DUSt3R 基础
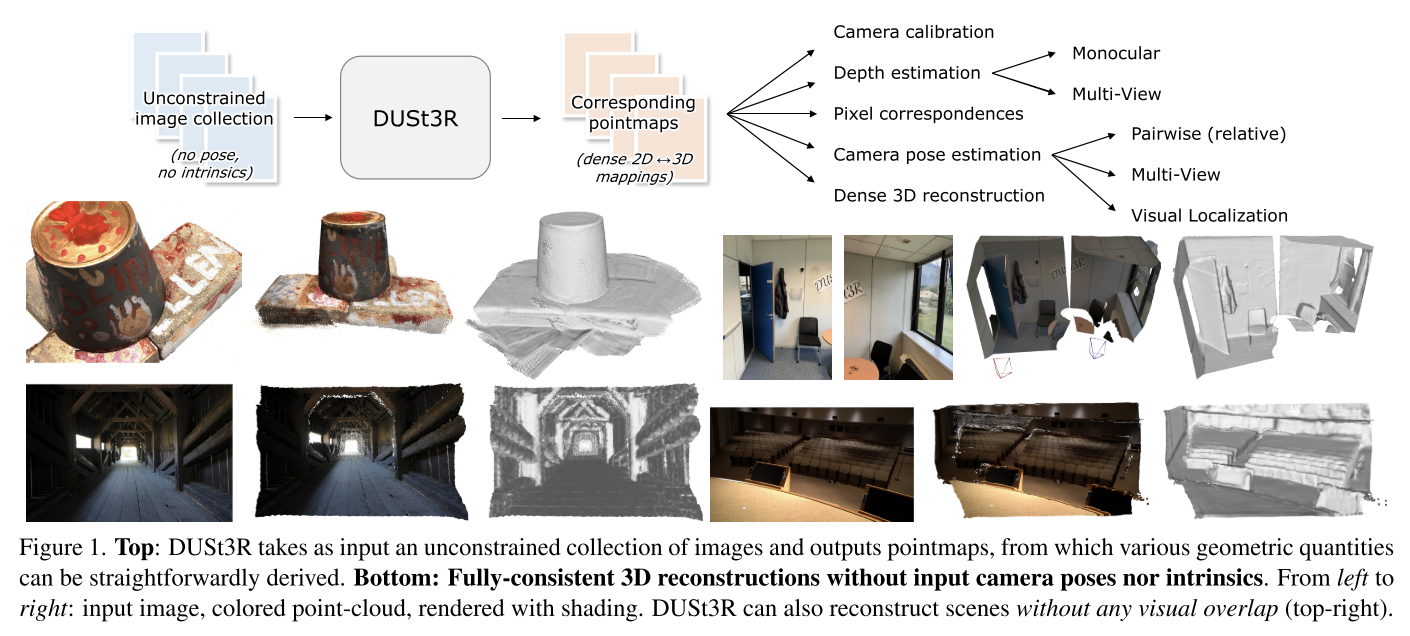
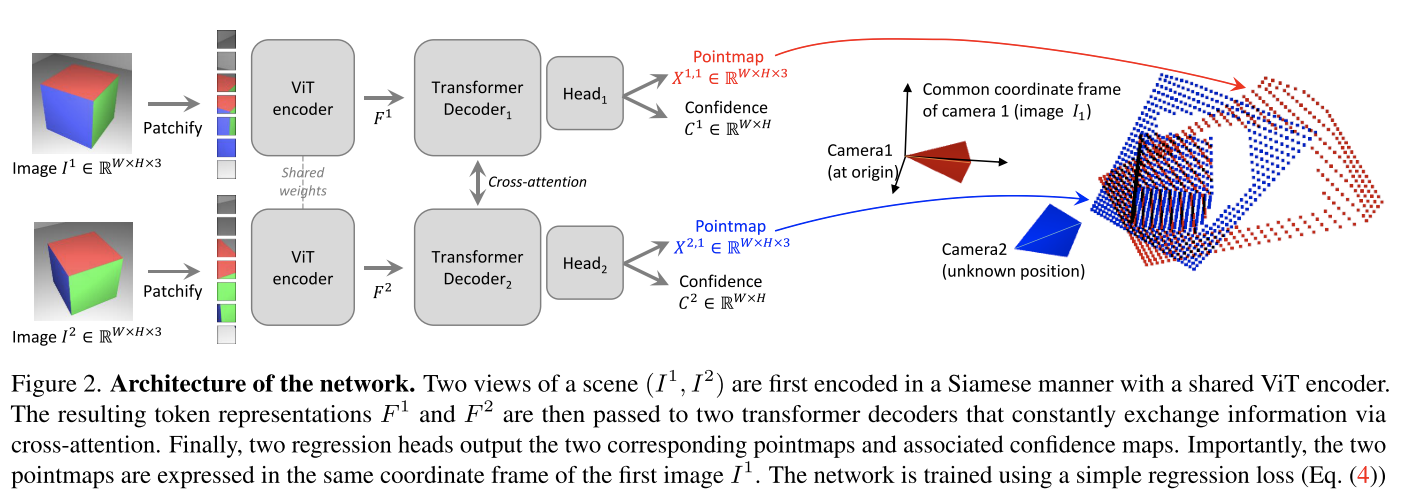
DUSt3R: Geometric 3D Vision Made Easy
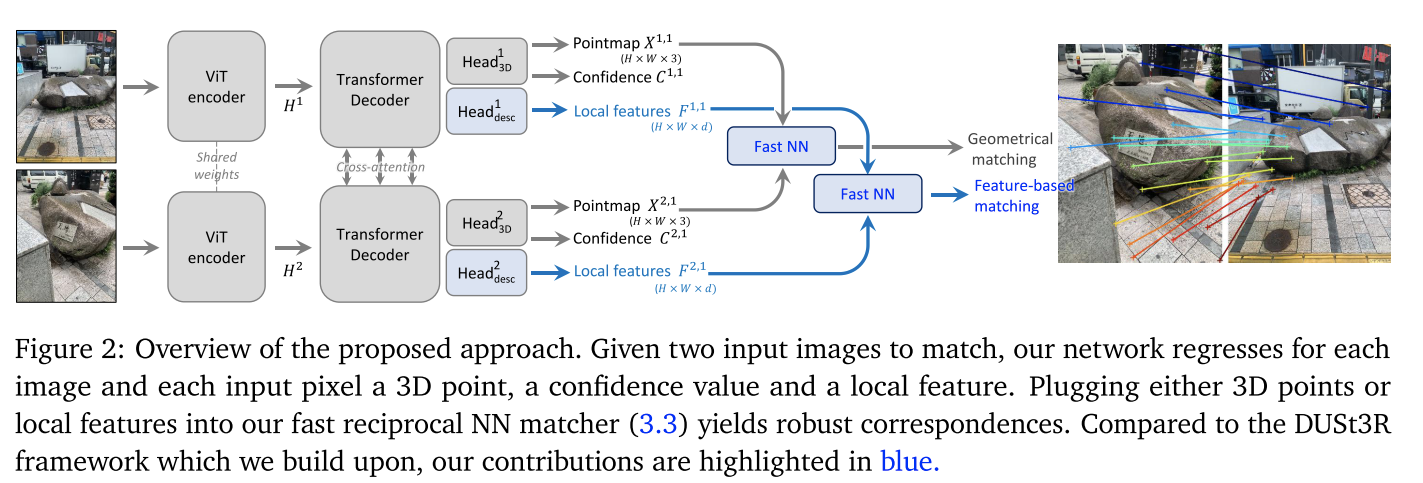
Grounding Image Matching in 3D with MASt3R
DUSt3R相关工作
MASt3R-SfM: a Fully-Integrated Solution for Unconstrained Structure-from-Motion
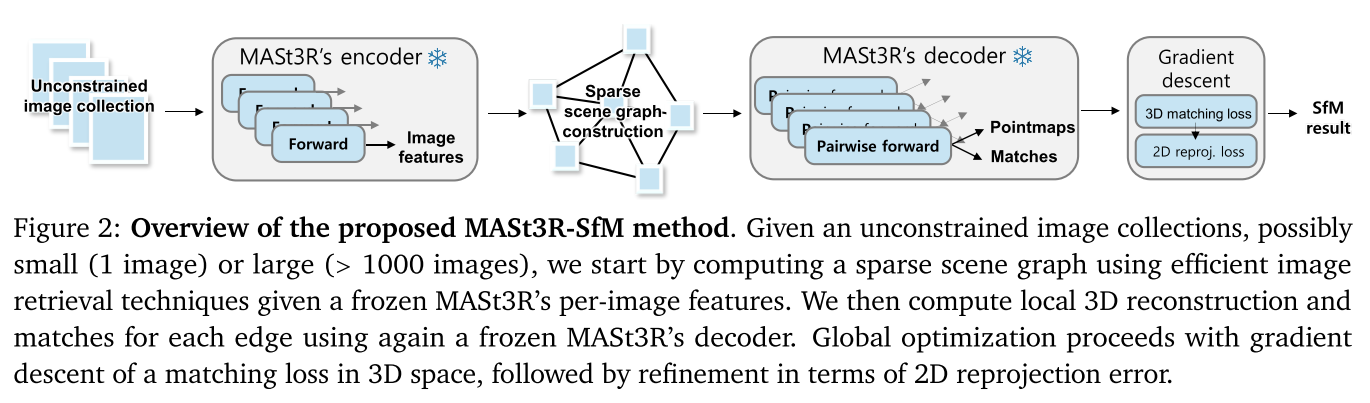
这个工作像我们之前做的项目,用dust3r来做,也是构建了合理的image pair去重建。
MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors
这篇论文用了很多mast3r-sfm里面的东西。
**motivation: **However, SLAM is yet to become a plug-and-play algorithm as it requires hardware expertise and calibration. Even for a minimal single camera setup with no additional sensing such as an IMU, a SLAM solution that reliably provides both accurate poses and consistent dense maps in-the-wild does not exist. Achieving such a reliable dense SLAM system would open new research avenues for spatial intelligence.
**slam和sfm相比: **While previous work has applied these priors to SfM in an offline setting with unordered image collections [10], SLAM receives data incrementally and must maintain real-time operation. This requires new perspectives on low-latency matching, careful map maintenance, and efficient methods for large-scale optimisation.
