论文阅读《PIN-SLAM: LiDAR SLAM Using a Point-Based Implicit Neural Representation for Achieving Global Map Consistency》
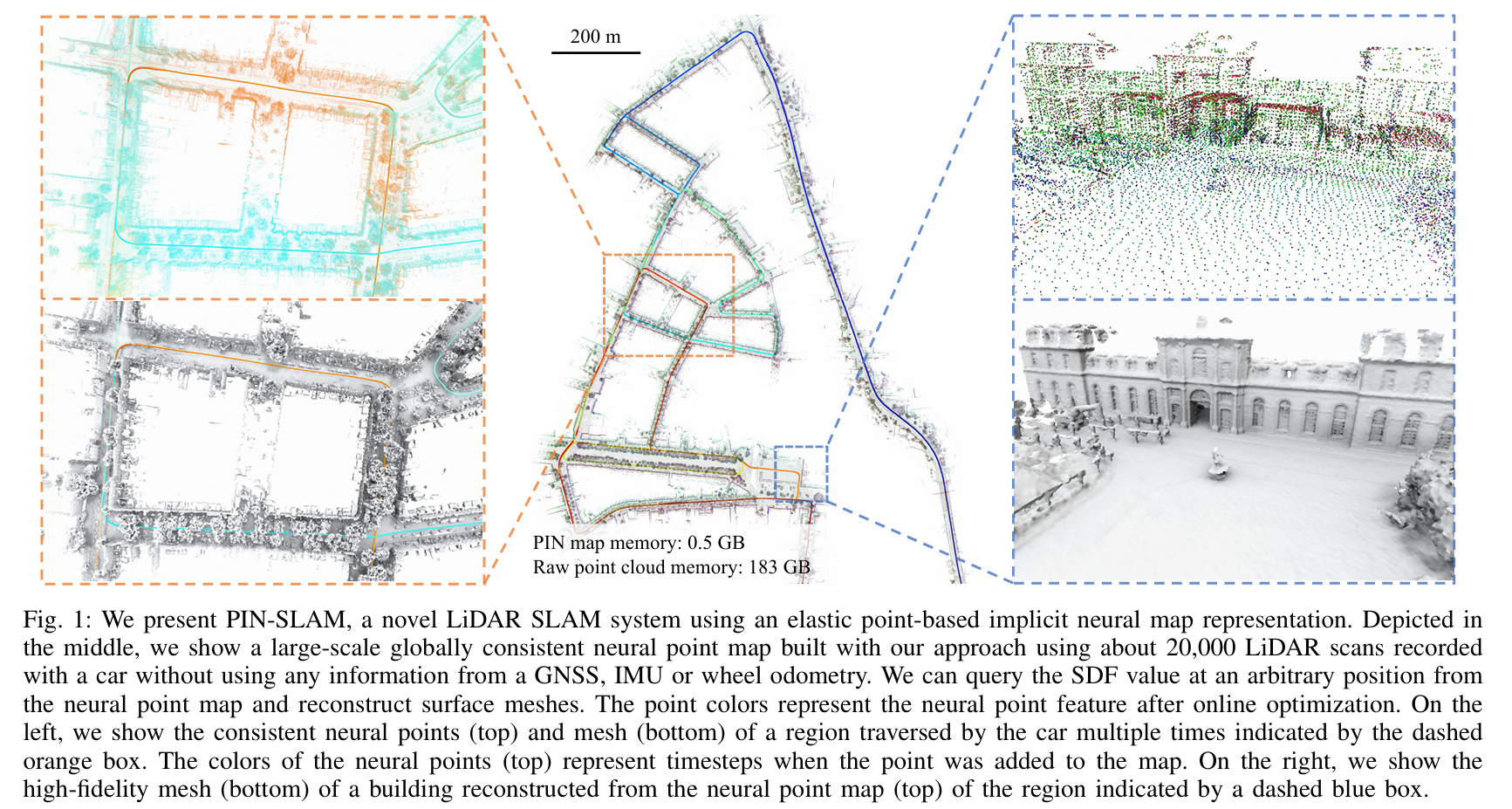
论文想要解决的问题:These SLAM approaches lack support for direct loop closure corrections and are not able to build globally consistent maps of larger scenes. This is mainly due to the usage of regular grid-based local feature embeddings, which are not elastic and resilient to loop corrections.
论文的核心目标:The main focus of this work is a LiDAR SLAM system for building globally consistent maps using a PIN map representation.
论文为什么选择neural point表示场景:We opt to use a neural point-based implicit representation, which has two main advantages over grid-based representations: the flexibility of spatial distribution and the elasticity for transformations. Recent work (Point-SLAM) only makes use of the first advantage for neural RGB-D SLAM at the cost of scalability and inefficient neighborhood querying. Instead, we exploit the second and more important advantage to build a globally consistentmap that can be corrected while online mapping after closing a loop, which is essential for large-scale LiDAR-based SLAM.
