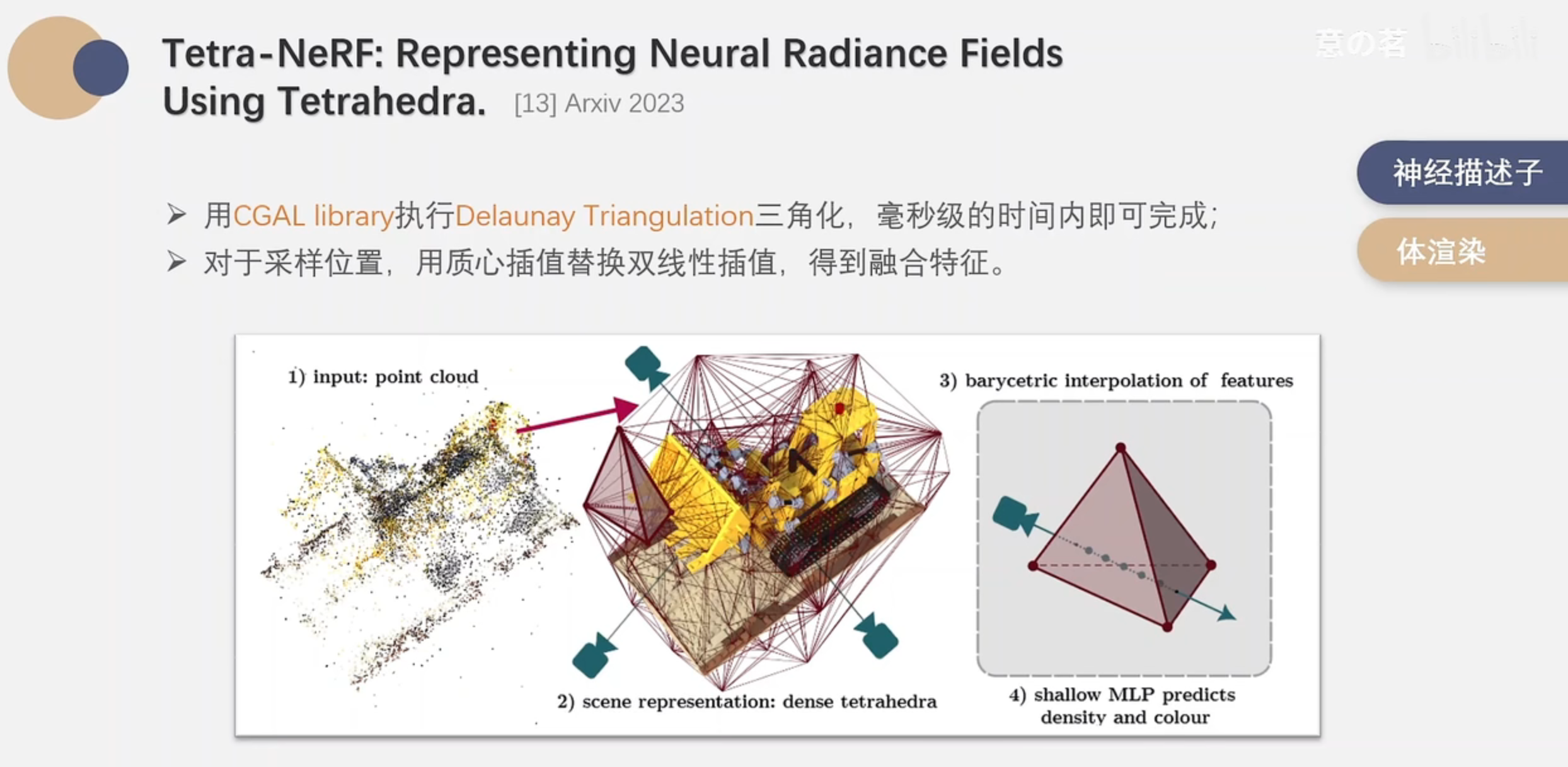
用CG的很多成熟的工具加速了Point-NeRF的很多流程,非常讨巧
总结:

我发现如果结合点云的话,CG里面有很多现成的工具可以用,点云是一个把CG和CV结合起来的桥梁。
视频笔记:3D Gaussian Splatting
【【论文讲解】用点云结合3D高斯构建辐射场,成为快速训练、实时渲染的新SOTA!】 https://www.bilibili.com/video/BV1uV4y1Y7cA/?share_source=copy_web&vd_source=5040c17d0665f566f786d3874bbfd13d
这个视频讲的比较简单,主要着力于公式推导方面,所以笔记就不做了。后面加到论文阅读笔记里面。
论文阅读笔记
主要是梳理整篇论文的结构,对一些细节的讨论不会展开。
第7部分由于我没有做过相关的实验,所以暂时只对Limitations感兴趣,只整理这部分的笔记;
附录的公式推导感觉也很常规,不太需要做什么笔记整理。
后续可能会针对某些部分写新的文章进行讨论,并且会整理需要了解的一些相关工作。
0 ABSTRACT& 1 INTRODUCTION
Background
论文指出,常见的3D场景表示方法,mesh和point都是显示的,并且非常适合fast GPU/CUDA-based rasterization。而NeRF的方法建立在连续场景表示的基础上,通常通过对体积射线行进的多层感知器(MLP)进行优化,以实现对捕捉场景的新视图合成,但是这些方法在渲染过程中需要进行的随机采样成本昂贵,可能导致图像中的噪声。
Motivation
论文发现了以下三个问题:
- 高成本的训练和渲染: 传统的Radiance Field方法通常需要昂贵的训练和渲染成本,限制了其在实际应用中的可行性。
- 速度与质量的权衡: 最近的更快方法通常在速度和合成质量之间做出权衡,难以在实时性和高质量之间找到平衡。
- 对于无边界和完整场景的实时显示: 针对无边界和完整场景的合成,特别是在高分辨率(1080p)下,目前的方法无法实现实时显示。
Goal
对此,论文提出了本文的目标:在Radiance Field方法中提出一种综合的解决方案,以克服传统方法中存在的训练和渲染成本高昂、速度与质量之间的权衡问题,实现对捕获场景的实时高质量新视角合成。
Solutions
- 3D Gaussians作为场景表示: 论文的第一组成部分引入了3D Gaussians作为一种灵活而富有表现力的场景表示方法。作者首先使用与以前的NeRF-like方法相同的输入,即通过结构从运动(Structure-from-Motion,SfM)[Snavely等人,2006]进行校准的相机,并使用SfM过程中产生的稀疏点云初始化了3D Gaussians集合。与大多数基于点的解决方案需要多视图立体匹配(Multi-View Stereo,MVS)数据不同,作者仅使用SfM点作为输入,就能够获得高质量的结果。作者强调3D Gaussians的优越性,因为它们是可微的体积表示,但也可以通过投影到2D并应用标准的 𝛼-混合(alpha-blending)非常高效地光栅化,使用与NeRF相同的等效图像形成模型。
- 3D Gaussians属性优化和密度控制: 该方法的第二个组成部分涉及对3D Gaussians的属性进行优化,包括3D位置、不透明度𝛼、各向异性协方差和球谐(Spherical Harmonic,SH)系数。这些优化与自适应密度控制步骤交替进行,其中在优化过程中添加和偶尔删除3D Gaussians。这一优化过程产生了场景的合理紧凑、非结构化和精确表示(在测试的所有场景中,1-5百万个高斯函数)。
