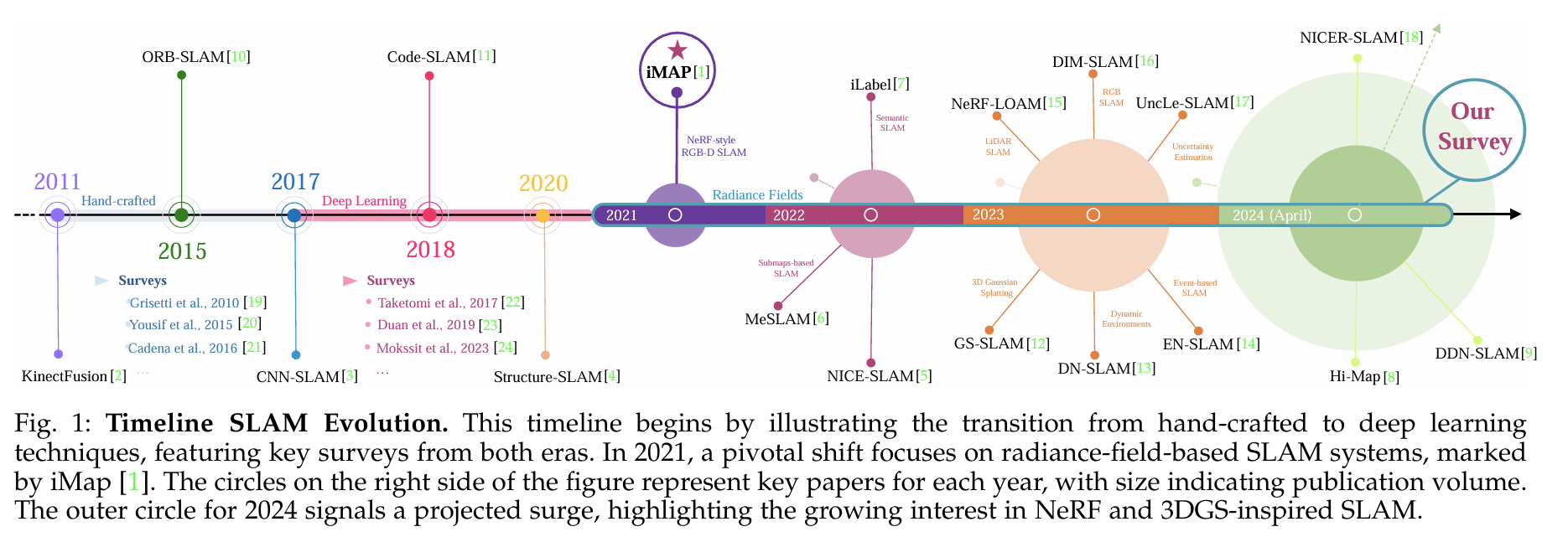
NeRF & 3DGS in SLAM & Robotics
How NeRFs and 3DGS are Reshaping SLAM
关于 ideal SLAM criteria:As we outline the ideal SLAM criteria, several key aspects emerge. These include global consistency, robust camera tracking, accurate surface modeling, real-time performance, accurate prediction in unobserved regions, scalability to large scenes, and robustness to noisy data. 即,全局一致性、稳健的相机跟踪、精确的表面建模、实时性能、未观察区域的准确预测、大型场景的可扩展性以及对噪声数据的鲁棒性。
NeRF、3DGS与传统方法相比具备的优点:including continuous surface modeling, reduced memory requirements, improved noise/outlier handling, and enhanced hole filling and scene inpainting capabilities for occluded or sparse observations. In addition, they have the potential to produce denser and more compact maps that can be reconstructed as 3D meshes at arbitrary resolutions. However, it is important to note that at this early stage, the strengths of each technique coexist with specific challenges and limitations. 即,连续表面建模,减少内存需求,改进噪声/异常值处理,增强孔填充和场景绘制能力,用于遮挡或稀疏观测。此外,它们有可能产生更密集、更紧凑的地图,可以以任意分辨率重建为3D网格。
个人认为,不能仅仅局限在SLAM这个话题上,SLAM主要是面向Robotics的。
在Robotics中,如果有了NeRF、3DGS表示的地图,可以进行更多的拓展。
新一代的SLAM最主要的问题:This analysis highlights how, despite the great promise brought by this new generation of SLAM systems, most of them are still unsatisfactory in terms of hardware and runtime requirements, making them not yet ready for realtime applications. 即,大多数方法在硬件和运行时需求方面仍然令人不满意,这使得它们尚未为实时应用程序做好准备。
3DGS的问题:However, these methods have several limitations, including a heavy reliance on initialization and a lack of control over primitive growth in unobserved regions. Furthermore, the original 3DGS-based scene representation requires a large number of 3D Gaussian primitives to achieve high-fidelity reconstruction, resulting in substantial memory consumption.