论文在Introduction提到,Mapping部分主要是基于之前的工作SHINE-Mapping,而Odometry部分是扩展了之前的工作LocNDF。
工作是延续的,非常扎实,令人羡慕。
论文提出了四个key claims:
- Our SLAM system achieves localization accuracy better or on par with state-of-the-art LiDAR odometry/SLAM approaches and is more accurate than recent implicit neural SLAM methods on various datasets using different range sensors.
- Our method can conduct large-scale globally consistent mapping with loop closure thanks to the elastic neural point representation.
- Our map representation is more compact than the previous counterparts and can be used to reconstruct accurate and complete meshes at an arbitrary resolution.
- Our correspondence-free scan-to-implicit map registration and the efficient neural point indexing by voxel hashing enable our algorithm to run at the sensor frame rate on a single NVIDIA A4000 graphics processing unit (GPU).
论文对基于Submap的方法的评价:The submap-based methods accumulate the observations as a submap and assume the submap is a locally defined rigid body. The pseudoglobal consistency is maintained by optimizing a graph linking submaps and their associated poses through submap-to-submap registrations. The usage of submaps decreases the number of nodes and edges in PGO, thus saving computational effort. However, these methods have issues of ambiguity in the overlapping region of the adjacent submaps and determining appropriate criteria for submap division to balance the rigidity and efficiency.
论文的Pipeline:
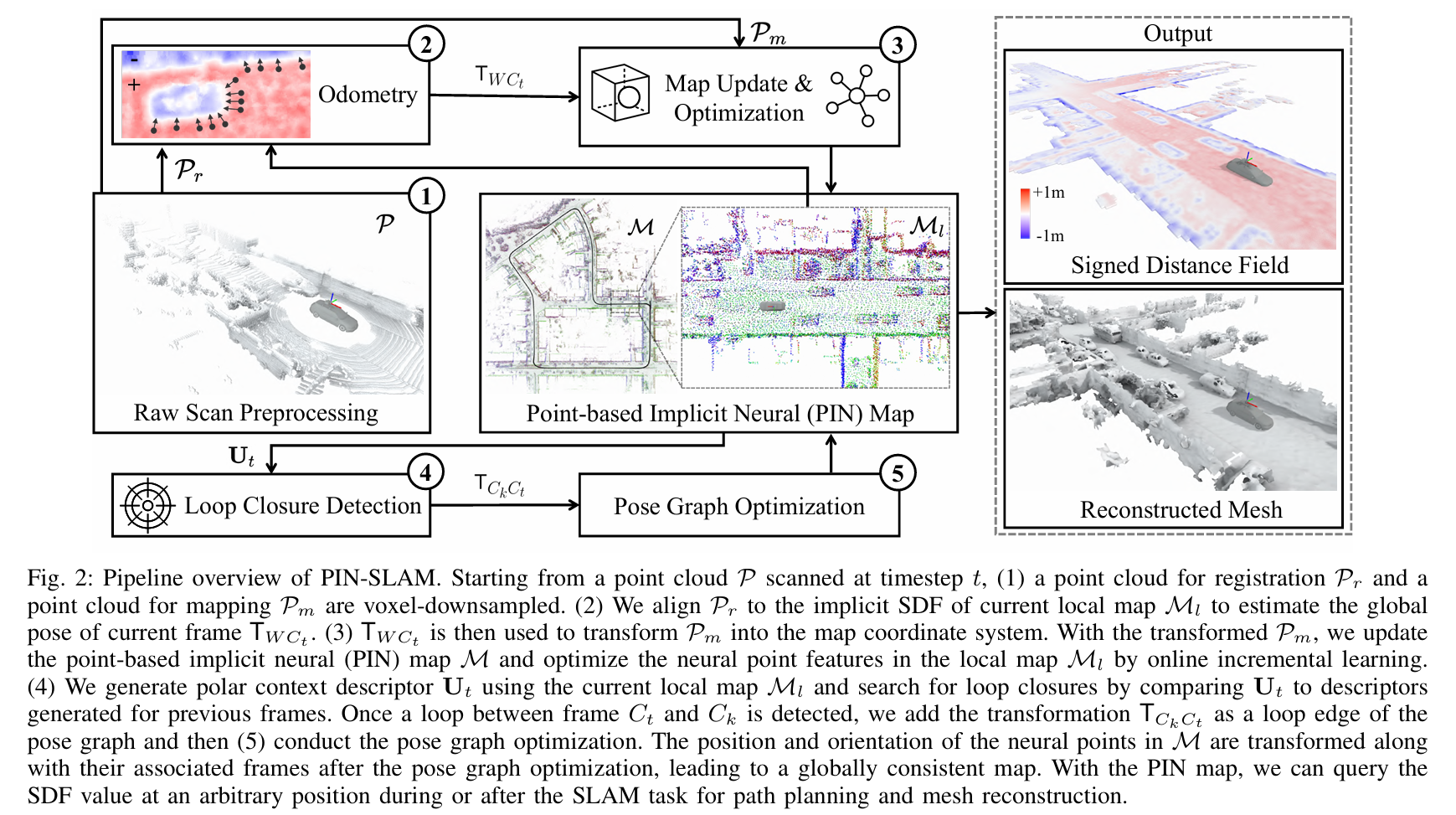
论文将他们的方法分成5个部分:
- Preprocessing:对于输入点云$P$,通过体素下采样到用于registration的点云$P_r$和用于mapping的点云$P_m$;
- Odometry:通过将点云$P_r$与local map $M_l$的implicit SDF进行配准来估计全局的位姿$T_{WC_t}$,并将前后两帧的变换$T_{C_{t-1}C_t}$作为一条边添加到Pose Graph $G$中。