- 实时渲染解决方案: 该方法的第三个和最后一个元素是实时渲染解决方案,使用快速GPU排序算法,灵感来自基于瓦片的光栅化的最新工作[Lassner和Zollhofer,2021]。由于采用了3D Gaussians表示,作者能够执行各向异性喷溅,通过排序和𝛼混合来保持可见性顺序,并通过跟踪所需的已排序喷溅的遍历来实现快速且准确的反向传播。这一部分的设计使得论文的方法能够实现对多个先前发布数据集的SOTA质量的实时渲染,尤其是在1080p分辨率下。
总体来说,这三个组成部分共同构成了一种新颖而高效的方法,通过综合运用3D Gaussians表示、属性优化与密度控制,以及实时渲染解决方案,成功地解决了现有方法在速度和质量之间的权衡问题。
Contributions
- 引入各向异性的3D Gaussians: 论文首次引入了各向异性的3D Gaussians,作为对辐射场的高质量、非结构化的表示。这种表示方法具有灵活性和表现力,为场景提供了一种新的、优越的建模方式。
- 3D Gaussians属性优化和自适应密度控制: 论文提供了一种优化3D Gaussians属性的方法,与自适应密度控制相互交替,从而创建了对捕获场景的高质量表示。这一优化过程确保了对场景的紧凑、非结构化和准确的建模,同时在训练过程中具有竞争力的时间成本。
- 快速、可微的GPU渲染方法: 论文提供了一种快速的、可微的GPU渲染方法,该方法具有视觉感知性,允许各向异性的喷溅,并通过快速的反向传播实现了高质量的新视图合成。这一渲染方法对GPU进行了优化,能够在实时性和视觉质量之间找到平衡,实现了对1080p分辨率下的多个数据集的先进质量的实时渲染。
2 RELATED WORK
据说这篇论文Related Work写的很好,我结合Chart GPT把这部分总结一下。
2.1 Traditional Scene Reconstruction and Rendering
在这个部分,作者首先回顾了传统的场景重建和渲染方法:
- 基于光场的方法: 早期的新视角合成方法基于光场,首先是对光场进行密集采样[Gortler等人,1996;Levoy和Hanrahan,1996],然后发展到允许非结构化捕获[Buehler等人,2001]。这一方法的进展使得对场景的不同角度的合成变得可能。
- 结构运动(Structure-from-Motion,SfM)的出现: SfM的出现开创了一个全新的领域,其中可以使用一系列照片来合成新的视图[Snavely等人,2006]。在相机校准期间,SfM估计了一个稀疏点云,最初用于简单的三维空间可视化。
- 多视图立体匹配(Multi-View Stereo,MVS): 随后的多视图立体匹配(MVS)算法在多年内产生了引人注目的全三维重建算法[Goesele等人,2007],为多种视图合成算法的发展提供了基础[Chaurasia等人,2013;Eisemann等人,2008;Hedman等人,2018;Kopanas等人,2021]。这些方法通过将输入图像重新投影并混合到新视图相机中,并利用几何信息来引导这一重新投影。尽管这些方法在许多情况下产生了出色的结果,但通常无法完全恢复未重建区域,或者无法处理MVS生成虚构几何的“过度重建”。
- 最近的神经渲染算法: 近期的神经渲染算法[Tewari等人,2022]在很大程度上减少了这些伪影,并避免了在GPU上存储所有输入图像的巨大成本,从而在大多数方面优于传统方法。
这一部分提供了关于传统场景重建和渲染方法的概述,强调了SfM和MVS的作用,并引入了最近的神经渲染算法,为读者提供了背景知识,以便更好地理解接下来讨论的新方法。
2.2 Neural Rendering and Radiance Fields
首先讨论深度学习技术在新视角合成方面的早期应用,以及一些问题和限制,这为引入Radiance Fields方法提供了一个背景,强调了Radiance Fields方法旨在克服这些问题:
- 早期深度学习在新视角合成中的应用: 作者指出,深度学习技术早期就被用于新视角合成[Flynn等人,2016;Zhou等人,2016]。具体而言,卷积神经网络(CNNs)被用于估计混合权重[Hedman等人,2018],或者用于纹理空间的解决方案[Riegler和Koltun,2020;Thies等人,2019]。
- MVS-based geometry的主要缺陷: 作者指出,这些方法中大多数采用了基于多视图立体匹配(MVS)的几何信息,但强调了这一方法的一个主要缺陷。具体而言,使用MVS的几何信息可能存在一些问题或限制,尽管这并未在这一段具体阐述。
- CNNs用于最终渲染的潜在问题: 作者提到,将CNNs用于最终渲染的方法经常导致时间上的闪烁现象(temporal flickering)。这表明在这些方法中,使用深度学习进行最终渲染时可能出现视觉上不稳定的问题。
接下来,作者讨论了新视角合成中的体积表示方法,特别是涉及到Soft3D、Neural Radiance Fields (NeRFs)以及Mip-NeRF360等方法:
- 体积表示的起源: 作者提到,对于新视角合成的体积表示方法的起源可以追溯到Soft3D[Pennser和Zhang,2017]。Soft3D采用了深度学习技术,并结合了体积射线行进,用一个连续可微的密度场表示几何。
- 深度学习与体积射线行进的结合: 随后,一些研究提出了采用深度学习技术与体积射线行进相结合的方法[Henzler等人,2019;Sitzmann等人,2019],这些方法基于连续可微的密度场来表示几何形状。然而,使用体积射线行进进行渲染需要大量的样本,因此渲染的成本相当高。
- Neural Radiance Fields (NeRFs)的引入: Neural Radiance Fields (NeRFs) [Mildenhall等人,2020]引入了重要性采样和位置编码以提高渲染质量,但是采用了大型的多层感知器(Multi-Layer Perceptron),对速度产生了负面影响。
- NeRF方法的影响: NeRF的成功引发了许多后续方法的出现,这些方法致力于解决质量和速度之间的平衡问题,通常通过引入正则化策略来实现。目前新视角合成中图像质量的最新进展是Mip-NeRF360[Barron等人,2022]。
- 质量与速度的平衡: 作者指出,尽管Mip-NeRF360在渲染质量方面表现出色,但训练和渲染时间仍然非常长。作者声称他们的方法在提供等同或在某些情况下超越Mip-NeRF360的图像质量的同时,实现了快速的训练和实时渲染。
在这之后,作者探讨了最近的方法在提高训练和/或渲染速度方面的一些设计选择,主要包括利用空间数据结构、不同的编码方式以及多层感知器(MLP)的容量调整。研究者们试图优化现有的方法,以在保持图像质量的同时提高方法的效率。这一多样性反映了领域中不断寻找速度和质量平衡的努力:
- 加速训练和渲染的设计选择: 作者指出,最近的方法在加速训练和渲染方面主要集中在三个设计选择上。这些选择涉及使用空间数据结构来存储(神经)特征,随后在体积射线行进过程中进行插值,采用不同的编码方式,以及调整MLP的容量。
- 方法的多样性: 这些方法包括空间离散化的不同变体[Chen等人,2022b,a;Fridovich-Keil和Yu等人,2022;Garbin等人,2021;Hedman等人,2021;Reiser等人,2021;Takikawa等人,2021;Wu等人,2022;Yu等人,2021],codebook[ Takikawa等人,2022]以及使用哈希表等编码[Müller等人,2022]的方法,允许使用较小的MLP或完全放弃神经网络[Fridovich-Keil和Yu等人,2022;Sun等人,2022]。
