VGGT: Visual Geometry Grounded Transformer
Motivation & Contributions
Motivation:3D视觉研究中,模型通常被限制用于处理单个任务,但这样很多时候还需要使用visual geometry optimization的方法来得到可以用的效果。VGGT希望在此做出改变,从一组场景的图像,直接预测这组图像的3D属性。
Contributions:To summarize, we make the following contributions:
- We introduce VGGT, a large feed-forward transformer that, given one, a few, or even hundreds of images of a scene, can predict all its key 3D attributes, including camera intrinsics and extrinsics, point maps, depth maps, and 3D point tracks, in seconds.
- We demonstrate that VGGT’s predictions are directly usable, being highly competitive and usually better than those of state-of-the-art methods that use slow post-processing optimization techniques.
- We also show that, when further combined with BA post-processing, VGGT achieves state-of-the-art results across the board, even when compared to methods that specialize in a subset of 3D tasks, often improving quality substantially.
我对第三点非常好奇,与BA后处理相结合,是怎么做的,似乎没有开源的代码。这个我必须去github提issue,询问一下!
Method
简单明了的Architecture Overview👍
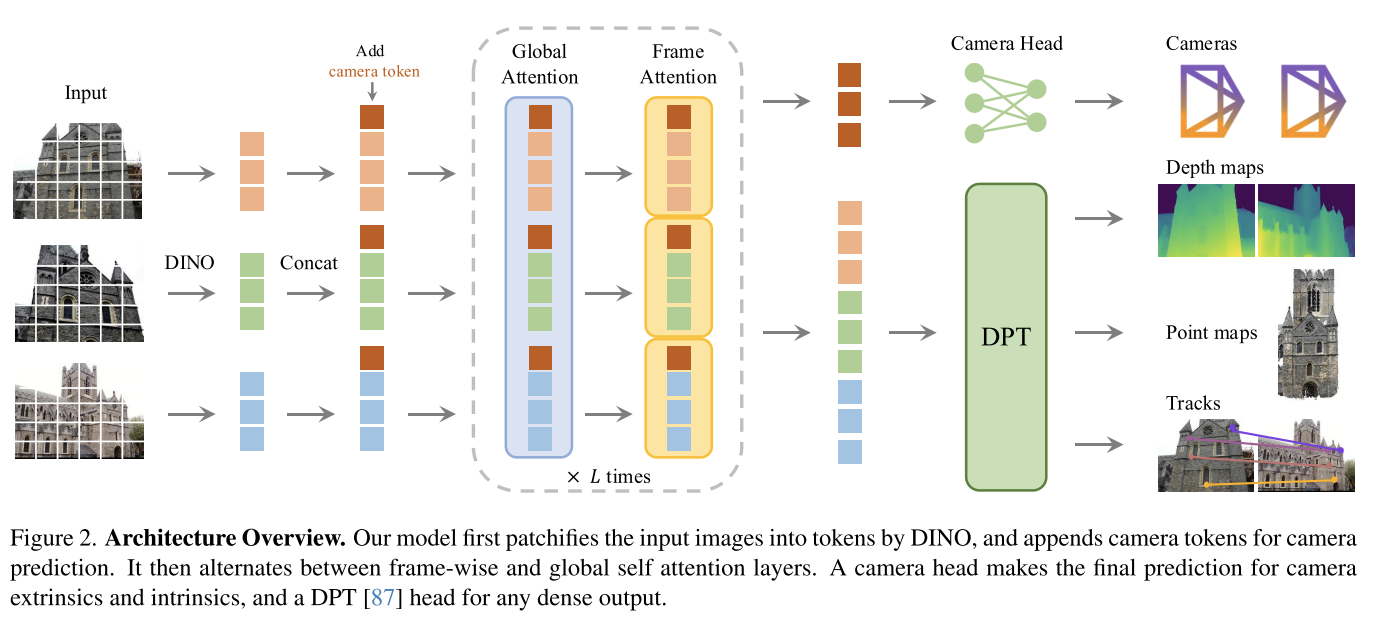
Problem definition and notation

一个可能比较关键的信息,网络架构被设计为,除了第一帧之外,所有帧不管怎么排序都是等价的。这是否说明,第一帧(参考帧)的选取,比较关键?