- Mapping:根据地图$M$过滤掉用于mapping的点云$P_m$中的动态点,并沿着从传感器到$P_m$中每个点的射线进行采样,得到训练样本$D$,并使用在Odometry中计算的位姿$T_{WC_t}$将其转换到世界坐标系中。使用靠近场景表面的样本$D_s \subset D$来初始化新的neural point,并且将他们附加到地图$M$上,并且重置local map $M_l$,让其以当前位置$T_{WC_t}$为中心。使用采样的点$D_s$来更新训练样本池$D_p$,并且使用$D_p$和SDF监督来优化local map $M_l$中的neural point feature。最后将更新之后的local map $M_l$分配回global map $M$中。
- Loop closure detection:通过local map $M_l$生成一个本地极坐标上下文描述符$U_t$。之后通过比较当前帧和候选帧描述符之间的特征距离来搜索潜在的loop closure。一旦检测到当前帧$C_t$和候选帧$C_k$之间的存在闭环,就通过将当前帧点云$P_r$和以候选帧位置$t_{WC_k}$为中心的local map $M_l$进行配准,来验证是否真的存在闭环。如果配准成功,就将配准产生的变换$T_{C_kC_t}$作为新的边添加到Pose Graph $G$中。
- Pose graph optimization:加入loop closure edge之后,对pose graph $G$进行优化。优化之后对global map $M$中每个neural point的位置和方向及其关联帧进行变换,以保证全局一致性。在完成loop correction之后,对训练样本池$D_p$进行变换,并且重置local map $M_l$。
Neural Point-Based Map Representation
Map Representation:
neural point $m_i$保存了自己的位置$x_i$,并且有一个四元数$q_i$表示自身坐标框架的方向,特征向量$f^g_i$编码了局部的几何形状,时间戳$t^c_i$表示这个neural point创建的时间,时间戳$t^u_i$表示这个neural point最后更新的时间,$\mu_i$表示该点是否活跃、是否稳定。通过将neural point $m_i$与$t^m_i$时刻的位姿$T_{WC_{t^m_i}}$相关联,可以通过更新所有时刻的位姿来直接操纵地图,其中$t^m_i = [(t^c_i + t^u_i)/2]$。

其中这个四元数$q_i$,是用来保证neural point经过decoder解码得到的SDF对刚体变换具有不变性。如下图(a)部分所示,decoder$D^g_\theta$输入的是相邻neural point的feature $f^g_i$和在该neural point坐标系下被查询点的位置$d_i$,输出的是被查询点在该neural point影响下的SDF值$s_i$。整个过程与Point-NeRF和Point-SLAM计算体密度的过程基本一致。从下图(b)部分可以看到,这种策略使得预测的SDF值对局部的平移和旋转具有不变性,从而使得经过loop closure之后的地图具有弹性。
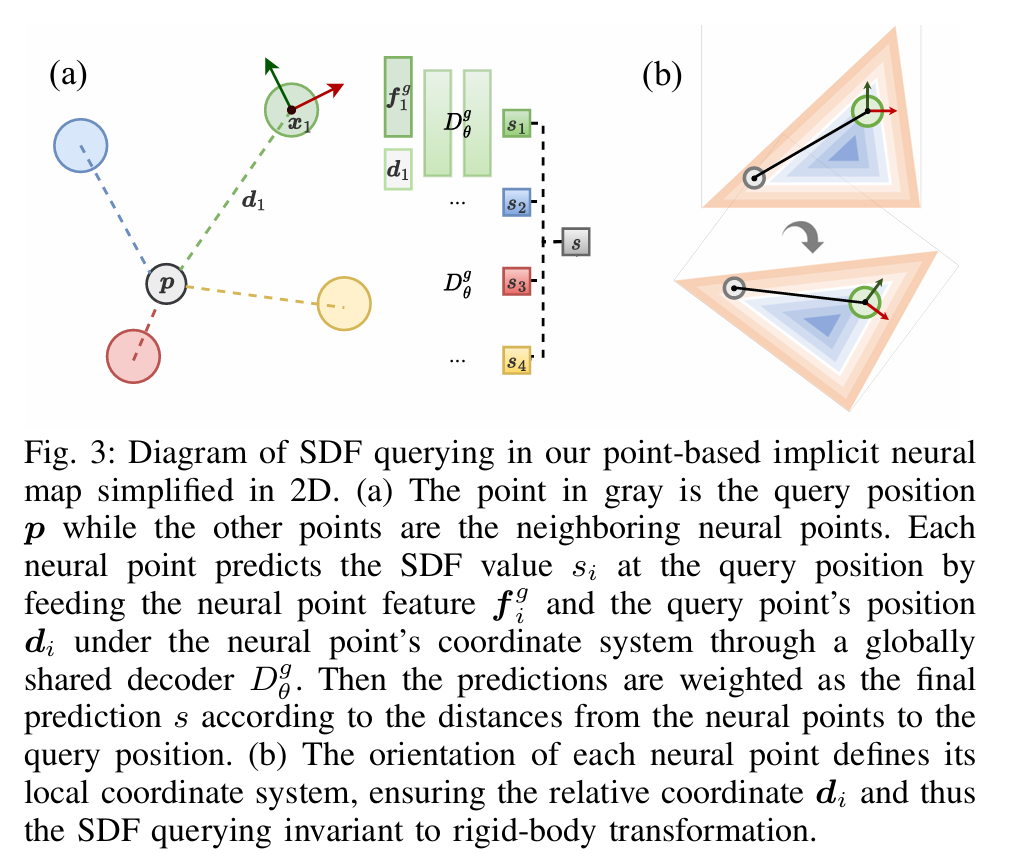
笔者认为这一步做的非常巧妙。四元数$q_i$定义了每一个neural point自己的坐标系,查询SDF需要把neural point的feature和查询点在坐标系中的位置输入到网络,相当于是每一个neural point都有了自己的“形状”,这些“形状”叠到一起构成了一个局部的几何表面。经过loop closure之后每个“形状”也会相应的被旋转平移,而不是简单的把“形状”的中心挪到校正之后的位置去,这样的话就不需要通过子地图把每个点的相对位置绑起来也能保证loop closure之后局部的几何稳定了。
这个过程有一点3DGS的味道了,但是单个3DGS很难像这里的单个neural point那样有非常明确的几何意义。