**pipeline: **本质上这是一个传统的SLAM方法,mast3r取代了其中深度获取、feature计算、回环检测的功能。也没有对mast3r进行训练。
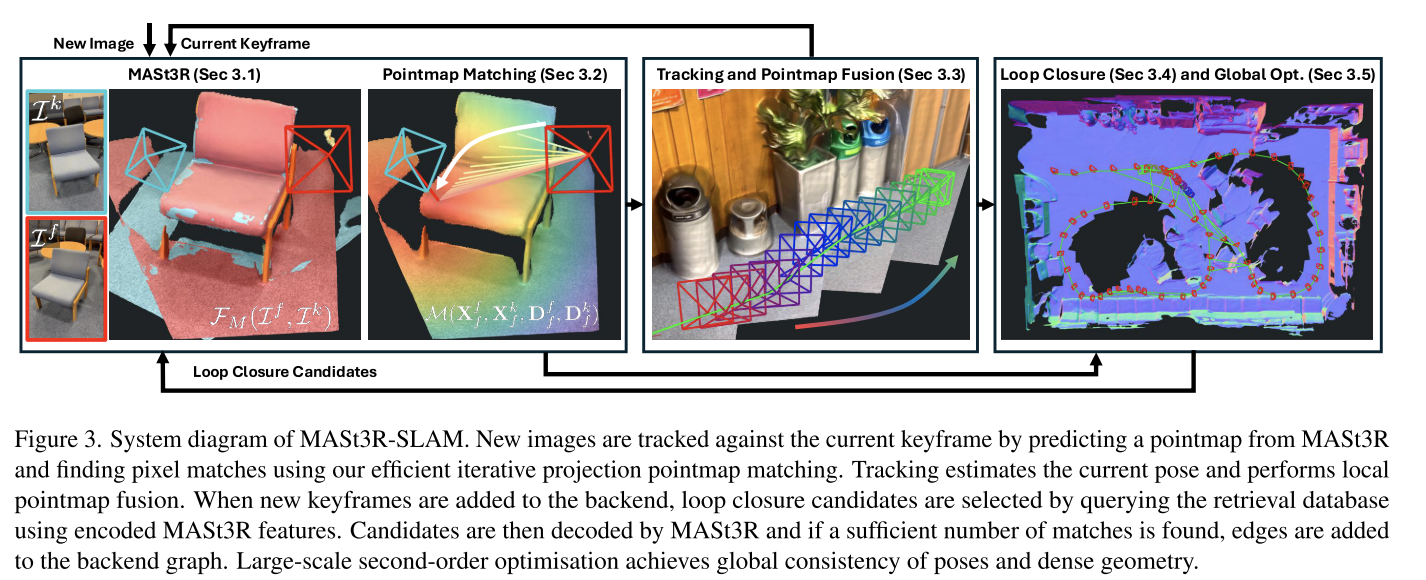
Pointmap Matching
这部分比较有意思,不过思路非常简单,先通过投影优化得到一个粗匹配,再根据feature实现细匹配。这个算法可以用cuda实现并行化,速度非常快。比mast3r论文里面的fast nn快不少。

不过这也导致这篇论文引入了一个假设:相机必须要有一个唯一的光心。

Tracking and Pointmap Fusion

Tracking部分,最小化3D点误差可能没有那么鲁棒,因为深度预测不一致的情况是频繁的。所以论文基于上面这个公式进行了修改,还是像Pointmap Matching那样计算directional ray error:
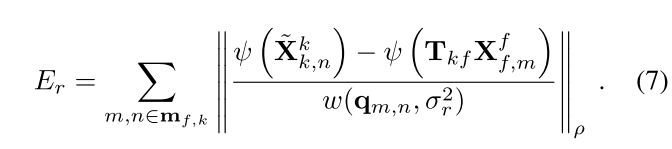
最终,位姿求解通过下面的公式:

Pointmap Fusion部分,论文提到初始的pointmap具有较大的误差和较低的置信度,他们尝试了各种方法,最后发现加权平均最适合在过滤噪声的同时保持一致性。因此通过如下的公式来进行pointmap fusion:
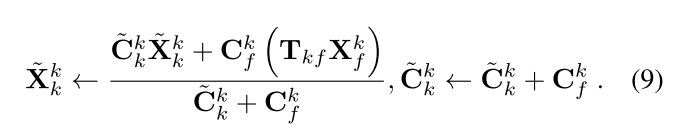
Graph Construction and Loop Closure
关键帧添加标准:valid matches数量低于阈值,或者unique keyframe pixels低于阈值(这里不太理解,可能得看代码了);
通过mast3r-sfm使用的ASMK框架来从encoded features中检索图像,实现loop detection;
检索分数高于阈值,将encoded features pair提交给mast3r decoder,如果根据Pointmap Matching的结果匹配数量高于阈值,则添加双向边。
Backend Optimisation
这部分的目的是保证位姿和几何形状的全局一致性。
公式写大了,编号挤下去了哈哈哈哈哈
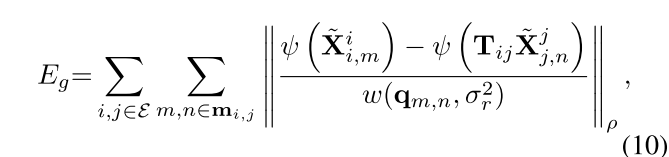
Relocalisation
做的比较传统,跟丢之后查数据库,查到有匹配的帧再添加新的边到graph中。
Known Calibration
从实验来看,这个对位姿精度提升比较大,但是对重建的精度提升有限。
论文做的和我想得差不多,利用相机内参来调整pointmap,反向投影,并且在像素空间上计算残差。

Limitations and Future Work
论文提到的这个点很有意思:While we can estimate accurate geometry by filtering pointmaps in the frontend, we do not currently refine all geometry in the full global optimisation. While DROIDSLAM optimises per-pixel depth via bundle adjustment, this framework permits incoherent geometry. A method that can make pointmaps globally consistent in 3D while retaining the coherence of the original MASt3R predictions all in real-time would be an interesting direction for future work.
现在我们还只能拿mast3r出来的pointmap稍加调整,用于重建,但是这些点真的对吗?这些点如果不对,应该怎么去进行调整呢?
