Visual Geometry Grounded Deep Structure From Motion
Motivation
近期SfM的工作仅仅是通过深度学习来增强SfM中的特定流程,但整理的pipeline还是原始的、不可微分的。
因此,这篇文章想要提出一种新的pipeline,即VGGSfM,其中每一个component都是fully differentiable!
Problem Setting
对于一组无序图像,VGGSfM估计相机内外参数和场景的点云。

Method
这部分写的还挺好的,嘎嘎截图就好了,都能看懂。
Overview
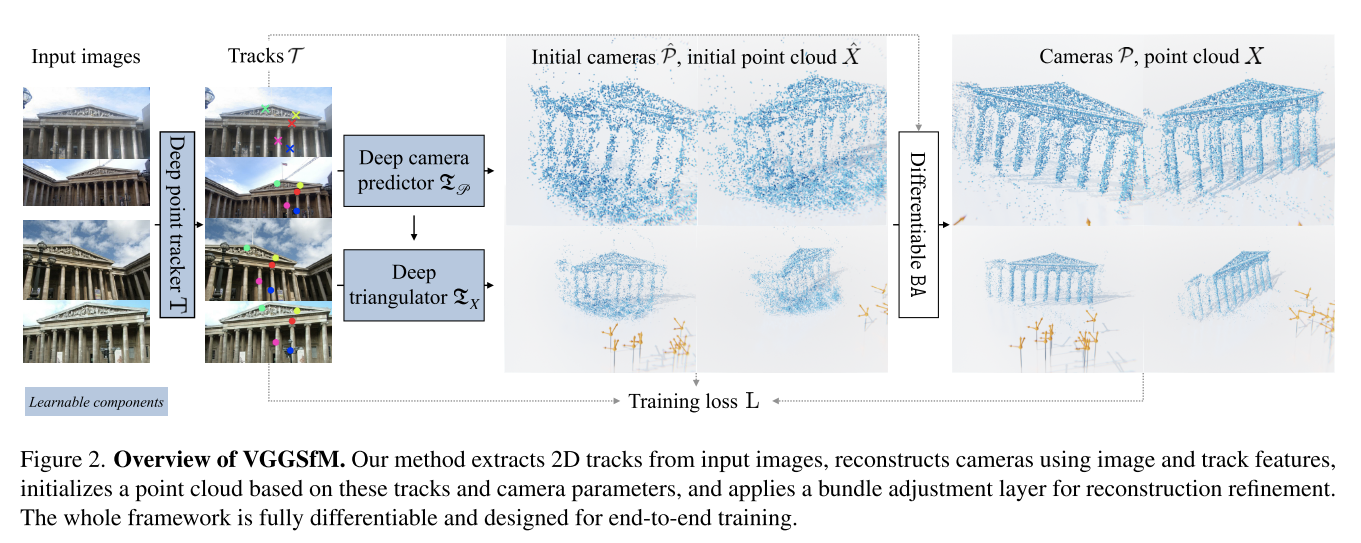


VGGSfM可以分解下面四个阶段:
- 【利用图像,估计约束】point tracking
- 【利用图像和约束,估计位姿】initial camera estimator
- 【利用约束和位姿,估计点云】triangulator
- 【根据约束、位姿、点云,进行BA,优化位姿和点云】Bundle Adjustment
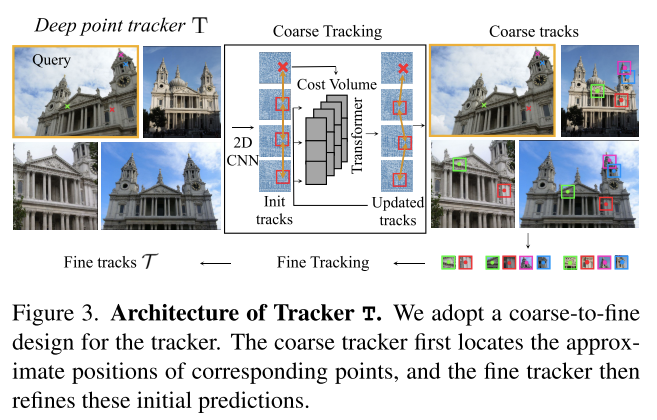
Tracking
这部分使用deep feed-forward tracking function,基于之前video point tracking的方法来实现。
难怪建元在VGGT汇报的时候会说,希望通过大量的YouTube视频怎么怎么。。。VGGT本来是打算沿着VGGSfM做下来的。。。
不过这部分设计和video point tracking是有区别的,因为SfM的图像是无序的,不能假定temporal smoothness or ordering,并且需要sub-pixel accuracy。
Learnable camera & point initialization


Bundle adjustment


Method details


Experiments
略,看论文吧。
个人总结
说白了这篇文章做的事情就是:
- 基于之前的video point tracker,设计了一个Deep point tracker,不过这个tracker支持无序图像的track
- 设计了一个deep camera predictor,基于transformer,估计出一个比较粗糙的pose
- 设计了一个deep triangulator,同样基于transformer,估计一个initial point cloud
- 由于网络直接估计出来的pose和point cloud误差比较大,再通过Differentiable BA来进行优化
感觉这些idea,从目前来看似乎“每个人都想的到”,但现在已经不是2023年了。
训练的部分还挺好的,用的随机帧数。FLARE都2025年了,还在固定8views的输入。
从效果上来看,differentiable BA还是比较重要的,需要关注一下!
- 引用:Luis Pineda, Taosha Fan, Maurizio Monge, Shobha Venkataraman, Paloma Sodhi, Ricky TQ Chen, Joseph Ortiz, Daniel DeTone, Austin Wang, Stuart Anderson, et al. Theseus: A library for differentiable nonlinear optimization. Advances in Neural Information Processing Systems, 35:3801– 3818, 2022. 2, 5
- 代码:https://github.com/facebookresearch/theseus
- 论文:https://arxiv.org/abs/2207.09442
==疑问:为什么需要differential BA?==