疑问:为什么Point-NeRF、Point-SLAM、Loopy-SLAM以及PIN-SLAM对于体密度或SDF值,都是单独解码之后,再通过逆距离加权?而颜色相关的,则是通过网络得到一个新的feature,将这个feature进行逆距离加权之后再解码得到颜色?
Map Data Structure:
为了实现快速的neural point索引和邻域搜索,PIN-SLAM维护了一个voxel resolution固定为$v_p$和hash table size为$T$的voxel hashing data structure。这个数据结构用于组织地图中的neural point,保证每个voxel中的neural point不超过1个。
PIN-SLAM借鉴了《Instant neural graphics primitives with a multiresolution hash encoding》和《“KISS-ICP: In defense ofpoint-to-point ICP–simple, accurate, and robust registration if done the right way》这两个工作,通过spatial hashing function $\kappa = h(p_W)$将$p_W \in \mathbb{R}^3$映射到hash table中的$\kappa \in \mathbb{Z}$。其中hash table中每一项存储地图中neural point的索引,默认值为-1,表示这一项暂时没有对应的neural point。
与Point-SLAM相比,PIN-SLAM借助voxel structure,实现了更快的进行K近邻搜索。
Map Initialization and Update:
PIN-SLAM会根据每个时刻输入的点云初始化或更新neural point。
对于在时刻$t$获取的世界坐标系$W$下的某一个点$p_W$,满足以下任意一种情况时,会初始化一个新的neural point $m_k$放到地图$M$中,并且将对应的hash table中的项设置为该neural point的索引,即$\kappa = k$。
- 对应的hash table中的项没有被占用,即$\kappa = -1$;
- 存在哈希冲突,但是在voxel structure中,存储的neural point与希望被添加的neural point之间距离很远;
- 存在哈希冲突,但是存储的neural point已经不再活跃,即$D(t) - D(t^u_\kappa) > d_l$。
新初始化的neural point $m_k$,位置$x = p_W$,而四元数被设置为单位四元数$ q = (1,0,0,0)$,特征向量被初始化为零向量$f^g=0$,创建时间和最后更新时间被设置为$t^c = t^u = t$,稳定性$\mu = 0$。
对于存在哈希冲突的情况2和3,原来存储的neural point不会被删除,只会让hash table不再索引到该点,该点仍然会被保存在global map中。论文说这样做是为了loop closure correction和globally consistent map adjustment。
Local Map:
PIN-SLAM使用local map是为了“avoid the alignment to the inconsistent historical observations caused by odometry drift”。
有很多NeRF SLAM和3DGS SLAM是frame-to-model的,可以看《How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: a Survey》的表格。
frame-to-model可能存在的问题是,model构建的不太好,导致frame的位姿计算的也不好,进而导致更新的model也不好,从而frame又在存在drift的model上再计算位姿。
而PIN-SLAM这里使用了local map,一定程度上可以避免这个问题(吗?)