这个问题我也观察到了,初始化很大程度决定了训练的上限,观察区域边缘的3DGS会一直膨胀,这是一个非常不好的现象。
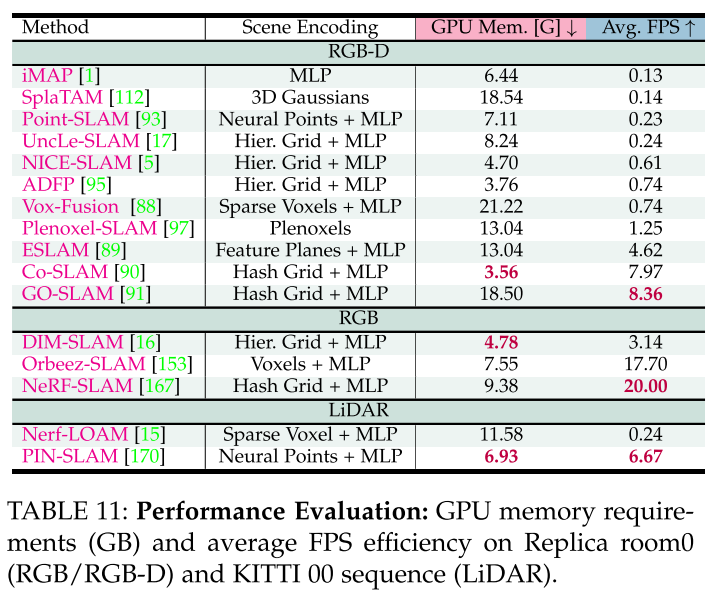
NeRF vs. 3DGS in SLAM:NeRF-style SLAM, which relies mostly on MLP(s), is well suited for novel view synthesis, mapping and tracking but faces challenges such as oversmoothing, susceptibility to catastrophic forgetting, and computational inefficiency due to its reliance on perpixel ray marching. 3DGS bypasses per-pixel ray marching and exploits sparsity through differentiable rasterization over primitives. This benefits SLAM with an explicit volumetric representation, fast rendering, rich optimization, direct gradient flow, increased map capacity, and explicit spatial extent control. Thus, while NeRF shows a remarkable ability to synthesize novel views, its slow training speed and difficulty in adapting to SLAM are significant drawbacks. 3DGS, with its efficient rendering, explicit representation, and rich optimization capabilities, emerges as a powerful alternative. Despite its advantages, current 3DGS-style SLAM approaches have limitations. These include scalability issues for large scenes, the lack of a direct mesh extraction algorithm (although recent methods such as [192] have been proposed), the inability to accurately encode precise geometry and, among others, the potential for uncontrollable Gaussian growth into unobserved areas, causing artifacts in rendered views and the underlying 3D structure. Moreover, the computational complexity of 3DGS-based SLAM systems is significantly higher than NeRF-based methods, which can hinder real-time performance and practical deployment, especially on resource-constrained devices. In order to mitigate these issues, recent research efforts, such as CompactGSSLAM [114], have focused on developing compact 3D Gaussian scene representations that optimize storage efficiency while maintaining high-quality reconstruction, rapid training convergence, and real-time rendering capabilities.
总结就是:
NeRF SLAM在新视角合成、跟踪、建图上有优势;但是存在过度平滑、容易遗忘和计算效率过低的问题;
这导致NeRF的方法相对于3DGS来说,其实不是很适合SLAM。
3DGS SLAM有显示表示,渲染和优化更快,有直接的梯度流动,更高的地图容量,可以显示控制地图范围;但是3DGS目前扩展性差、大场景下表现不好、缺乏直接的mesh提取算法、几何精度比较差、未观测区域的高斯增长可能导致伪影、计算复杂度高。
不过3DGS主要凭借高效的渲染和显示的表示,在SLAM中更加有优势。
SLAM Meets NeRF
在NeRF SLAM中,用SDF取代volume density的优势:
- SDF values and volume densities decoded by MLP networks cannot be mutated without losing texture features. However, since zero iso-surface decision boundaries are abrupt, the use of SDF values can enable the extraction of surfaces containing texture features.
- A loss function based on SDF values constrains the on-surface points and off-surface points, so SDF values can provide more geometric information.
- The loss function of an SDF sets the SDF value away from the surface of the object as a cut-off value. Combined with the voxel skipping strategy, unnecessary calculations can be avoided, while the volume density is affected by floating objects in the air, which requires more sampling points and more calculations. Combined with the voxel skipping strategy, unnecessary calculations can be avoided. And because the volume density is affected by floating objects in the air, the calculation cost is large.