最后,作者介绍了两个最著名的方法,即InstantNGP和Plenoxels,并对它们的特点进行了讨论:
- InstantNGP: InstantNGP [Müller等人,2022] 是使用哈希网格和占用网格来加速计算的方法。它采用较小的MLP来表示密度和外观。该方法使用球谐函数(Spherical Harmonics)直接表示方向效应。
- Plenoxels: Plenoxels [Fridovich-Keil和Yu等人,2022] 则采用了稀疏的体素网格来插值一个连续的密度场,并且可以完全放弃神经网络。Plenoxels 也依赖于球谐函数,前者用于直接表示方向效应,后者用于将输入编码到颜色网络。
- 方法的局限性: 尽管这两种方法提供了出色的结果,但它们仍然可能在有效表示空白空间方面遇到困难,这在一定程度上取决于场景/捕获类型。此外,图像质量很大程度上受限于用于加速的结构化网格的选择,而渲染速度则受到需要查询许多样本以进行给定射线行进步骤的影响。
- 作者的方法: 作者声称,他们所采用的非结构化、明确的GPU友好的3D高斯方法可以在没有神经组件的情况下实现更快的渲染速度和更好的质量。这表明作者的方法旨在解决一些现有方法可能遇到的问题,如空白空间表示和结构化网格对图像质量和渲染速度的影响。
2.3 Point-Based Rendering and Radiance Fields
这部分Chart GPT表现得很差,总结的不太到位。
在这个部分,作者首先介绍了基于点云的渲染方法:
- 点云渲染的有效性: 作者指出,基于点的方法能够高效地渲染断开连接(disconnected)和非结构化的几何样本(unstructured geometry samples),即点云[Gross和Pfister,2011]。
- 点采样渲染的简单形式: 在其最简单的形式中,点采样渲染[Grossman和Dally,1998]会对一组具有固定大小的非结构化点进行光栅化。该过程可能利用图形API本地支持的点类型[Sainz和Pajarola,2004],也可能在GPU上通过并行软件光栅化[Laine和Karras,2011;Schütz等人,2022]进行。
- 点采样渲染的问题: 尽管点采样渲染在保持底层数据的真实性方面表现出色,但它存在一些问题,包括出现孔洞、导致走样,并且严格是不连续的。
- 高质量的点渲染方法: 为了解决这些问题,关于高质量点渲染的开创性工作采用了一种称为“splatting”的方法,该方法将点原语映射为超过一个像素的范围,例如圆形或椭圆形盘、椭球体或曲面元素[Botsch等人,2005;Pfister等人,2000;Ren等人,2002;Zwicker等人,2001b]。
之后开始介绍最近对可微分基于点云的渲染技术开展的研究工作:
- 可微分的点渲染技术的近期兴趣: 作者指出了对不同iable point-based rendering techniques(可微分的基于点的渲染技术)的最近兴趣。引文[Wiles等人,2020;Yifan等人,2019]可能是与这一领域相关的最新研究,表明了学术界对这种技术的关注。
- 点云增强和神经网络渲染: 该部分提到了点云被增强为神经特征,并使用卷积神经网络(CNN)进行渲染的技术。引文[Aliev等人,2020;Rückert等人,2022]可能提供了这些技术的实现细节和背后的原理。这些方法可以实现快速甚至实时的视图合成,但仍然依赖于多视图立体匹配(MVS)以获取初始几何信息,因此在一些难以处理的情况下,例如无特征/闪光区域或细小结构中,仍然会受到MVS的影响,尤其是过度或不足的重建。