最简单的思路:加入3DGS,通过渲染的误差来优化点的位置,还能够生成新的点。。。
复杂点的思路目前暂时没有了。
SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
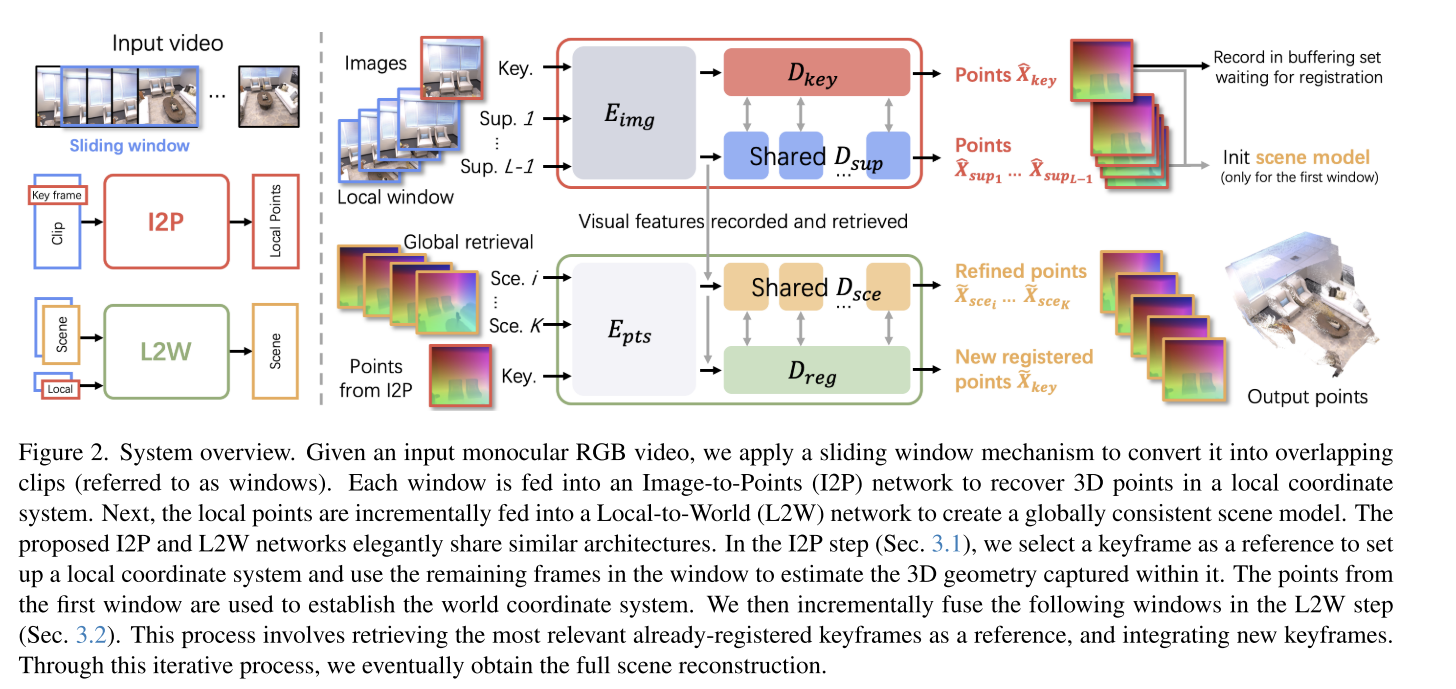
这篇文章做的还是非常有意思非常新颖的。
I2P和L2W都是基于dust3r的。I2P相当于原始的dust3r,根据图像得到点云;而L2W相当于点云版本的dust3r,根据scene和local得到融合后的scene。