论文提到之前一些工作中,local map是使用spatial window(比如MULLS、KISS-ICP)或temporal window(比如ElasticFusion)来定义的,论文觉得这两种方法可以结合起来使用,但又发现实际上里程计的drift可能与累计经过的距离成正比,而不是与时间成正比。因此,PIN-SLAM的temporal window用travel distance threshold来代替timestep threshold。
具体来说,对于以$t$时刻的位置$t_{WC_t}$为中心的local map $M_l$,这个local map包括spatial window $| x_i - t_{WC_t} |_2 < r_l$和temporal window $D(t) - D(t_i^c) < d_l$。其中$r_l$是local spatial window的半径,$d_l$是前面提到的travel distance threshold。
Map Training Samples:
和Point-SLAM的采样策略比较类似,PIN-SLAM是在表面采样一个点,再在表面附近采样$Ns$个点,表面附近的$N_s$个点的深度服从正态分布。另外,也会在表面到相机之间的空间中均匀采样$N_f$个点,在表面后的一定空间中均匀采样$N_b$个点。
最终会得到如下所示的训练样本:
$$
D = {(u_j,\hat s_j , t) | j = 1,…,N_t}
$$
其中,$N_t = M_t(1+N_s+N_f+N_b)$,$M_t$是用于mapping的点云$P_m$中点的个数,$u_j$表示第$j$个采样点,$\hat s_j$表示SDF值,被定义为$\hat s_j = |p|_2 - d$。论文提到$\hat s_j$可能总是会被高估,但是计算速度很快,而且在样本接近表面的时候是一个很好的近似值。
为了解决incremental mapping中的“catastrophic forgetting”,PIN-SLAM维护了一个训练样本池$D_p$,类似于Point-SLAM等方法中的关键帧。
Map Training Losses:


Preprocessing