- 依赖MVS的局限性: 作者强调了这些可微分的点渲染技术的一个局限性,即它们仍然依赖于多视图立体匹配(MVS)来获得初始几何信息。这种依赖可能导致一些问题,特别是在处理一些复杂场景时,如缺乏特征或表面反射光滑的区域,以及细小结构。在这些情况下,MVS可能会产生过度或不足的重建,从而影响最终的渲染效果。
进行了上面的一些铺垫之后,作者开始指出基于点云的 𝛼-blending 和 NeRF 风格的体积渲染本质上共享相同的图像形成模型,但是图像的渲染算法却不同:
- NeRF是一种连续表示,隐式地表示了空/占用的空间,为了渲染图象,需要进行昂贵的随机采样,从而导致噪声和计算开销。
- 而点云是一种非结构化、离散的表示,足够灵活,可以允许几何体的创建、销毁和移动。
之后,作者开始讨论快速渲染相关的工作:
- Pulsar [Lassner and Zollhofer 2021] 实现了快速的球体光栅化,这启发了作者开发瓦片和排序渲染器。在上文的分析基础上,作者决定保持对排序点进行(近似的)传统 𝛼-混合,这一决策旨在保留体积表示的优势。作者的光栅化过程在处理排序后的点时尊重能见度顺序,与 Pulsar 的无序方法形成对比。
- 前述提到的其他方法使用卷积神经网络(CNNs)进行渲染,但这可能导致时间上的不稳定性。尽管如此,Pulsar [Lassner and Zollhofer 2021] 和 ADOP [Rückert et al. 2022] 的渲染速度仍然作为激发因素,驱使作者开发出快速渲染解决方案。
接下来作者讨论了一些相关的工作:
- Neural Point Catacaustics [Kopanas et al. 2022]的特点:
- 该方法专注于处理镜面效果。在扩散点渲染方面,通过使用多层感知器(MLP),该方法克服了渲染过程中的时间不稳定性。然而,仍然需要多视图立体匹配(MVS)几何作为输入。
- 最新方法 [Zhang et al. 2022] 的特点:
- 在同一类别中,最近的方法[Zhang et al. 2022]不需要 MVS,并使用球谐(SH)来表示方向。然而,该方法只能处理单一物体的场景,并需要蒙版进行初始化。
- 尽管在小分辨率和低点数的情况下渲染速度较快,但对于典型数据集的场景如何扩展仍然不明确,特别是在处理典型数据集[Barron et al. 2022; Hedman et al. 2018; Knapitsch et al. 2017]时的表现。、
- 最新方法 [Xu et al. 2022] 的特点:
- 这一最新的方法使用点来表示一个辐射场,采用径向基函数方法。
- 在优化过程中,该方法采用了点修剪和稠密化技术。尽管采取了这些优化措施,但该方法仍然使用体积光线投射(volumetric ray-marching),无法达到实时显示速率。
- 作者的方法的优势:
- 作者采用了三维高斯分布作为更灵活的场景表示,避免了对MVS几何的需求,并通过瓦片渲染算法实现了对投影高斯分布的实时渲染。这使得他们的方法在实时渲染方面具有优势。
最后作者提到了自己为什么选择选择3D高斯分布:
- 在人体性能捕捉领域的应用:
- 3D高斯分布曾被用于表示捕捉到的人体[Rhodin et al. 2015; Stoll et al. 2011],最近还在视觉任务中与体积光线投射一起使用[Wang et al. 2023]。
- 在类似的背景下,一些方法提出了神经体积基元[Lombardi et al. 2021]。这些方法启发了选择3D高斯分布作为场景表示的决策。
- 对比与其他方法的区别:
- 虽然这些方法启发了选择3D高斯分布,但它们主要专注于重建和渲染单个孤立对象(如人体或面部),导致场景具有较小的深度复杂性。
- 与之相反,作者的方法通过优化各向异性协方差、交错的优化/密度控制以及有效的深度排序渲染,使其能够处理完整、复杂的场景,包括室内外背景,并具有较大的深度复杂性。
3 OVERVIEW