- An SDF value can visually describe the distance between a sampling point and an object’s surface, which is conducive to the realization of AR and VR.
不过这样也会导致新的问题:SDF代替volume density会导致孔洞填补的能力减弱。
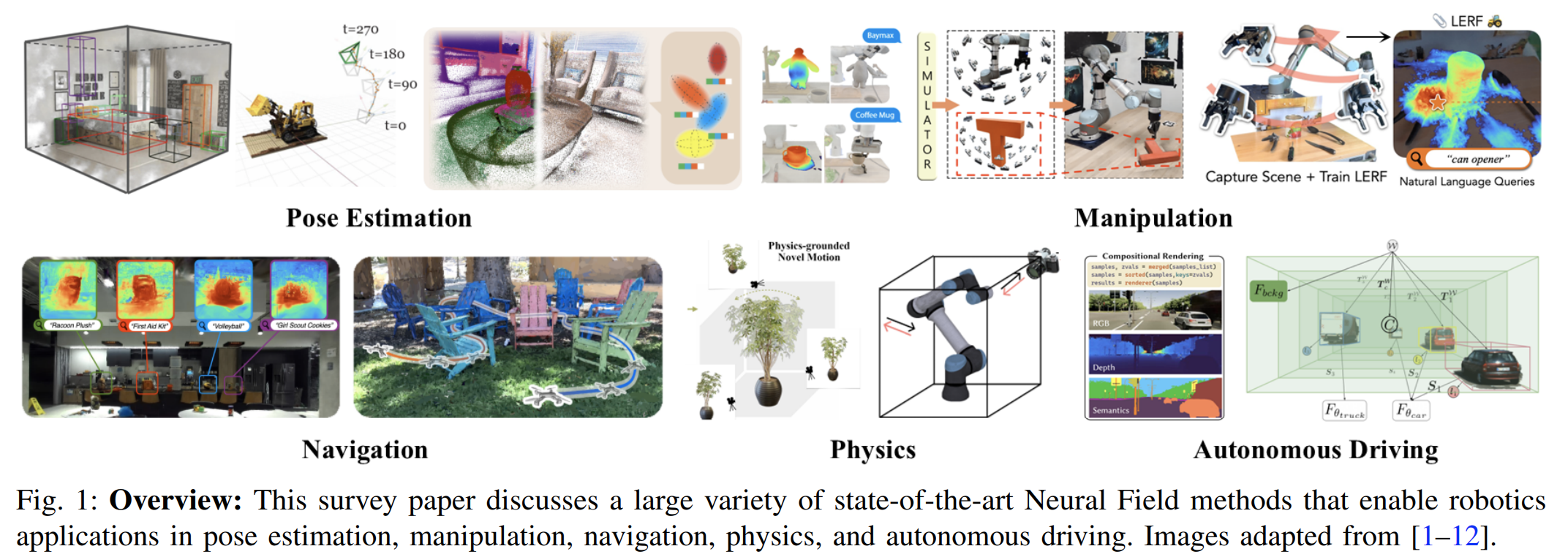
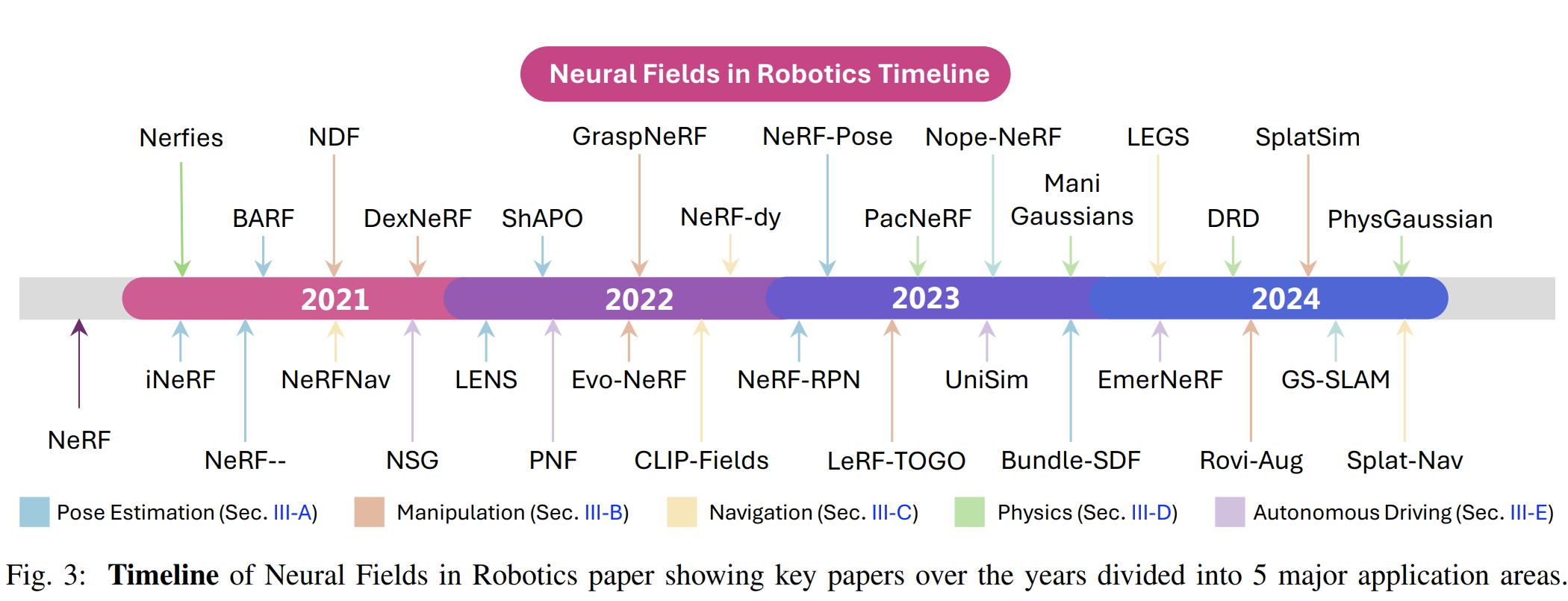
Neural Fields in Robotics
这篇综述主要关注:pose estimation, manipulation, navigation, physics, and autonomous driving
Typical robotic pipeline:At the core of a typical robotic pipeline is the synergy between perception and action. The perception system gathers sensory data from devices such as RGB cameras, LiDAR, and depth sensors and transforms them into a coherent model of the environment — such as a 3D map that enables the robot to maneuver through dynamic, obstacle-rich spaces. The quality of this representation directly impacts the robot’s decision-making or policy, which translates the perceived environment into actions, enabling it to avoid moving forklifts, pick up scattered objects, or plan a safe path in an emergency.
Typical robotic pipeline中对环境建模的方法存在的问题:Traditionally, robots have modeled their environments using data structures like point clouds, voxel grids, meshes, and Truncated Signed Distance Functions (TSDF). While these representations have advanced robotic capabilities, they struggle to capture fine geometric details, particularly in complex or dynamic environments, leading to suboptimal performance in adaptable scenarios. 即,这些方法难以捕捉精细的几何细节,特别是在复杂或动态环境中,导致在适应场景中性能不佳。
与传统地图表示方法相比,NeRF在Robotics中的优势:
High-Quality 3D Reconstructions: NFs generate detailed 3D representations of environments, which are crucial for tasks like navigation, manipulation, and scene understanding [24–28].
对机器人的导航、操作、场景理解很有帮助。
Multi-Sensor Integration: NFs can seamlessly integrate data from multiple sensors, such as LiDAR and RGB cameras, providing a more robust and adaptable perception of the environment [29, 30].
在3DGS中,这个优势更加明显了,Lidar和Camera更容易结合起来了。
注:这个点还不确定,可能得看看LVI-SAM、R2live、R3live等基于传统方法的工作。
Continuous and Compact Representations: Unlike voxel grids or point clouds, which are inherently discrete, NFs offer continuous representations that capture fine spatial details using fewer parameters, enhancing computational efficiency [22, 31].
更少的参数,更精细的空间细节
Generalization and Adaptation: Once trained, NFs can generate novel viewpoints of a scene, even from previously unseen perspectives, which is particularly valuable for exploration or manipulation tasks. This ability is enabled by generalizable NeRF methods [32–34].
新视角生成对探索、操作等任务特别有价值
Integration with Foundation Models: NFs can be combined with foundation models like CLIP [35] or DINO [36], enabling robots to interpret and respond to natural language queries or other semantic inputs [37, 38].
