Gaussian Splatting SLAM(MonoGS)代码梳理
Gaussian Splatting SLAM
CVPR 2024 (Highlight & Best Demo Award)
- 主页:https://rmurai.co.uk/projects/GaussianSplattingSLAM
- 代码:https://github.com/muskie82/MonoGS
- 论文:https://arxiv.org/abs/2312.06741
- 视频:https://www.youtube.com/watch?v=x604ghp9R_Q
整体框架
MonoGS整体分为两个线程:Tracking和Mapping。
Keyframing只是衔接Tracking线程和Mapping线程,选择Tracking线程中的某些frame作为keyframe,而Mapping也只对keyframe做重建。
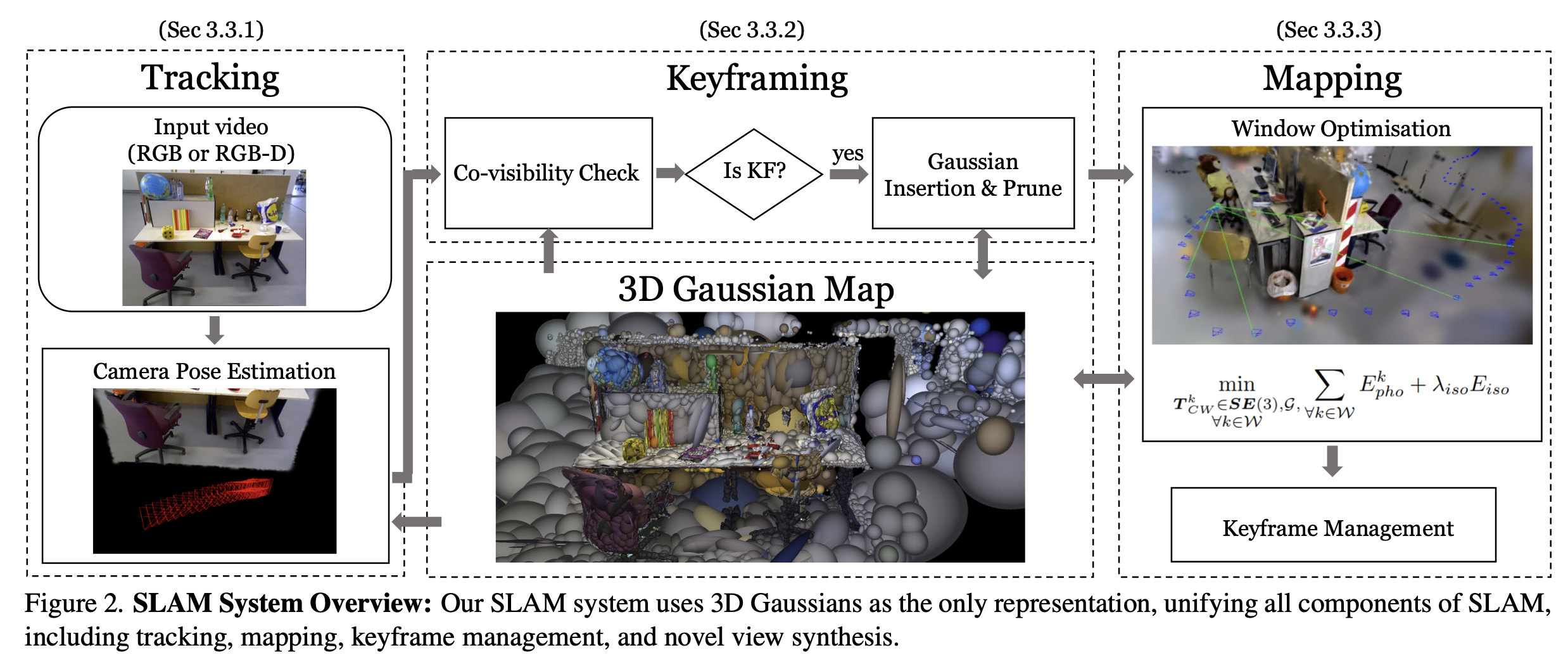
代码整体逻辑
整个SLAM系统作为一个类实现在SLAM.py中,而且在__init__()的时候就运行了所有的线程:
- gui_process
- backend_process
- frontend_process
# ################## SYSTEM STEP 2.1.3 : 启动各个进程 ################## START
# 为什么先创建 backend_process, 再创建 gui_process?
# 改了一下顺序跑代码,看起来是没有影响的。
# backend_process = mp.Process(target=self.backend.run) # 官方的顺序
if self.use_gui:
# 创建一个 GUI 进程,目标函数为 slam_gui.run,传递参数 self.params_gui
gui_process = mp.Process(target=slam_gui.run, args=(self.params_gui,))
# 启动 GUI 进程
gui_process.start()
# 等待5秒,主要是等 GUI 界面加载好
time.sleep(5)
# 创建一个多进程对象 backend_process,目标函数为 self.backend.run
backend_process = mp.Process(target=self.backend.run) # 我改动的顺序
# 启动 backend_process 进程
backend_process.start()
# 主进程运行frontend
self.frontend.run()
# 前端运行结束了,利用队列传递信息,让后端暂停
backend_queue.put(["pause"])
# 记录结束的时间
end.record()
# 在CUDA设备上同步所有流(streams)
torch.cuda.synchronize()
# empty the frontend queue
# ################## SYSTEM STEP 2.1.3 : 启动各个进程 ################## END运行线程之前,各种初始化工作;
运行线程之后,evaluation和线程的收尾工作,彻底关闭所有线程。
Tracking(frontend process)
初始化:
在slam.py的__init__()中调用,仅仅是设置好各种参数。
# 初始化SLAM的前端
self.frontend = FrontEnd(self.config)
...
# 指定前端的一系列参数
self.frontend.dataset = self.dataset
self.frontend.background = self.background
self.frontend.pipeline_params = self.pipeline_params
self.frontend.frontend_queue = frontend_queue
self.frontend.backend_queue = backend_queue
self.frontend.q_main2vis = q_main2vis
self.frontend.q_vis2main = q_vis2main
self.frontend.set_hyperparams()运行:
在slam.py的__init__()中调用,主线程运行tracking。
# 主进程运行frontend
self.frontend.run()运行逻辑:
Tracking线程的逻辑比Mapping线程要复杂一些。
def run(self):
cur_frame_idx = 0
# 根据相机内参生成一个投影矩阵(Projection Matrix)用于计算 3D 图像的投影变换,图形学用的比较多?
# znear 和 zfar 是 3D 投影中视锥体的近裁剪平面和远裁剪平面的距离,用于定义相机能够捕获的深度范围
projection_matrix = getProjectionMatrix2(
znear=0.01,
zfar=100.0,
fx=self.dataset.fx,
fy=self.dataset.fy,
cx=self.dataset.cx,
cy=self.dataset.cy,
W=self.dataset.width,
H=self.dataset.height,
).transpose(0, 1)
projection_matrix = projection_matrix.to(device=self.device)
tic = torch.cuda.Event(enable_timing=True)
toc = torch.cuda.Event(enable_timing=True)
#################################
# 正式进入tracking线程
#################################
while True:
#################################
# 和GUI界面通信,获取GUI界面的控制信息
#################################
if self.q_vis2main.empty():
if self.pause:
continue
else:
data_vis2main = self.q_vis2main.get()
self.pause = data_vis2main.flag_pause
if self.pause:
self.backend_queue.put(["pause"])
continue
else:
self.backend_queue.put(["unpause"])
#################################
#################################
# tracking线程的内部逻辑
#################################
# 如果backend没有发送控制信息,进行正常的tracking流程
if self.frontend_queue.empty():
#################################
# tracking前的逻辑判断
#################################
tic.record()