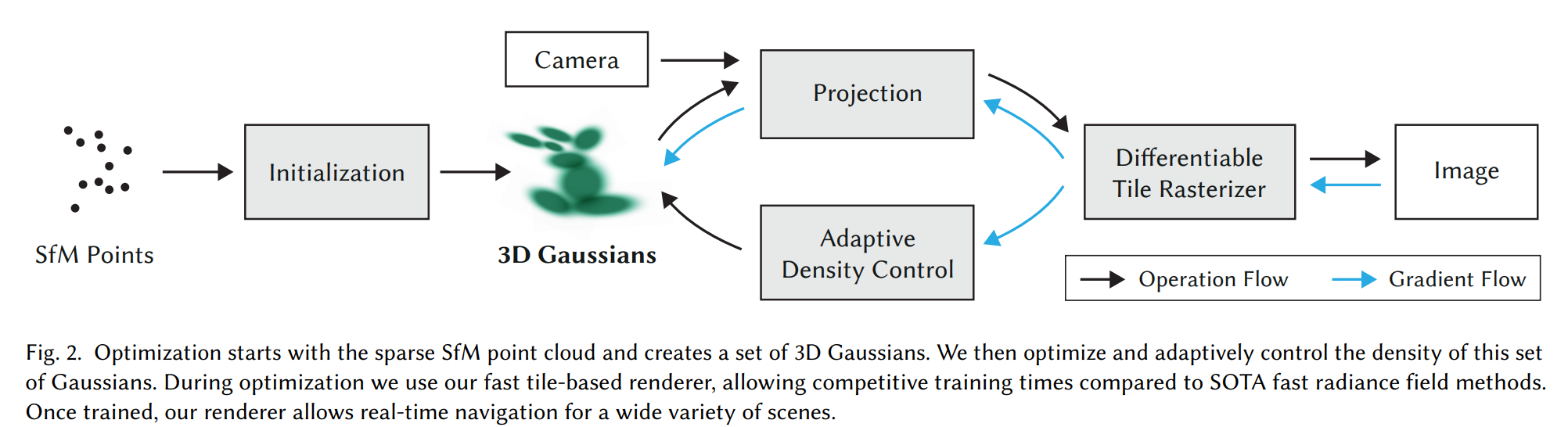
输入:
- 方法的输入是一个静态场景的图像集,以及由SfM(Structure from Motion)[Schönberger and Frahm 2016]校准的相应相机,这产生了一个稀疏点云。
- 从这些点中,创建了一组3D高斯分布,这些高斯分布由位置(均值)、协方差矩阵和不透明度 𝛼 定义,从而实现了非常灵活的优化过程。
场景表示:
- 使用3D高斯分布对场景进行表示,包括位置、协方差矩阵和不透明度 𝛼。这使得可以灵活地进行优化,并在一定程度上实现了对3D场景的紧凑表示。
- 利用各向异性的体积斑点可以紧凑地表示细小结构。
辐射场的方向外观组件:
- 辐射场的方向外观组件(颜色)通过球谐函数(SH)表示,符合标准实践[Fridovich-Keil and Yu et al. 2022; Müller et al. 2022]。
辐射场表示的创建:
- 算法通过一系列对3D高斯分布参数的优化步骤进行辐射场表示的创建,包括位置、协方差、𝛼和SH系数的交替操作,以及用于自适应控制高斯密度的操作。
方法的效率关键:
- 方法的效率关键在于其基于瓦片的光栅化器,它允许各向异性斑点的 𝛼-混合,并通过快速排序实现了对可见性顺序的尊重。
- 快速光栅化器还包括一个快速的反向传递过程,通过跟踪累积的 𝛼 值,而不限制可以接收梯度的高斯分布的数量。
方法概览:
优化起点:优化的起点是稀疏的SfM点云,该点云通过优化生成一组3D高斯分布。
密度自适应控制:对这组高斯分布进行密度的优化和自适应控制。
光栅化器的运用:在优化过程中,使用了快速基于瓦片的渲染器,使得训练时间与当前领先的快速辐射场方法相比具有竞争力。
训练后的渲染器:训练完成后,该渲染器能够实现对各种场景的实时导航,为用户提供高效的渲染性能。
4 DIFFERENTIABLE 3D GAUSSIAN SPLATTING
和GPT聊一聊$\exp\left(-\frac{1}{2} \mathbf{x}^T \boldsymbol{\Sigma}^{-1} \mathbf{x}\right)$,并且指定$\Sigma=RSS^TR^T$的情况下会发生什么。
链接:https://chat.openai.com/share/0cfb56e4-30a5-4bd8-9c23-89aa36660d7f
下面是聊的内容。
三维高斯分布的公式是什么?

假设$\mu=0$,忽略掉除了exp()之外的东西,写出这个表达式

忽略掉前面我们交流的内容,我们现在只看这个表达式: $\exp\left(-\frac{1}{2} \mathbf{x}^T \boldsymbol{\Sigma}^{-1} \mathbf{x}\right)$,请注意$x$是三维向量。这个表达式的几何意义是什么呢?

为了继续讨论,接下来我们定义旋转矩阵$R$,缩放矩阵$S$,请注意我们讨论的都是在三维空间下。

如果我令$\Sigma=RSS^TR^T$,那么此时的$\Sigma$对于高斯分布$\exp\left(-\frac{1}{2} \mathbf{x}^T \boldsymbol{\Sigma}^{-1} \mathbf{x}\right)$起了什么样的作用?

具体来说不同的$R$和$S$将如何影响这个高斯分布?

向量$x$对高斯分布有什么样的影响?

那么,再给定$\Sigma=RSS^TR^T$的前提下,$\exp\left(-\frac{1}{2} \mathbf{x}^T \boldsymbol{\Sigma}^{-1} \mathbf{x}\right)$其实就是表示了在位置$\mathbf{x}$处的一个高斯分布,而且这个高斯分布接近一个椭球,椭球的形状受到了旋转矩阵R和缩放矩阵S的影响,我这样理解对吗?