可以和foundation model进行结合
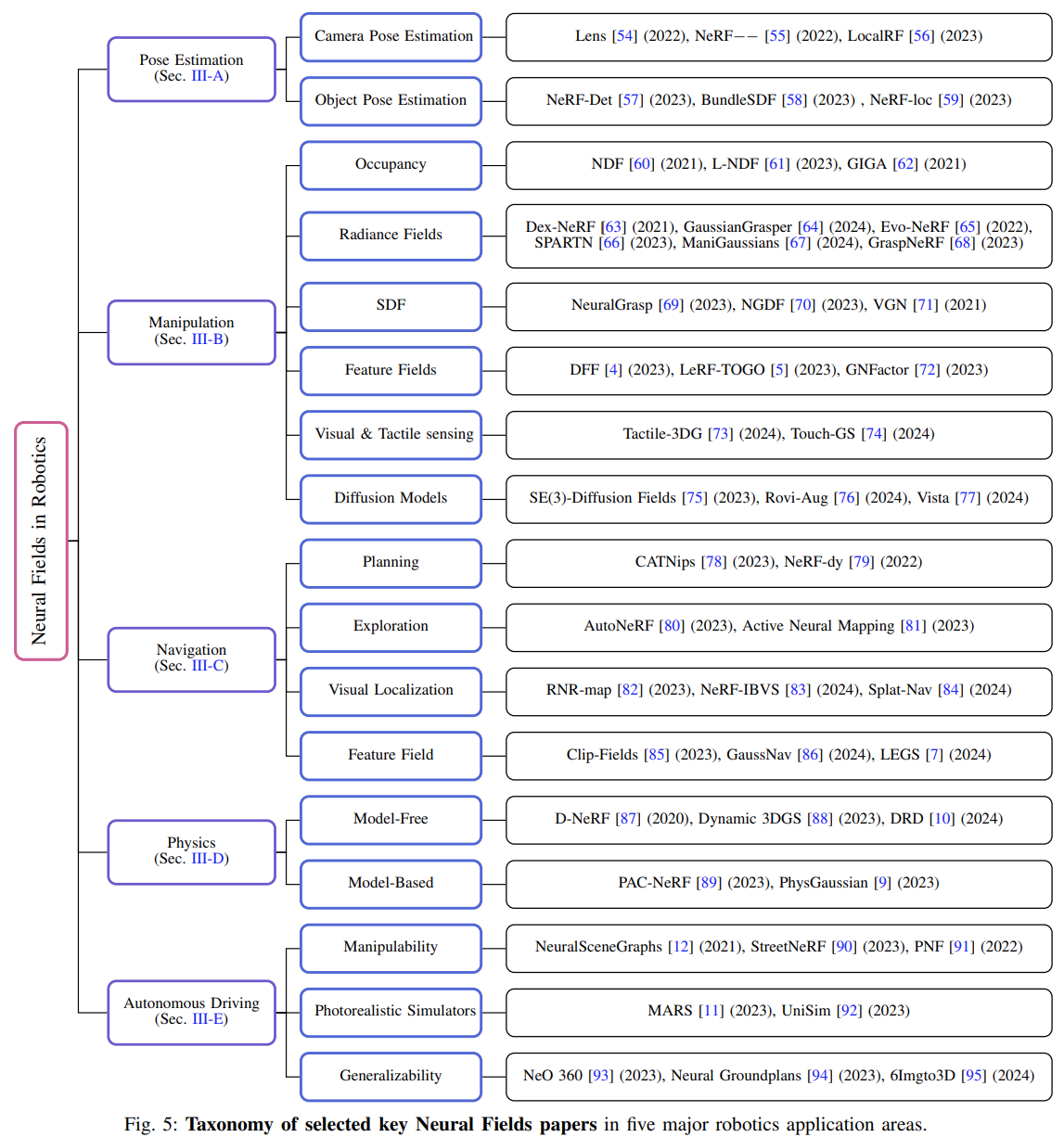
Neural Fields for Pose Estimation
Camera Pose Estimation:对定位、建图等任务很重要。
略,这部分太熟悉了。。。
Object Pose Estimation:对操作、交互等任务很重要。
论文描述的工作基本上是围绕如何估计场景中物体的3D bounding box,也提到了一些同时估计物体姿态和对物体进行重建的。
Takeaways and Open Challenges in Neural Fields for Pose Estimation:
- 在静态场景中有了重大进展,但是面对动态场景,还有很多值得探索的空间;
- open-vocabulary 6D object pose estimation。
Neural Fields for Robotic Manipulation
Manipulation的关键问题:One of the key challenges in robotic manipulation is obtaining a precise geometric representation of both the objects and the environment involved in the task. An effective representation must also capture the environment dynamics, offering a robust 3D understanding of the objects. 即,获得任务中涉及的物体和环境的精确几何表示,并且最好是捕捉环境的动态变化,提供对object的鲁棒3D理解。
机械臂、灵巧手如果想要操纵物体、控制物体的话,需要生成“抓点”,grasps。有一些方法已经可以合成3-DoF的grasps了,但是缺乏精确的方向控制。而6-DoF的方法可以完全控制RPY,操纵能力更强。
综述提到了很多论文针对“透明”或者“镜面”物体展开了工作,看起来NeRF、3DGS可能在这方面做得比较好。
另外,综述提到了GaussianGrasper,这个工作提出了6-DoF的抓取方法,支持对open-vocabulary object进行抓取,这能够让机器人理解和执行基于自然语言指令的任务。
也有一些工作比如SplatSim,用于实现Sim2Real传输,减少合成数据和真实数据之间的偏移。
这个在知乎上也有人讨论,不过单看指标还是存在较大的偏移,只不过肉眼看这感觉要好很多了。。。
Takeaways and Open Challenges in Neural Fields for Manipulation:
NFs have emerged as powerful techniques for robust 3D understanding in robotic manipulation tasks, such as grasping and pick-and-place. These representations capture detailed geometrical information and support generalization across diverse object shapes and categories. NFs have also been employed to identify optimal grasp points, improving the success rate of robotic grasps in cluttered environments. Additionally, some methods integrate these representations with language models, enabling open-vocabulary manipulation through natural language instructions.
即,为机器人操纵抓取等任务提供了强大的3D理解能力。这些表示方法捕获了详细的几何信息,并且支持跨不同对象形状和类别的泛化。另外也可以用于识别最佳抓取点,提高了机器人在杂乱环境中抓取的成功率。也可以和一些语言模型集成在一起,通过自然语言指令实现开放词汇操作。
Despite these advancements, significant challenges remain. Current approaches rely on extensive multi-view inputs or costly per-scene optimization, limiting their applicability in complex, dynamic, or unstructured environments. Furthermore, incorporating physical intuitions about object affordances and robot dynamics into the learned representations could lead to more physically grounded manipulation policies (see Sec. III-D). Finally, scaling these methods to dynamic scenes with multiple agents or articulated objects is an ongoing challenge that must be addressed for real-world deployment.