Feature Backbone
略,论文里面有非常详细的介绍,直观易懂
Prediction heads
略,论文里面有非常详细的介绍,直观易懂
Training
Training Loss

Ground Truth Coordinate Normalization
这部分提了一个比较有意思的点:Importantly, unlike DUSt3R, we do not apply such normalization to the predictions output by the transformer; instead, we force it to learn the normalization we choose from the training data.
作者强迫VGGT去学习作者从训练数据选择的normalization,而不是像DUSt3R一样把归一化应用到网络的输出上。这是否说明,对于同一组数据,VGGT每次预测的输出,基本是一样的呢?
Implementation Details
训练的输入是随机的2-24帧;
训练使用了64张A100,花了9天时间。
Training Data

Experiments
VGGT+BA的效果是最好的,不过花费额的时间可能会稍微长一点。
得去找找BA的代码才行!!!
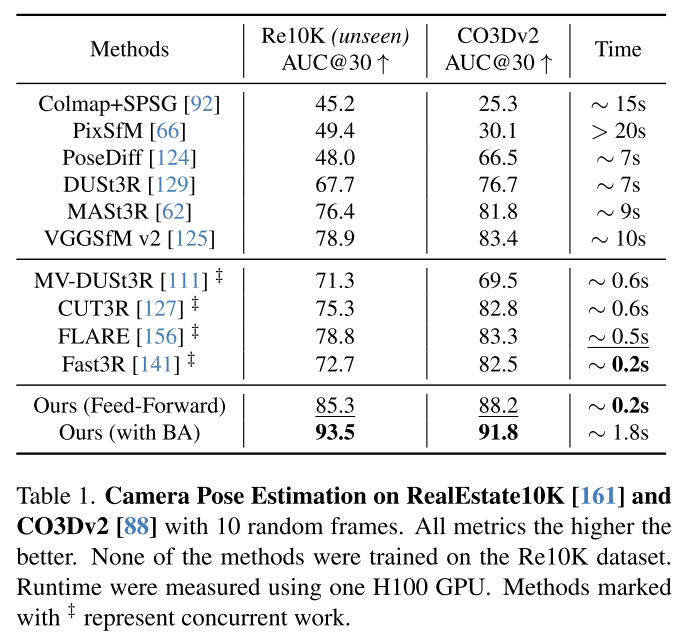
此外,从下面这个实验来看,预测local geometry + pose的结果比预测global geometry要好。
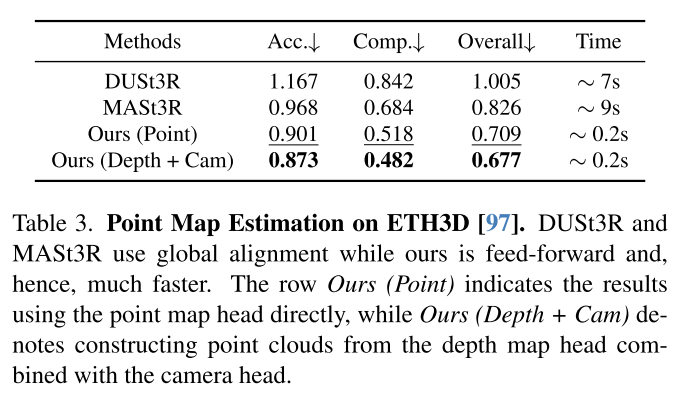
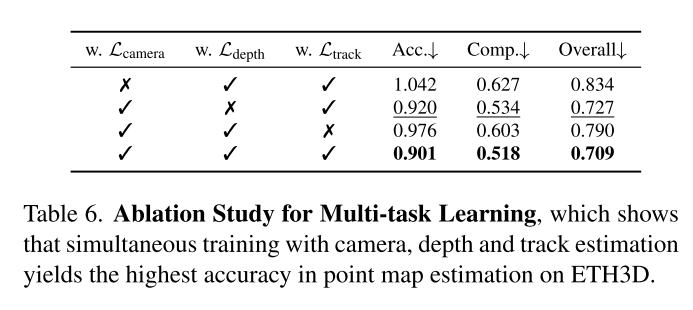
从消融实验来看,就像建元汇报说的那样,如果没有track,指标会下降。
其他的实验看论文吧~
Discussions
这部分作者写了很多,非常值得看一看。
Limitations
- 不支持鱼眼、全景图像
- 极端的旋转会导致重建性能下降
- 大量的非刚性形变会在导致重建失败
不过作者说微调可以解决这些问题。
Runtime and Memory