5 OPTIMIZATION WITH ADAPTIVE DENSITY CONTROL OF 3D GAUSSIANS
- 优化步骤核心:
- 论文方法的核心在于优化步骤,其目标是创建一个密集的3D高斯集合,以准确表示用于自由视角合成的场景。
- 参数优化:
- 优化的参数包括位置 (𝑝)、方向 (𝛼) 和协方差 (Σ)。
- 此外,还对代表每个高斯颜色 (𝑐) 的球谐系数(SH coefficients)进行优化,以正确捕捉场景的视角相关外观。
- 步骤交织:
- 这些参数的优化过程与控制高斯密度的步骤交织在一起。
- 通过这种方式,实现对高斯密度的精细控制,以更好地表示场景。
5.1 Optimization
- 基于迭代的优化过程:
- 优化的核心在于通过渲染和比较生成的图像与训练数据集中的视图进行迭代。
- 由于3D到2D投影的不确定性,可能导致几何元素被错误放置。
- 优化过程需要能够创建、破坏或移动几何元素,以纠正错误的位置。
- 3D高斯的协方差参数质量对表示的紧凑性至关重要,因为少量大型各向异性高斯可以捕捉大块均匀区域。
- 使用随机梯度下降的优化技术:
- 采用随机梯度下降技术,充分利用GPU加速框架和自定义CUDA内核。
- 快速光栅化是优化过程的主要计算瓶颈。
- 激活函数的选择:
- 对于方向𝛼,采用sigmoid激活函数,将其限制在 [0, 1) 范围内,并获得平滑的梯度。
- 对于协方差尺度,选择指数激活函数,同样是为了获得平滑的梯度。
- 初始协方差矩阵的估计和损失函数设计:
- 估计初始协方差矩阵时,采用各向同性高斯,其轴长度由到最近的三个点的距离均值确定。
- 使用标准的指数衰减调度技术,但仅用于位置参数。
- 损失函数包括L1损失和D-SSIM项的组合,通过权衡参数𝜆 = 0.2进行组合。
- 有关学习调度和其他细节,详细信息可在第7.1节中找到。
通过以上步骤,优化过程能够克服3D到2D投影的不确定性,通过迭代优化提高场景表示的准确性,并通过自适应密度控制的手段灵活处理几何元素的位置,以实现更精确的场景合成。
5.2 Adaptive Control of Gaussians
初始步骤:
- 从Structure from Motion(SfM)获取初始稀疏点集。
- 通过自适应控制,调整高斯的数量和密度,从初始的稀疏高斯集合过渡到更密集的集合。
重点区域的控制:
自适应控制着眼于两种关键区域:
- “under-reconstruction”区域,即缺乏几何特征的区域。
- 针对这些区域,自适应控制通过克隆操作调整高斯,以覆盖新创建的几何,确保这些区域能够得到更好的表示。
- “over-reconstruction”区域,即高斯覆盖大面积的区域。
- 针对这些区域,通过分割操作将大的高斯替换为两个较小的高斯,以更好地适应场景中的细节和变化。
在这两种情况下,区域的视角空间位置梯度被用来指导高斯的调整,因为这些区域可能是场景中尚未充分重建或者已经过度重建的部分。
- “under-reconstruction”区域,即缺乏几何特征的区域。
密集化操作的条件:
- 高斯密集化的条件是,具有视角空间位置梯度的平均幅度超过阈值 𝜏pos。
- 阈值设置为0.0002。
高斯调整的具体步骤:
- 对于小高斯,位于“under-reconstructed”区域,通过克隆操作覆盖新创建的几何。
- 对于大高斯,位于高方差区域,通过分割操作替换为两个新的高斯,同时将它们的尺度缩小一个经验确定的因子 𝜙 = 1.6。
对高斯数量的控制:
- 处理两种情况:一种增加系统总体积和高斯数量,另一种保持总体积不变但增加高斯数量。
- 避免浮点数接近输入相机时导致高斯密度不合理地增加的问题。
- 通过每3000次迭代将 𝛼 值设置接近零,然后根据需要增加 𝛼 值,并通过裁剪方法删除 𝛼 值小于 𝜖𝛼 的高斯。
- 定期删除在世界空间中非常大或在视图空间中占据大面积的高斯,以有效控制总高斯数量。
高斯的基本性质:
- 高斯在Euclidean空间中保持为基元,不需要采用复杂的空间压缩、变形或投影策略。
- 与其他方法不同,该模型不要求对远距离或大型高斯采取额外处理的方法,保持了高斯在欧几里得空间中的基本特性。
- 这一特点使得模型更加直观和可理解,同时简化了整个处理流程,避免了复杂的空间变换对场景表示的不必要干预。
通过这一自适应控制的过程,能够更好地适应场景的几何特征,同时有效地控制高斯的数量和密度,确保了场景表示的准确性。
6 FAST DIFFERENTIABLE RASTERIZER FOR GAUSSIANS
- 设计目标和渲染流程概述:
- 设计目标:实现快速渲染和排序,支持 𝛼 混合和各向异性斑点。
- 提出瓦片光栅化器,避免每像素排序的开销。
- 允许处理任意深度复杂度的场景,无需特定超参数调整。
- 瓦片光栅化流程:
- 屏幕划分为16×16瓦片,3D Gaussians剔除和实例化。
- 利用GPU Radix排序,避免额外的每像素排序。
- 混合基于初始排序,无额外每像素排序,提高效率。
- 优化和并行处理:
- 利用瓦片列表生成,线程块协同加载数据包。
- 并行处理数据加载/共享和处理,周期性检查线程和像素饱和,终止瓦片处理。
- 详细优化:
- 利用共享内存协同加载数据包,提高数据加载效率。
- 定期检查线程和像素饱和,提前终止瓦片处理,节省计算资源。