即,当前的方法依赖于足够的多视图输入和逐场景的优化,限制了这种方法在复杂、动态或者非结构化环境中的适用性。
Neural Fields for Navigation
这篇综述将Navigation分为四个部分:Planning, Exploration, Visual Localization, and Feature Fields。
Takeaways and Open Challenges in Neural Fields for Navigation:
While Neural Fields have made significant strides in navigation, key challenges still remain. Current methods focus mainly on static environments and tasks like image-goal and vision-language navigation. Future work could extend NFs to dynamic settings, incorporating fast reconstruction techniques for real-time updates in evolving environments [186]. Another crucial direction is dynamic scene pose estimation (Sec. III-A3) to aid reconstruction and navigation in dynamic environments.
即,当前的方法侧重于静态环境和图像目标和视觉语言导航等任务,未来可以考虑扩展到动态场景。
The integration of generative NFs also holds great potential. Recent diffusion model advances [39, 187] could facilitate efficient scene editing and environment creation, narrowing the sim-to-real gap. Additionally, leveraging foundation models for large-scale mobile manipulation and scene generalization could unlock further advancements. Integrating Vision-Language Models (VLMs) with implicit representations for enhanced commonsense reasoning within NFs offers another promising frontier for future exploration.
即,将VLM和隐式表示相结合。
Neural Fields for Physics
略,不太看得懂。放过自己。
Neural Fields in Autonomous Driving
综述开头这一段的观点和知乎上一些讨论很相近:High-quality mapping of large-scale environments is essential for autonomous driving systems. A high-fidelity map of the entire operating domain serves as a powerful prior for various tasks, including robot localization (see Sec. III-A), navigation, and collision avoidance (see Sec. III-C). Additionally, largescale scene reconstructions facilitate closed-loop robotic simulations. Autonomous driving systems are often evaluated by re-simulating previously encountered scenarios; however, any deviation from the original encounter can alter the vehicle’s trajectory, necessitating high-fidelity novel view renderings along the adjusted path. In addition to basic view synthesis, scene-conditioned NeRFs can modify environmental lighting conditions, such as camera exposure, weather, or time of day, further enhancing simulation scenarios.
Neural Fields have become a prominent framework in autonomous driving due to their ability to generate photorealistic 3D environments from RGB images. These environments are highly valuable for constructing immersive simulation systems with several key features, as previously discussed: First, NFs offer extensive manipulability and compositionality (Sec. III-E1), allowing for the seamless integration and manipulation of objects within a scene. This facilitates the simulation of complex scenarios, such as collisions, which are difficult to replicate in physical settings. Second, they produce scenes with impressive photorealism (Sec. III-E2), enabling realistic simulations from visual data. Finally, their strong generalizability (Sec. III-E3) from sparse inputs allows for creating accurate, scalable environments, enhancing research in embodied AI. These traits, as discussed in the following subsections, enable the creation of simulated environments that faithfully represent real-world scenarios, thereby facilitating research in embodied AI.
主要说的是,有助于闭环模拟,而且NeRF、3DGS可以进行场景编辑甚至修改照明条件。
NeRF、3DGS在自动驾驶中关注度确实非常高的。
Takeaways and Open Challenges in Neural Fields for Autonomous Driving:
- Despite the promising progress in NFs for autonomous driving, several open challenges remain. Current methods focus on photorealistic simulators, which are dynamic, compositional, and realistic. One avenue of future work is training policies in such NF-based simulators and transferring them to the real-world. Connecting the success of NFs in autonomous driving with real-world deployment is an exciting avenue for future work. Generalizable reconstruction has seen some early signs of life with recent works but still remains largely underexplored. Future works could look at the efficiency of generalizable outdoor scene reconstruction methods, as well as advances that focus on sim2real transfer and pose-free reconstruction. This avenue of research is exciting as it opens the door for creating photorealistic simulators from a few images in the real world.
- Another promising direction for autonomous driving research is integrating generative methods like diffusion models with the NFs’ paradigm. Future work could look at creating new scenarios via NF editing that are difficult to create in the real world, such as collision avoidance to train policies via reward models in NFs’ simulation. Generative asset creation through a few images from the real world is another potential avenue for NF’s research for autonomous driving.
- Furthermore, the integration of NFs into generative models such as shown in Lift3D [220] and Adv3D [221] facilitates data augmentation, addressing the challenges posed by the diversity of driving scenes. Given the high costs associated with capturing all potential scenarios, data augmentation emerges as a valuable strategy and promising future direction for expanding training datasets and improving model performance.
OPEN CHALLENGES OF NEURAL FIELDS IN ROBOTICS
- Efficiency: NFs are computationally intensive and may not naturally operate in real-time, which is often a critical requirement for robotics applications. There is a need for significant optimization or simplification to make these models run efficiently on robotics hardware, which may have limited computational resources compared to dedicated GPUs used in data centers.
- Dynamic environments: Robotics often involve operating in dynamic environments where objects and scene configurations change over time. Capturing and updating NFs to reflect these changes in real-time remains a challenging task.
- Sensor integration: Effectively integrating data from various sensors (e.g., LiDAR, RGB cameras, depth sensors) to enhance the robustness and performance of NFs is relatively under-explored. Advanced sensor fusion techniques could potentially bridge this gap.
- Generalization: Existing techniques often require dense input data and struggle with sensor noise or occlusions. Developing methods that can leverage priors learned from web-scale datasets to generalize across varied scenarios offers a promising direction.
- Physical information: While NFs excel at representing visual aspects, they do not inherently understand physical properties like weight or friction. Extending NFs to incorporate physics simulations could enable more realistic interactions for robots.
- Data efficiency and augmentation: Current approaches are data-hungry, which is impractical for real-world applications. Innovations in data-efficient learning techniques and realistic data augmentation could help in overcoming these limitations.
- Multi-modal, multi-task, and efficient scene understanding: Developing neural field approaches that can handle multiple tasks and modalities simultaneously while maintaining efficiency in scene understanding is crucial for holistic robotic perception.
- Performance evaluation: Establishing standardized metrics and benchmarks for evaluating the performance of NFs in robotic applications will be essential for tracking progress and comparing different approaches.
- Collaborative frameworks: There is a need for frameworks that support collaboration between robots using NFs, enabling them to share learnings and improve collective understanding and decision-making in complex environments.