这里提到一些比较值得关注的信息:
VGGT可以自由选择不同的branch,其中camera head是lightweight,只占用5%的运行时间和2%的GPU memory
作者之前提到过:
VGGT模型训练好之后,加了一个类似于Lora的层,做一些简单的fine tune
把gt camera作为input,通过简单的MLP层inject进去,这样的information injection,最后的accuracy可以提高的非常高。
这个实验可以证明,这个模型是可以有up bound的。
DPT heads可以逐帧预测,这样可以节省GPU内存占用
Patchifying
DINOv2 model

Differentiable BA
看起来,VGGT的BA和VGGSfM的BA是差不多的?
不过作者提到尽管Differentiable BA表现了良好的性能,但是会导致每个training step慢4倍。
作者提到尽管他们选择在VGGT中不包含Differentiable BA,但是这也是大规模无监督训练的一个有前途的方向,可以在缺乏明确3D注释的场景中作为有效的监督信号!
Single-view Reconstruction
与DUSt3R和MASt3R不同的是,VGGT不需要duplicate single image。
Normalizing Prediction
作者对training data做了normalization,作者的观点是:像DUSt3R这样把归一化用在网络预测的工作,不是收敛所必需的,也不利于最终的模型性能,可能会在训练阶段引入额外的不稳定性。
个人总结
论文写的挺好的。这篇工作非常有挖掘的潜力,简单的网络结构,简单的loss function,大道至简。
整理一下作者演讲时提到的内容:
Pairwise Design这种方法在深度学习时代有一个问题,很难全局训练整个场景,有一种路线是训练的时候per pair,测试的时候把多个pair的结果fusion起来,这样效果很好,但模型本身是见不到这个场景的;另一个路线是训练的时候对每一个pair进行fusion,但是作者之前做过一些尝试,这样的尝试对GPU Memory的负担太大了,作者认为不是一个可行的方案。
整个框架中,最特质化的是Alternating-Attention

为什么用global attention呢,因为多帧输入,我们希望多帧输出也很简单。
为什么需要frame attention呢,有两个原因:
直觉上,大量的global self attention层会让模型confused,tokens的信息会在场景的层面上被平均。
另外一个更重要的原因是,不希望用frame index做position embedding,这涉及到permutation equivariant的问题。
当输入多张图片重建整个场景的时候,重建的顺序不应该随着图片输入的顺序而改变的,这是一个很重要的性质。
如果给transformer用frame index embedding,这样的性质无法保证。
所以得用Frame Attention,让模型自发的学习每一帧特征聚类。
这种完全tokenize化的设计,以及Frame Attention保证了训练的时候可以用随机的帧数进行训练。测试的时候模型展现了很好的泛化能力。