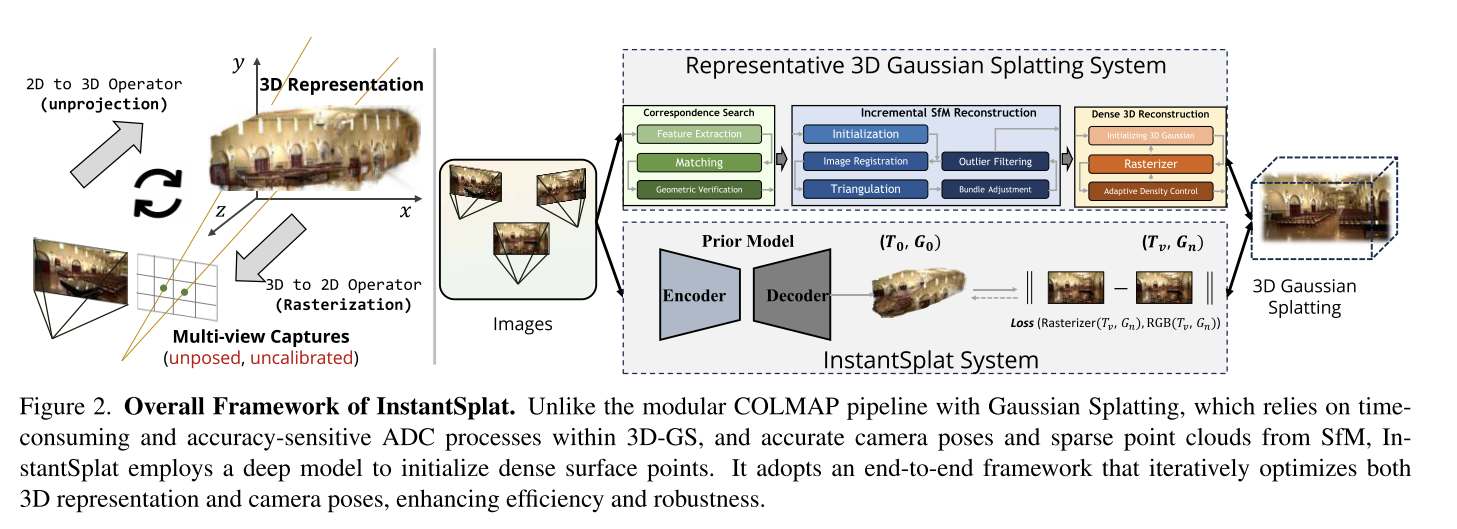
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
这看着只是把dust3r拿过来用了一下。
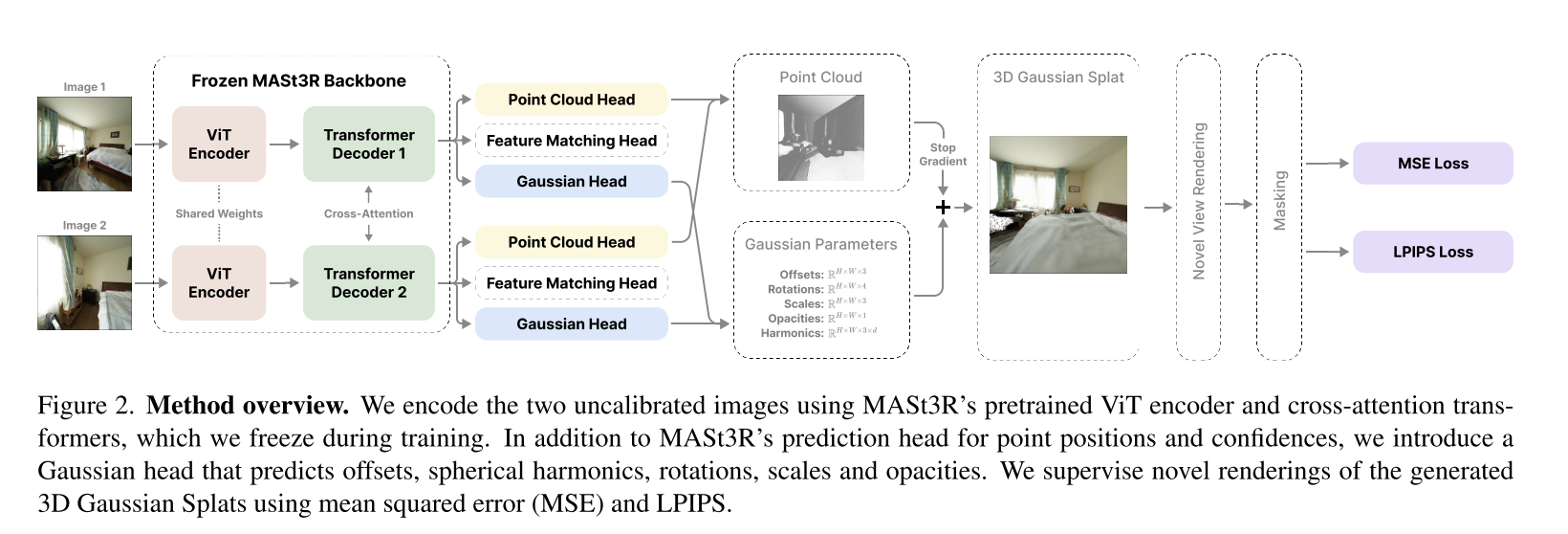
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
这个做的比InstantSplat有意思,添加了一个Gaussian Head