# 如果运行完了整个序列,保存结果,结束循环
# TODO 疑问:为什么让frontend来做这个事情,不等backend把最后几个keyframe处理一下吗?
if cur_frame_idx >= len(self.dataset):
if self.save_results:
eval_ate(
self.cameras,
self.kf_indices,
self.save_dir,
0,
final=True,
monocular=self.monocular,
)
save_gaussians(
self.gaussians, self.save_dir, "final", final=True
)
break
# 如果需要初始化,进行等待
# 只有被reset的时候才会需要初始化
if self.requested_init:
time.sleep(0.01)
continue
# 如果是单线程,而且刚创建关键帧,就先进行等待
if self.single_thread and self.requested_keyframe > 0:
time.sleep(0.01)
continue
# 如果没有完成初始化,而且刚创建关键帧,也进行等待
if not self.initialized and self.requested_keyframe > 0:
time.sleep(0.01)
continue
# 创建当前帧的viewpoint
viewpoint = Camera.init_from_dataset(
self.dataset, cur_frame_idx, projection_matrix
)
# 根据边缘检测等策略,创建grad mask
viewpoint.compute_grad_mask(self.config)
self.cameras[cur_frame_idx] = viewpoint
# 进行初始化,注意:frontend初始化时,reset为True。
if self.reset:
self.initialize(cur_frame_idx, viewpoint)
self.current_window.append(cur_frame_idx)
cur_frame_idx += 1
continue
# 判断是否完成初始化。
# 对于rgb-d,运行了initialize函数就初始化了;
# 对于mono,如果current_window积攒了足够的数据,就认为能够支持正确的初始化。
self.initialized = self.initialized or (
len(self.current_window) == self.window_size
)
#################################
# Tracking
render_pkg = self.tracking(cur_frame_idx, viewpoint)
#################################
# 和GUI相关的代码,对tracking主要逻辑没有影响
#################################
current_window_dict = {}
current_window_dict[self.current_window[0]] = self.current_window[1:]
keyframes = [self.cameras[kf_idx] for kf_idx in self.current_window]
self.q_main2vis.put(
gui_utils.GaussianPacket(
gaussians=clone_obj(self.gaussians),
current_frame=viewpoint,
keyframes=keyframes,
kf_window=current_window_dict,
)
)
#################################
#################################
# keyframe创建、管理流程
#################################
# 如果创建了新的keyframe,那么释放当前帧的内存,并且跳过下面的步骤
if self.requested_keyframe > 0:
self.cleanup(cur_frame_idx)
cur_frame_idx += 1
continue
# 如果目前没有新的keyframe,开始判断是否创建keyframe
last_keyframe_idx = self.current_window[0]
check_time = (cur_frame_idx - last_keyframe_idx) >= self.kf_interval
curr_visibility = (render_pkg["n_touched"] > 0).long()
# 如果与上一个关键帧距离过大,或者重叠度较低&和上个关键帧有一定的距离,就创建关键帧
create_kf = self.is_keyframe(
cur_frame_idx,
last_keyframe_idx,
curr_visibility,
self.occ_aware_visibility,
)
# 如果当前的滑动窗口没有满,使用更宽松的条件判断是否需要创建关键帧
# TODO 疑问:如果是这样的话,可以把create_kf的条件也放进来吧?
# 不过应该不存在上面的条件满足,但下面的条件不满足的情况。
if len(self.current_window) < self.window_size:
union = torch.logical_or(
curr_visibility, self.occ_aware_visibility[last_keyframe_idx]
).count_nonzero()
intersection = torch.logical_and(
curr_visibility, self.occ_aware_visibility[last_keyframe_idx]
).count_nonzero()
point_ratio = intersection / union
create_kf = (
check_time
and point_ratio < self.config["Training"]["kf_overlap"]
)