即使从来没有训练过VGGT学习single view task,但是VGGT的表现和领域内的SOTA基本相当。
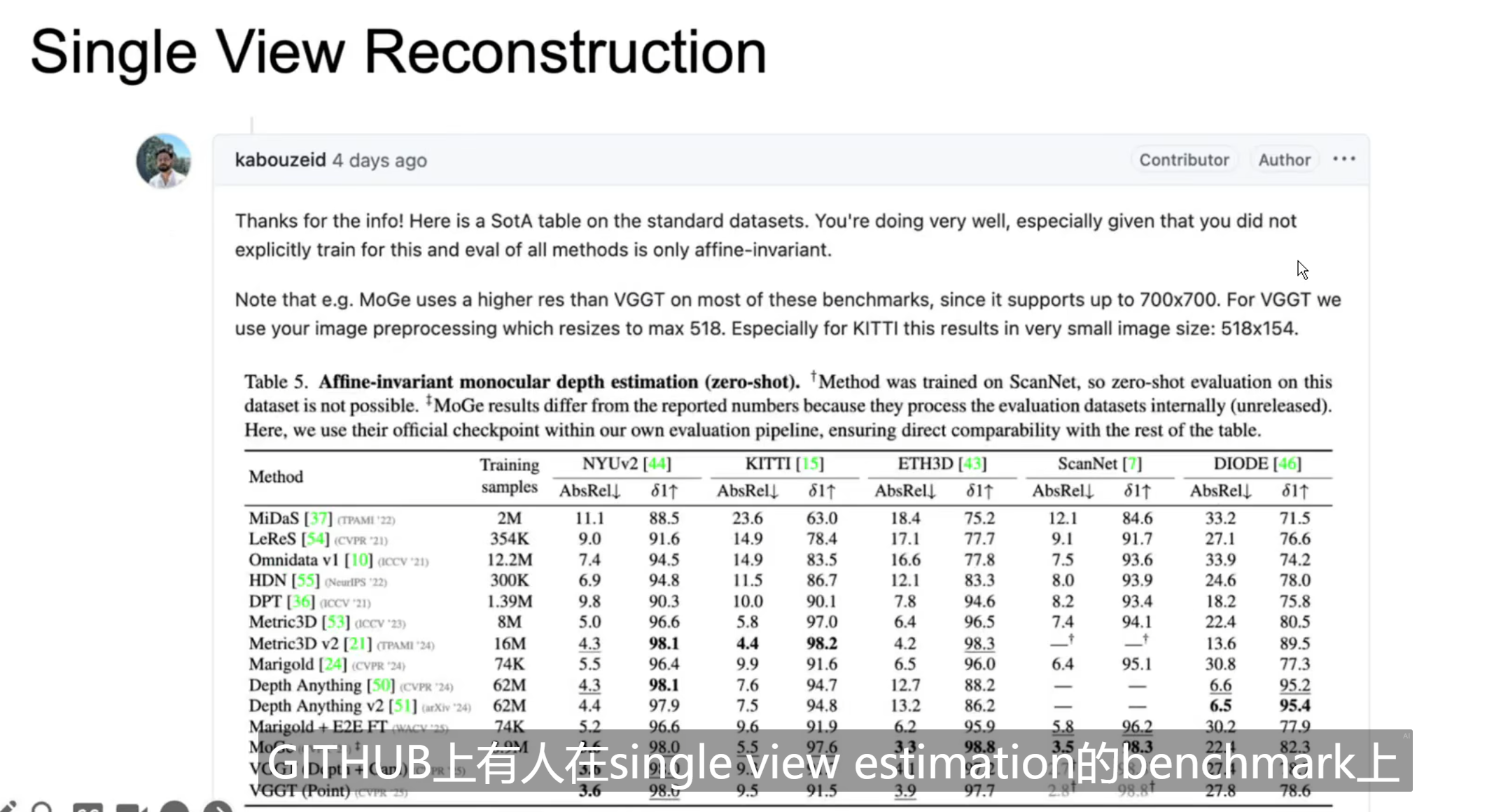
作者的理解:由于Alternating-Attention的设计,当输入的图片为1的时候,不需要duplicate这张图片,global attention会自然的退化为frame wised attention,保证了VGGT的泛化性。
和浙大彭思达交流这个问题,彭的意见是:很可能是因为多帧训练消除了monocular supervision的ambiguity,所以模型反而学得更好。这个可能会对monocular depth领域有一些新的启发。