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
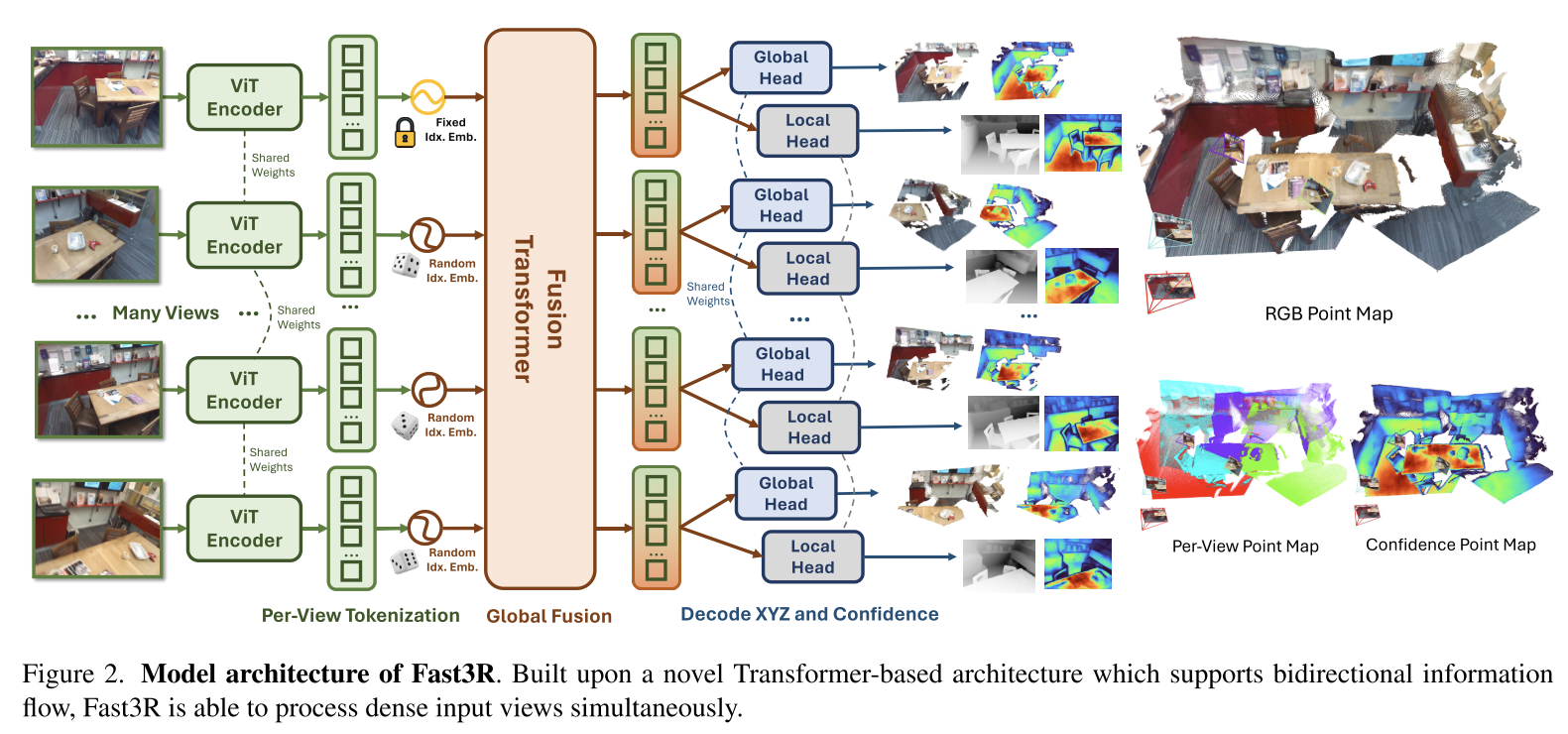
关于Fusion Transformer

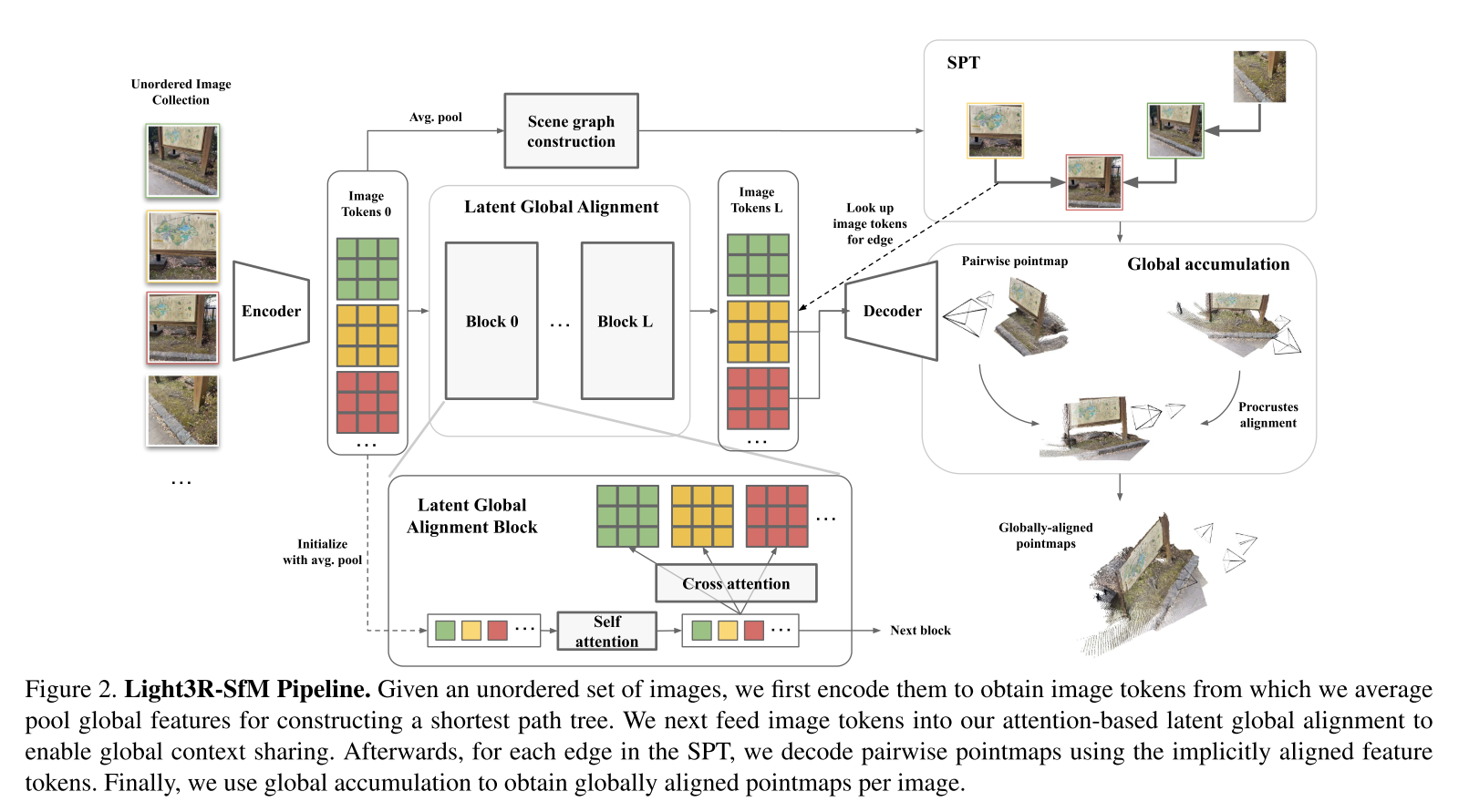
Light3R-SfM: Towards Feed-forward Structure-from-Motion
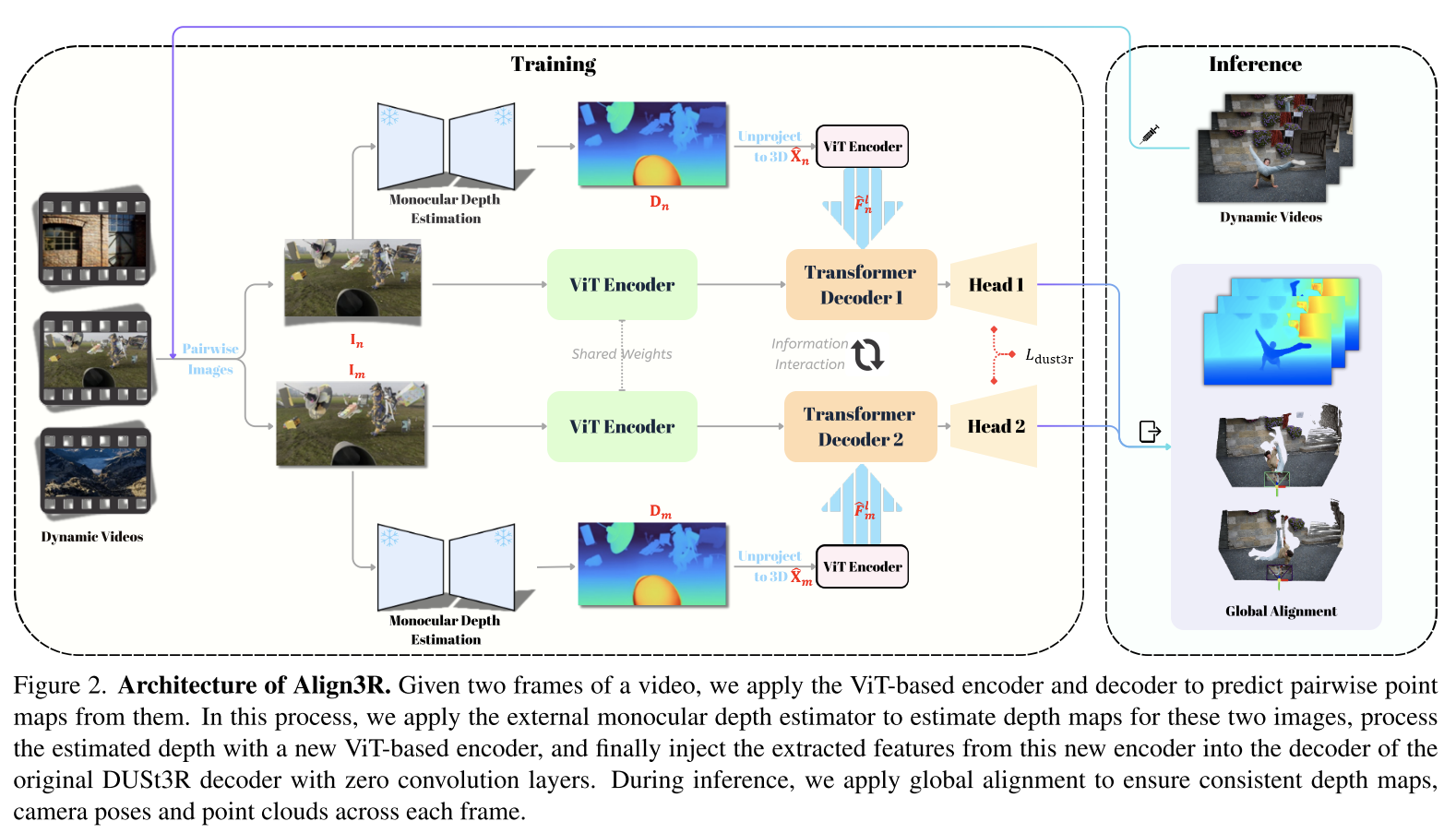