NeRF in Robotics
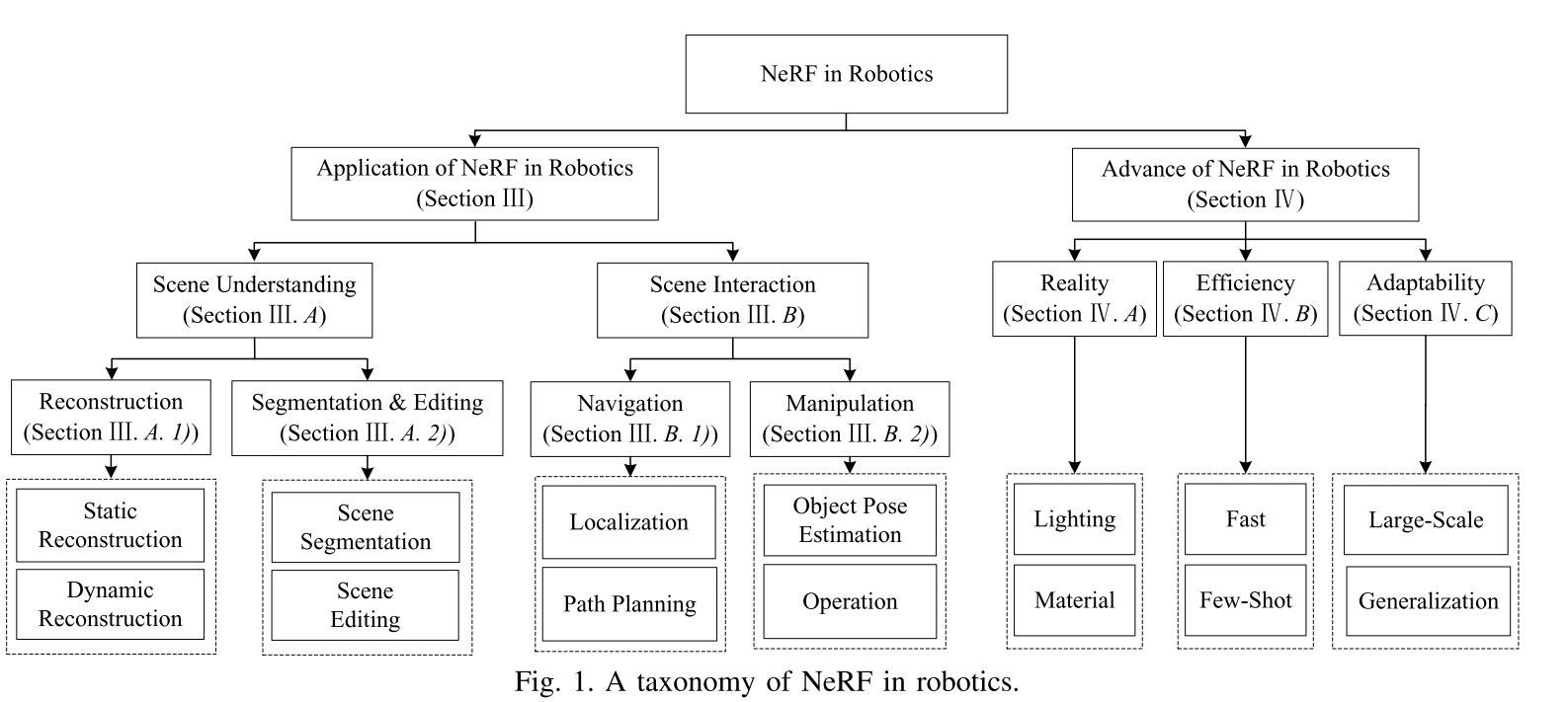
这篇文章基本上是对各种工作的总结。
3D Gaussian Splatting in Robotics: A Survey
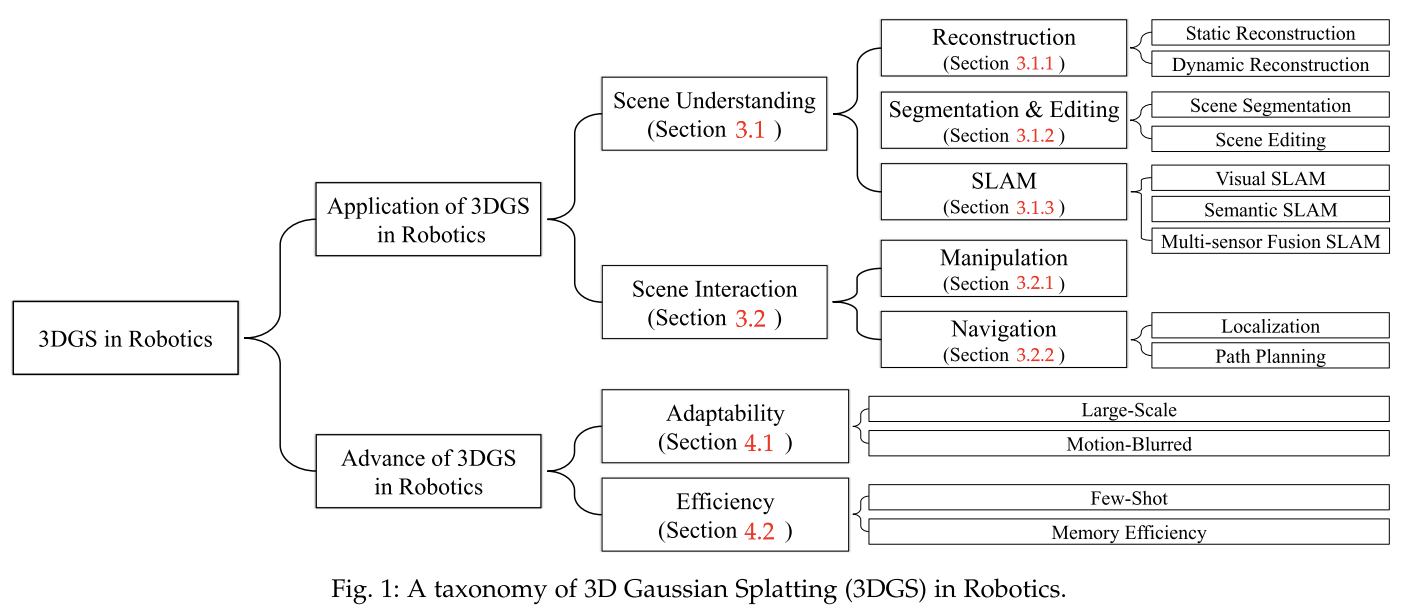
这篇文章和上一篇文章结构几乎一模一样,不过做了一些讨论。
关于Robust Tracking:Existing 3DGS-based SLAM methods, although demonstrating high accuracy in dense mapping, typically fail to achieve accurate and robust tracking, especially in complex real-world scenarios. This limitation in current 3DGS-based SLAM systems is due to their reliance on directly using RGB information of image for pose optimization. Such reliance heavily depends on the quality and texture information of the images. However, in real-world robotic applications, image quality is prone to camera motion blur, degrading the performance of 3DGS-based SLAM. Moreover, there are some scenes with limited texture information, such as sky or walls, leading to insufficient constraints for pose estimation. The following presents corresponding directions to improve the robustness of tracking.