- 处理深度复杂度:
- 允许任意深度复杂度的场景,无需特定超参数调整。
- 反向传播中通过遍历瓦片列表处理混合点序列,增加模型灵活性。
- 详细处理:
- 反向传播期间,通过遍历瓦片列表处理混合点序列,适应不同深度复杂度的场景。
- 高效的反向传播:
- 从最后影响像素的点开始遍历,协同加载数据到共享内存。
- 优化:像素只处理深度低于或等于正向传播期间为其颜色做出贡献的最后一个点。
- 通过存储正向传播结束时的总累积不透明度,恢复中间不透明度,减少计算复杂性。
- 详细反向传播优化:
- 从最后影响像素的点开始遍历,协同加载数据到共享内存,提高效率。
- 优化像素处理,只处理正向传播期间对颜色有贡献的点。
- 存储总累积不透明度,通过反向遍历计算中间不透明度,降低计算复杂性。
7 Limitations
- 有限观测区域的问题:
- 在场景观测不充分的区域可能出现伪影。
- 其他方法在类似情况下也存在困难,例如Mip-NeRF360的情况。
- 各向异性高斯的缺陷:
- 各向异性高斯在某些情况下可能生成细长伪影或“斑点状”高斯。
- 先前的方法在类似情况下也存在困难。
- 大高斯生成的爆裂伪影:
- 在创建大高斯时,可能偶尔出现“爆裂”伪影,尤其是在具有视角相关外观的区域。
- 爆裂伪影的一个原因是在光栅化器中通过防护带微不足道地拒绝高斯,引入更有原则的剔除方法可能有助于减轻这些伪影。
- 另一个因素是简单的可见性算法,可能导致高斯突然切换深度/混合顺序,这可以通过引入抗锯齿技术解决,但这是留作未来工作的。
- 缺乏优化的正则化:
- 目前的优化过程没有应用任何正则化,这可能有助于处理未观测区域和爆裂伪影。
- 引入正则化被提出作为解决方案,有望改善这些问题。
- 同一超参数的使用:
- 尽管在完整评估中使用了相同的超参数,早期实验表明,在非常大的场景(如城市数据集)中,减小位置学习速率可能是为了收敛而必要的。
- 相对紧凑但内存消耗较高:
- 尽管与之前的基于点的方法相比,方法相对紧凑,但内存消耗明显高于NeRF等基于神经场景的解决方案。
- 优化逻辑的低级实现可能显著减少内存消耗。
- 训练和渲染的内存需求:
- 渲染经过训练的场景需要足够的GPU内存来存储完整模型,以及额外的内存用于光栅化器。
- 存在许多降低内存消耗的机会,包括点云的压缩技术,这个领域是一个研究方向。
8 DISCUSSION AND CONCLUSIONS
- 创新性贡献:
- 提出了首个真正允许在各种场景和捕捉风格中进行实时、高质量辐射场渲染的方法。
- 选择了3D高斯原语,既保留了优化的体积渲染特性,又直接实现了快速的基于splat的光栅化。
- 培训时间和性能:
- 在培训时间方面与先前最快的方法相竞争,证明了方法的高效性。
- 大约80%的培训时间用于Python代码,为了方便其他人使用,方法构建在PyTorch上。
- 只有光栅化例程实现为优化的CUDA核。将其余优化完全移植到CUDA可能会在对性能要求很高的应用中实现显著的加速,例如InstantNGP。
- 实时渲染原则:
- 展示了建立在实时渲染原则之上的重要性,充分利用GPU的性能和软件光栅化管线架构的速度。
- 这些设计选择是培训和实时渲染性能的关键,相对于先前的体积射线行进提供了竞争优势。
- 未来研究方向:
- 探讨了高斯是否可用于执行捕捉场景的网格重建,以更好地了解方法在体积和表面表示之间的确切位置。
- 强调了对于网格的广泛使用,这可能具有实际意义。
- 结论:
- 提出了首个实时辐射场渲染解决方案,其渲染质量与昂贵的先前方法相匹配,培训时间与最快的现有解决方案相竞争。
相关链接
下面是一些可能有用的链接:
3D Gaussian Splatting中的数学推导 - 八氨合氯化钙的文章 - 知乎
https://zhuanlan.zhihu.com/p/666465701这篇文章非常不错,基本所有需要的公式推导都在这里了
[NeRF坑浮沉记]3D Gaussian Splatting入门:如何表达几何 - 御币Soft的文章 - 知乎
https://zhuanlan.zhihu.com/p/661569671这篇文章提到了一个以椭球为基础元素的游戏,很直观的感受了一下用椭球表达场景是什么样子
Splatting 抛雪球法简介 - bo233的文章 - 知乎
https://zhuanlan.zhihu.com/p/6605129163D Gaussian Splatting这篇论文的公式是真的少,Splatting这部分可以借助这篇文章了解一下
《3D Gaussian Splatting for Real-Time Radiance Field Rendering》3D高斯的理论理解 - 剪月光者的文章 - 知乎
https://zhuanlan.zhihu.com/p/664725693可以作为前面对3D Gaussian的补充
A beginner friendly introduction to 3D Gaussian Splats and tutorial on how to train them
https://www.reshot.ai/3d-gaussian-splatting
一个很详细的教程,虽然3D Gaussian Splatting的README写的也很详细