Align3R: Aligned Monocular Depth Estimation for Dynamic Videos
这和Pow3R做的好像啊。不过这个工作可以从视频中估计一致性的深度、点云和相机姿态。
人家Pow3R更关注怎么利用额外的信息提升重建精度。
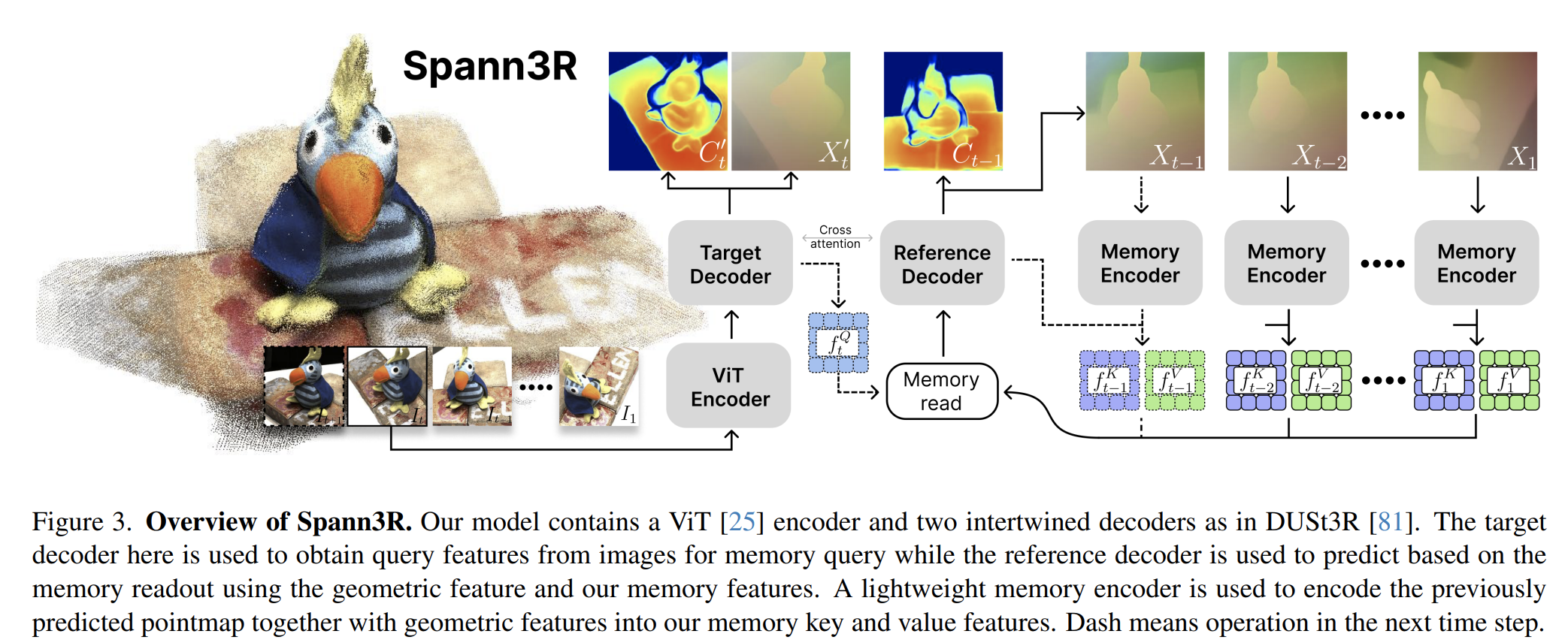
Spann3R: 3D Reconstruction with Spatial Memory