- Camera motion blur. Camera motion blur is primarily caused by rapid movements of the robot and slow shutter speed of the camera, leading to blurry images. Although deblurring methods have been researched (Section 4.1.1) and used in SLAM [116], these methods fail to directly convert captured blurry images into sharp ones. Instead, they simulate motion blur by averaging virtual sharp images captured during the camera exposure time to synthesize blurry images. These synthesized blurry images are then used to construct loss with the observed blurry images for Gaussian optimization, ensuring that the constructed scene is deblurred. However, such methods fail to address the degradation of image quality in the observed images caused by motion blur, which adversely affects tracking performance that relies on high-quality images for pose optimization. A suitable research direction is to leverage the advantages of 3DGS representation, such as geometric information and spatial distribution, to perform tracking. This method can reduce the reliance on image quality.
- Limited texture information. In real-world scenes, there are some corner cases where the environmental texture information is limited, leading to insufficient constraints for pose optimization that solely relies on image quality. Although some 3DGS-based SLAM methods [128], [129] have utilized multi-sensor fusion traditional SLAM as odometry for tracking, these methods fail when traditional SLAM is unable to handle complex corner cases. A potential research direction is to incorporate original sensor data of multiple sensors, such as IMU, wheel encoders, and LiDAR, with 3D Gaussian representation to provide sufficient constraints for pose optimization. This approach not only leverages the spatial structural information and dense scene representation offered by 3DGS, but also exploits the various constraints from multi-sensor information.
关于Lifelong Mapping and Localization:Current 3DGS methods primarily focus on short-term reconstruction and localization. However, in most real-world scenarios, the environment undergoes constant changes over time. A prebuilt map that fails to consider these changes may quickly become outdated and unreliable. Consequently, it is crucial to maintain an up-to-date model of the environment to facilitate the long-term operation or navigation of robots. Although some traditional methods [217], [218] have achieved long-term mapping, these approaches focus on constructing and updating sparse maps, which are insufficient for downstream robotic tasks. Therefore, a promising research direction is lifelong 3DGS-based dense mapping and localization. Since 3DGS is an explicit and dense representation, the dynamic update and refinement of the Gaussian map can be achieved through explicit editing of Gaussian primitives. Additionally, we believe that the inconsistencies in the Gaussian map caused by longterm dynamic changes can be optimized by leveraging the inner constraints between Gaussian primitives. Therefore, by harnessing the explicit representation and inherent constraints among Gaussian primitives, lifelong mapping and localization can be achieved.
有一点个人很喜欢:虽然一些传统方法[217],[218]已经实现了长期的映射,但这些方法主要集中在构建和更新稀疏地图,这对于下游机器人任务来说是不够的。因此,基于3dgs的终身密集映射与定位是一个很有前景的研究方向。
关于Large-scale Relocalization:In robotic applications, it is necessary for robots to relocate their current poses upon entering a pre-established map. However, existing 3DGS-based relocalization methods [144], [145] either require a coarse initial pose or are only capable of achieving relocalization in small indoor scenes. These methods struggle to perform relocalization in large-scale outdoor scenes without an initial pose. Unfortunately, it is challenging to obtain a coarse initial pose for relocalization in practical robotic applications. Therefore, a meaningful research direction is large-scale relocalization without prior poses. We believe that constructing a submap index library or descriptor based on 3DGS representation facilitates coarse pose regression. In addition, the coarse pose can be refined through a registration process that leverages geometric and appearance features within the 3DGS representation.
无先验姿态的大规模再定位是一个有意义的研究方向
关于Sim-to-Real Manipulation:Collecting real-world manipulation datasets is challenging, leading to a scarcity of data for training effective grasping in real scenarios. Therefore, grasping methods often require initial training in simulation environments before being transferred to real-world settings. Although 3DGS-based sim-to-real method [219] has been explored, it has limitation in generalization. Specifically, this approach heavily depends on scene-specific training, which hinders its ability to generalize and transfer learned knowledge between similar task scenarios. Consequently, this method still requires a substantial amount of real-world datasets for training. Furthermore, the discrepancies in material and physical properties between simulation and reality environments can lead to significant differences in training data distributions for manipulation tasks. These discrepancies may potentially result in entirely different operation strategies. However, existing method [220] only enables modeling the physical properties of real-world scenarios. Therefore, a promising research direction involves directly incorporating uncertainty and environmental features into the 3DGS representation to enhance generalization and property modeling.