# 如果是单线程模式,还要再检查一遍时间间隔是否满足要求。
# WHY?因为单线程不想创建太多的关键帧?
if self.single_thread:
create_kf = check_time and create_kf
# 如果确定当前帧是关键帧,创建关键帧
if create_kf:
# 将当前帧添加到滑动窗口,并且删除与当前帧重叠度小于阈值的关键帧
# 如果重叠度都大于阈值,而且滑动窗口的size超了,就删除重叠的最少的那个关键帧(看起来像个BUG,为什么重叠度都这么大还会创建关键帧呢)
self.current_window, removed = self.add_to_window(
cur_frame_idx,
curr_visibility,
self.occ_aware_visibility,
self.current_window,
)
# monocular的情况下,如果没有完成initialized,而且又有keyframe被删除,说明新进来的帧overlap较少,需要resetting。
if self.monocular and not self.initialized and removed is not None:
self.reset = True
Log(
"Keyframes lacks sufficient overlap to initialize the map, resetting."
)
continue
# 如果是monocular,使用渲染的depth和opacity来为当前关键帧创建depth
# 如果是RGB-D,直接使用观测的depth,渲染的结果就不用了
depth_map = self.add_new_keyframe(
cur_frame_idx,
depth=render_pkg["depth"],
opacity=render_pkg["opacity"],
init=False,
)
# 向backend发送消息,将new keyframe发送过去
self.request_keyframe(
cur_frame_idx, viewpoint, self.current_window, depth_map
)
else: # 否则,释放当前帧的内存
self.cleanup(cur_frame_idx)
cur_frame_idx += 1
#################################
# 保存当前帧的评估结果
if (
self.save_results
and self.save_trj
and create_kf
and len(self.kf_indices) % self.save_trj_kf_intv == 0
):
Log("Evaluating ATE at frame: ", cur_frame_idx)
eval_ate(
self.cameras,
self.kf_indices,
self.save_dir,
cur_frame_idx,
monocular=self.monocular,
)
toc.record()
torch.cuda.synchronize()
# FIXME 看起来如果创建了关键帧,frontend还需要等一等,这样的话tracking的速率就被限制了
# 这里可能是一个小trick,keyframe到了backend之后,就要优化场景的gaussian了
# 而这个期间,场景的gaussian可能不太适合tracking,会影响tracking的结果
#
# 可能的改进思路:创建一个mask,新增的区域不参与tracking,这样就可以全速tracking了。
# 但是这样可能也有问题,overlapping变小了,tracking的结果不一定更好。
# 说到底还是inverse 3DGS的tracking太脆弱了。。。
if create_kf:
# throttle at 3fps when keyframe is added
duration = tic.elapsed_time(toc)
time.sleep(max(0.01, 1.0 / 3.0 - duration / 1000))
else: # 如果接收到了控制信息,优先处理控制信息
data = self.frontend_queue.get()
if data[0] == "sync_backend":
self.sync_backend(data)
elif data[0] == "keyframe":
self.sync_backend(data)
self.requested_keyframe -= 1
elif data[0] == "init":
self.sync_backend(data)
self.requested_init = False
elif data[0] == "stop":
Log("Frontend Stopped.")
breakMapping(backend process)
初始化:
与Tracking相同,在slam.py的__init__()中调用,仅仅是设置好各种参数。
# 初始化SLAM的后端
self.backend = BackEnd(self.config)
...