从哪里看到对Spann3R的评价,说这个工作比较适合对物体进行重建,对场景的重建效果很不好。
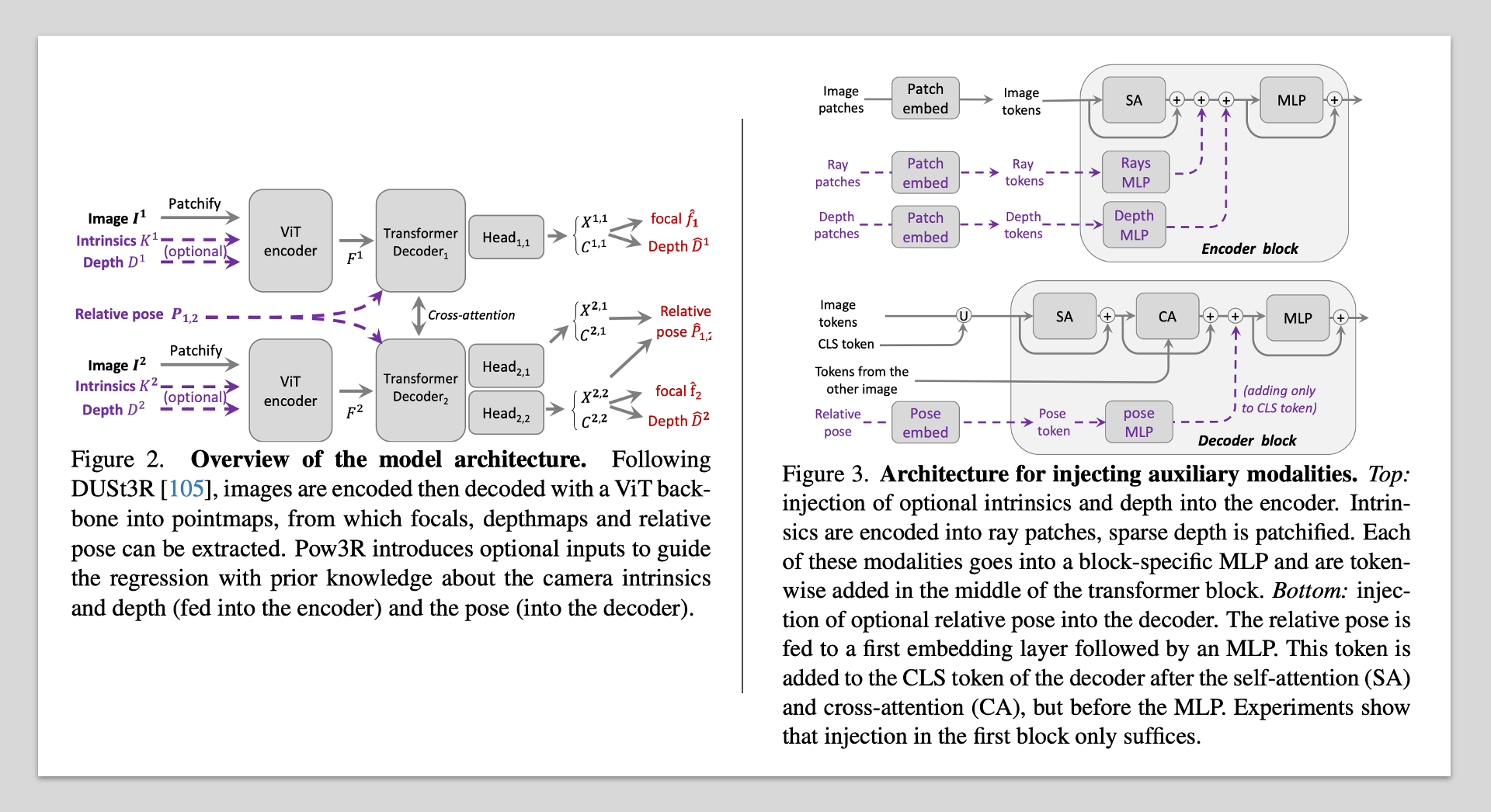
Pow3R: Empowering Unconstrained 3D Reconstruction with Camera and Scene Priors
Dust3R不需要camera内外参信息就能完成重建,但如果在应用中有已知的内外参或稀疏深度可以在Dust3R的基础上继续提高吗?Pow3R对Dust3R的结构加装了额外模块,带来了一些提升,但也只有一点点🤏🏻