Foundation Models in Robotics: Applications, Challenges, and the Future
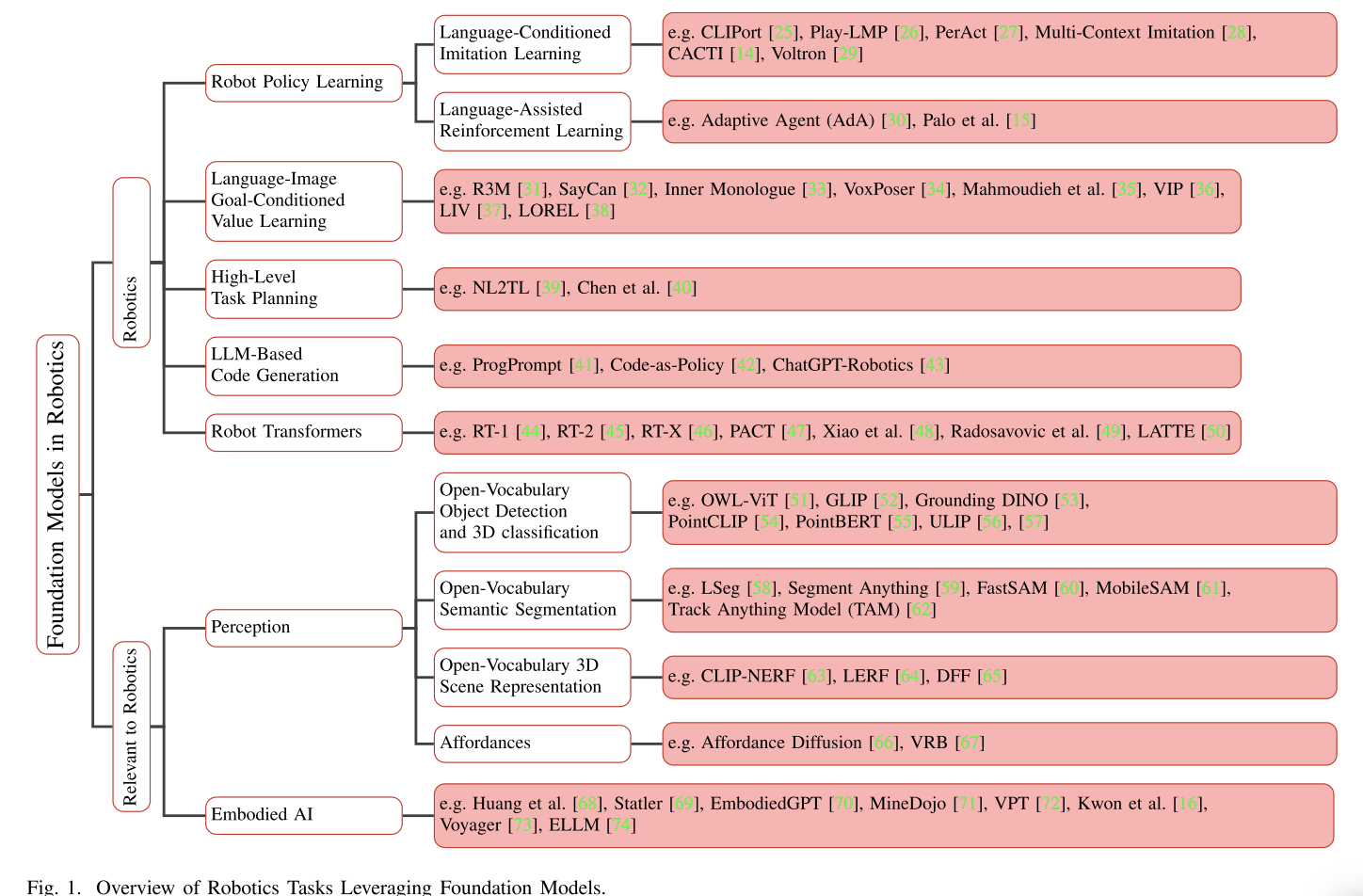
看起来NeRF相关的内容主要集中在“Perception”部分:
Open-Vocabulary 3D Scene and Object Representations
Scene representations allow robots to understand their surroundings, facilitate spatial reasoning, and provide contextual awareness. Language-driven scene representations align textual descriptions with visual scenes, enabling robots to associate words with objects, locations, and relationships.
Language Grounding in 3D Scene:
NeRF可以为机器人提供强几何先验,但其并不是foundation model。然而,CLIP这样的foundation model却可以和NeRF相结合,从环境中提取语义信息。因此后面出现了LERF,结合CLIP和NeRF。
目前的VLM可以对2D图像进行推理,但是并没有专门去考虑3D上的问题。但是可以用2D的VLM来监督3D的模型,比如FeatureNeRF。
Scene Editing
When an embodied agent relies on an implicit representation of the world, the capability to edit and update this representation enhances the robot’s adaptability. For instance, consider a scenario where a robot utilizes a pretrained NeRF model of an environment for navigation and manipulation. If a portion of the environment changes, being able to adjust the NeRF without retraining the model from scratch saves time and resources.
相关资料
Paper & Workshop:
- How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: a Survey, arXiv, 2024. [Paper]
- SLAM Meets NeRF: A Survey of Implicit SLAM Methods, World Electric Vehicle Journal, 2024. [Paper]
- Neural Fields in Robotics: A Survey, arXiv, 2024.[Paper]
- NeRF in Robotics: A Survey, arXiv, 2024.[Paper]
- 3D Gaussian Splatting in Robotics: A Survey, arXiv, 2024.[Paper]
- Foundation Models in Robotics: Applications, Challenges, and the Future, arXiv, 2023. [Paper]
- RoboNerF: 1st Workshop on Neural Fields in Robotics, ICRA, 2024. [Website] [Video]
知乎上相关的讨论:
nerf或者是跟其相关的3D重建方法怎么应用在自动驾驶或者机器人领域? - 刘斯坦的回答 - 知乎
https://www.zhihu.com/question/578721901/answer/3476777188这个回答讲的主要是如何将NeRF用于闭环仿真。所谓闭环仿真,就是穿越回到某个历史节点后,优化你的行为,然后对造成的后果进行仿真,修改历史。并且讨论了NeRF的Domain Gap有多大,提到了一个叫做NDS的指标,表示NeRF目前只是堪堪可用的。另外提到了有很多现实生活中的物体并不适合mesh建模,比如树叶、头发丝。
NeRF/3DGS&Beyond10.17(3DGS机器人综述、GS^3、Long-LRM、SplatPose+、LoGS、GSORB-SLAM、4-LEGS、Magnituder Layers等) - NeRF 3DGS日报的文章 - 知乎
https://zhuanlan.zhihu.com/p/1563839191这篇文章提到的第二篇论文,还挺有意思,传统方法不能操作豆子、坚果、大米,但是他们在3DGS上面做到了。
机器人技术中的 3D 高斯splatting:综述 - 黄浴的文章 - 知乎
https://zhuanlan.zhihu.com/p/4309431179昨天早上发的,还挺巧。