# 指定后端的一系列参数
self.backend.gaussians = self.gaussians
self.backend.background = self.background
self.backend.cameras_extent = 6.0
self.backend.pipeline_params = self.pipeline_params
self.backend.opt_params = self.opt_params
self.backend.frontend_queue = frontend_queue
self.backend.backend_queue = backend_queue
self.backend.live_mode = self.live_mode
self.backend.set_hyperparams()运行:
在slam.py的__init__()中调用,创建一个子线程运行mapping。
# 创建一个多进程对象 backend_process,目标函数为 self.backend.run
backend_process = mp.Process(target=self.backend.run)
# 启动 backend_process 进程
backend_process.start()运行逻辑:
def run(self):
#################################
# 直奔主题,进入Mapping的主要流程
#################################
while True:
# 如果没有控制信息发送过来
if self.backend_queue.empty():
# 如果是pause、当前关键帧窗口为空、单线程模式,进行等待
if self.pause:
time.sleep(0.01)
continue
if len(self.current_window) == 0:
time.sleep(0.01)
continue
if self.single_thread:
time.sleep(0.01)
continue
# 否则,多线程&关键帧窗口不为空,优化当前关键帧窗口,迭代1次
self.map(self.current_window)
# 如果距离上一次发送关键帧已经迭代优化了10次以上,还是优化当前关键帧窗口,并且进行prune,迭代10次
# 其实last_sent是记录上次和frontend同步到现在,mapping迭代了多少轮。
# 不过同步一般发生在frontend向backend发送keyframe。
if self.last_sent >= 10:
self.map(self.current_window, prune=True, iters=10)
self.push_to_frontend()
else: # 如果有控制信息发过来
data = self.backend_queue.get()
if data[0] == "stop":
break
elif data[0] == "pause":
self.pause = True
elif data[0] == "unpause":
self.pause = False
elif data[0] == "color_refinement": # 结束整个SLAM之前调用,刷一波指标
self.color_refinement()
self.push_to_frontend()
elif data[0] == "init": # frontend在init的时候会给这里发一个init指令
cur_frame_idx = data[1]
viewpoint = data[2]
depth_map = data[3]
Log("Resetting the system")
self.reset()
self.viewpoints[cur_frame_idx] = viewpoint
# 往场景中添加new keyframe的点云
self.add_next_kf(
cur_frame_idx, viewpoint, depth_map=depth_map, init=True
)
# 初始化地图
self.initialize_map(cur_frame_idx, viewpoint)
self.push_to_frontend("init")
elif data[0] == "keyframe": # 如果frontend往这里发送了keyframe
cur_frame_idx = data[1]
viewpoint = data[2]
current_window = data[3]
depth_map = data[4]
self.viewpoints[cur_frame_idx] = viewpoint
self.current_window = current_window
self.add_next_kf(cur_frame_idx, viewpoint, depth_map=depth_map)
opt_params = []
frames_to_optimize = self.config["Training"]["pose_window"]
iter_per_kf = self.mapping_itr_num if self.single_thread else 10
if not self.initialized:
if (
len(self.current_window)
== self.config["Training"]["window_size"]
):
frames_to_optimize = (
self.config["Training"]["window_size"] - 1
)
iter_per_kf = 50 if self.live_mode else 300
Log("Performing initial BA for initialization")
else:
iter_per_kf = self.mapping_itr_num
for cam_idx in range(len(self.current_window)):
if self.current_window[cam_idx] == 0:
continue
viewpoint = self.viewpoints[current_window[cam_idx]]
if cam_idx < frames_to_optimize:
opt_params.append(
{
"params": [viewpoint.cam_rot_delta],
"lr": self.config["Training"]["lr"]["cam_rot_delta"]
* 0.5,
"name": "rot_{}".format(viewpoint.uid),
}
)
opt_params.append(
{
"params": [viewpoint.cam_trans_delta],
"lr": self.config["Training"]["lr"][
"cam_trans_delta"
]
* 0.5,
"name": "trans_{}".format(viewpoint.uid),
}
)
opt_params.append(
{
"params": [viewpoint.exposure_a],
"lr": 0.01,
"name": "exposure_a_{}".format(viewpoint.uid),
}
)
opt_params.append(
{
"params": [viewpoint.exposure_b],
"lr": 0.01,
"name": "exposure_b_{}".format(viewpoint.uid),
}
)
self.keyframe_optimizers = torch.optim.Adam(opt_params)
# 这里为什么要map两次呢?看起来像是迭代一定次数后做一次prune,为了代码方便就分两次写了?
self.map(self.current_window, iters=iter_per_kf)
self.map(self.current_window, prune=True)
self.push_to_frontend("keyframe")
else:
raise Exception("Unprocessed data", data)
#################################
# 清理用于通信的两个队列中的信息
while not self.backend_queue.empty():
self.backend_queue.get()
while not self.frontend_queue.empty():
self.frontend_queue.get()
return