在介绍论文pipeline到时候提到,PIN-SLAM对于输入点云$P$,通过体素下采样到用于registration的点云$P_r$和用于mapping的点云$P_m$,其中用于registration的点云$P_r$使用了较大的voxel size,而用于mapping的点云$P_m$使用了较小的voxel size。降采样的过程中,每个voxel只保留最接近体素中心的那个点。
Lidar存在因为运动导致的畸变,PIN-SLAM基于匀速运动模型,在该模型的基础上先通过逐点时间戳插值运动预测,在Odometry估计位姿之前对$P_r$进行去畸变,再通过Odometry估计的更准确的位姿来对$P_m$进行去畸变。
Odometry Estimation
该部分是基于已有的工作《LocNDF: Neural distance field mapping for robot localization》,LocNDF实现的是针对已知地图进行定位的方法。

之前的一些neural implicit SLAM,比如iMAP、Point-SLAM、Vox-fusion、NICE-SLAM等,优化目标是depth rendering loss,可以认为是point-to-point metric。而PIN-SLAM优化目标是point-to-model SDF loss,类似于ICP中的point-to-plane metric。
根据论文《Efficient variants of the ICP algorithm》的研究,后一种方法具有更快的收敛速度和更稳健的优化。
Mapping and Local BA
PIN-SLAM首先会去除动态点,只保留静态点用于Mapping。
下面提到了一个比较有意思的做法,PIN-SLAM是在最初的$F_{mlp}$个时刻内,同时优化local map $M_l$中的neural point feature $f^g$和decoder的参数$D^g_\theta$,而在$F_{mlp}$个时刻之后,就freeze $D^g_\theta$了,只优化neural point feature了。这样可以避免因为decoder不断变化导致的灾难性遗忘。

对于local BA,论文中是这么描述的:

Loop Closure Detection
PIN-SLAM首先检测local loop closure。即,对于当前位置$t_t$和当前帧$C_t$,与历史位置$t_{t_i}$和历史帧$C_{t_i}$,其中$t_i < t$而且$D(t) - D(t_i) > d_l$,判断两个位置是否满足以下关系:
$$
| t_t - t_{t_i} |2 < d{loop}
$$
这种local loop closure比较适合在drift较小的情况下,判断是否又回到了过去经过的位置。
如果没有检测到local loop closure,PIN-SLAM会通过比较frame-wise descriptors来搜索global loop closure。PIN-SLAM针对典型的驾驶场景,参考Scan Context和Scan Context++等工作,提出了一种“neural point feature enhanced local map descriptor”,论文为每一个时刻$t$的local map生成对应的local context descriptor $U_t$。
当检测到candidate loop,PIN-SLAM将当前帧点云$P_r$与候选帧$C_k$对应的local map $M_l$进行配准。
- 对于local loop,使用单位矩阵进行初始化;
- 对于global loop,使用semimetric localization的结果作为初值。
如果配准成功,PIN-SLAM会将配准之后的变换$T_{C_kC_t}$作为pose graph $G$中连接节点$C_k$和$C_t$的loop closure edge。否则,这个candidate loop会被否定。
Globally Consistent Implicit Neural Map Adjustment
笔者认为这部分是PIN-SLAM中最吸引人的,不过在前面的章节中已经有很多铺垫,论文在这部分着墨并不多。

EXTENSION TO RGB-D OR METRIC-SEMANTIC SLAM
论文在这个章节演示了如何将PIN-SLAM扩展到RGB-D或者Metric-Semantic SLAM。思路其实挺简单的,给每一个neural point增加对应的RGB或者Semantic的feature就可以了,然后创建对应的MLP作为decoder,当然为了进行训练,也会构建对应的损失函数。


实验部分
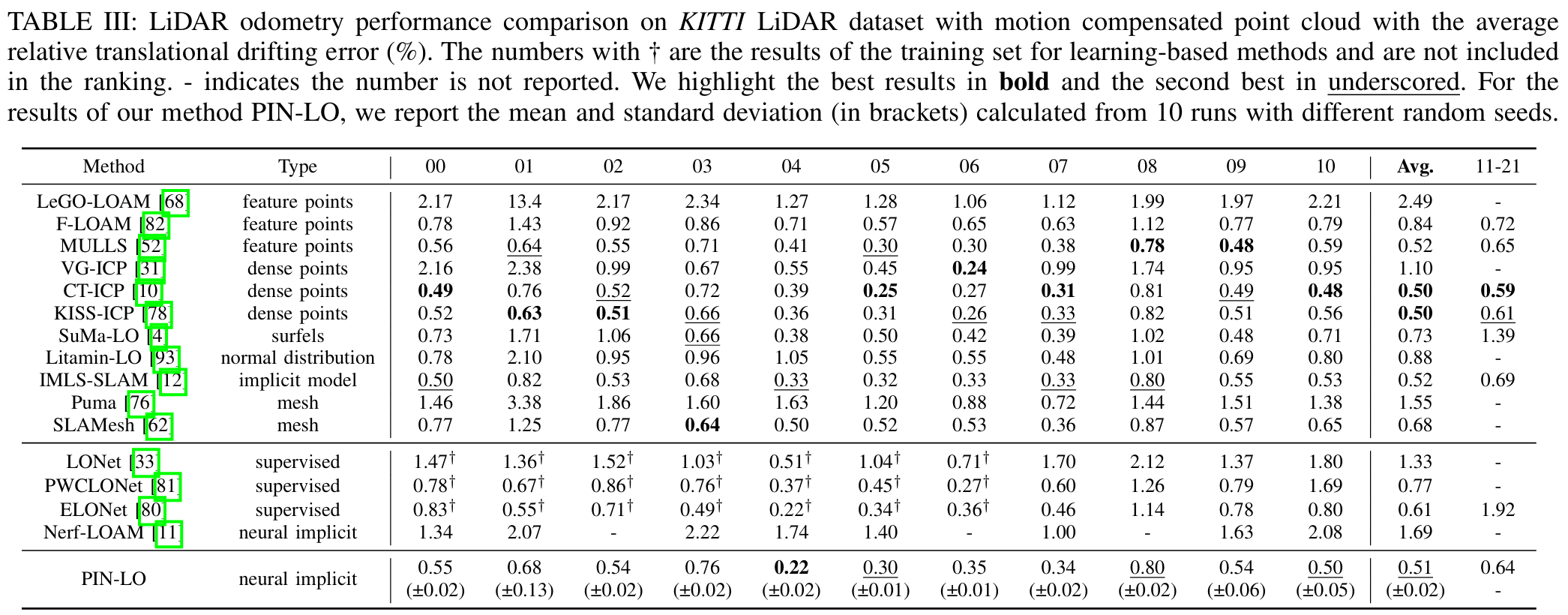
KITTI数据集上,论文的odometry与其他LIDAR odometry比较平均相对平移漂移误差(%):
KITTI数据集上,与不同的SLAM比较ATE RMSE:
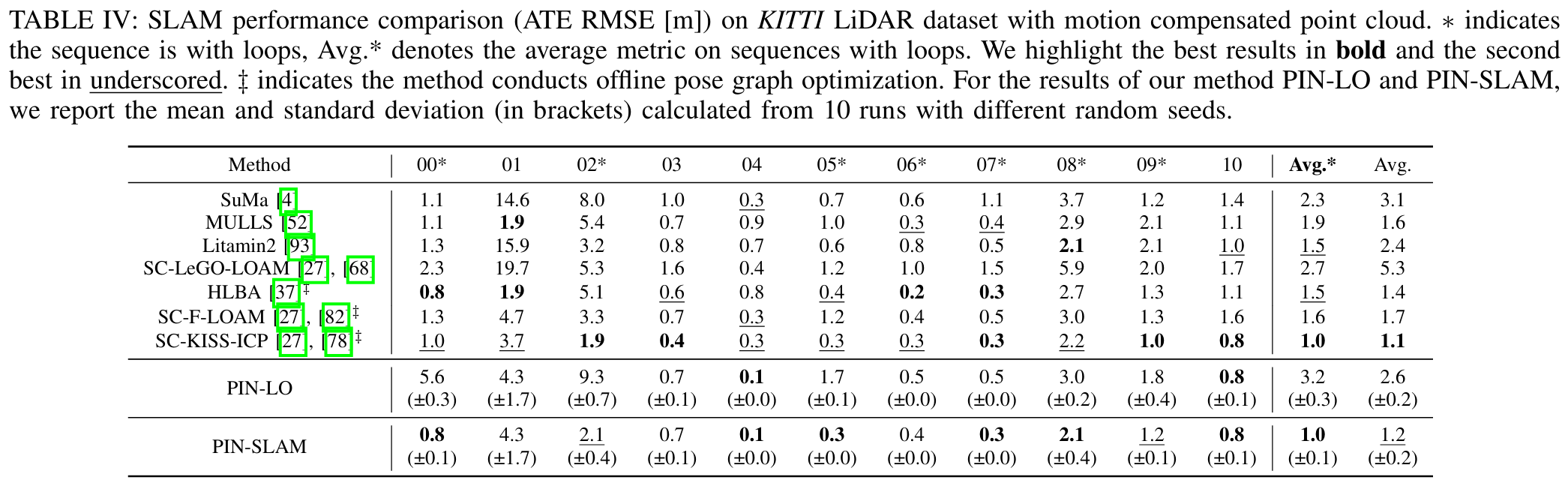
KITTI数据集上,Loop Closure的直观效果:
Replica数据集上,拓展到RGB-D的PIN-SLAM与其他NeRF SLAM方法比较ATE RMSE:

在kitti数据集的四个序列上,与传统方法(上)和基于学习的方法(中)比较loop closure detection的召回率:

在NEWER COLLEGE数据集上和其他方法比较三维重建的质量:

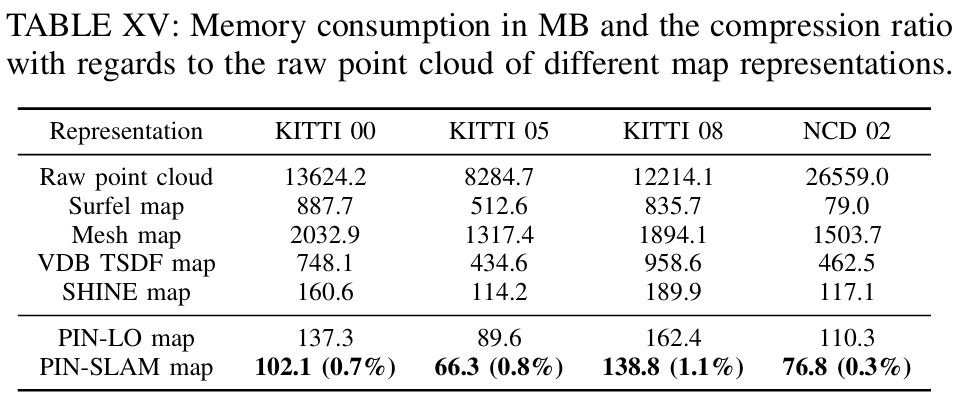
地图压缩率实验:
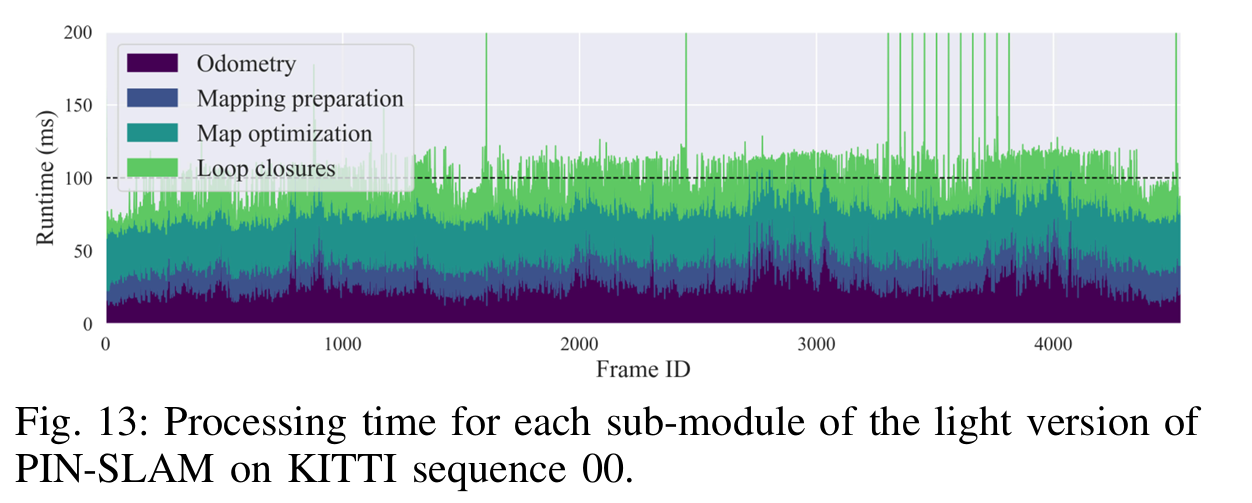
在KITTI seq 00上不同子模块的处理时间:
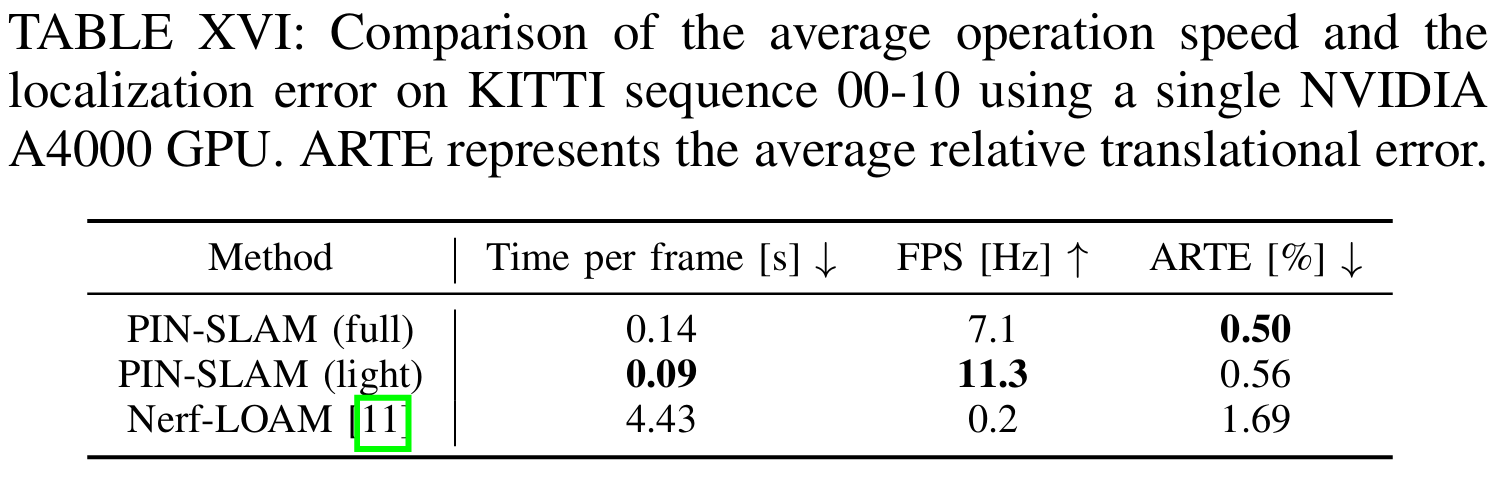
对KITTI seq 00-10的平均运算速度和定位误差的比较:
总结&讨论
这篇文章非常扎实,工作做得非常完整,实验做得也非常充分。论文的工作、实验紧紧围绕SLAM(Simultaneous Localization and Mapping)中的localization和mapping,没有像其他NeRF SLAM、3DGS SLAM方法一样展示PSNR、SSIM等结果(笔者认为PSNR、SSIM主要是新视角合成的指标了,放在SLAM来展示有点奇怪,不过好像大家都爱比较这几个指标)。从实验结果上看,无论是localization还是mapping都非常有竞争力。
令笔者眼前一亮的是论文中elastic neural point的设计,通过这一设计实现的loop closure能够调整场景中的neural point,非常惊艳。这还是笔者第一次在NeRF、3DGS的方法中见到可以调整场景表示(比如MLP、grid feature、neural point、3DGS)的方法。
理论上也可以让每一帧对应一个MLP,或者每一帧对应一个submap,但是这样的方法笔者觉得不是很好。
论文在Limitations and future work提到了几点:
- 可以引入IMU来实现更准确、高效的SLAM系统;
- 目前PIN-SLAM使用的是固定分辨率的neural point,后续可以考虑在场景中自适应的分布和移动neural point来提高重建的质量;
- 可以使用i-Kdtree等方法,在不使用voxel的情况下实现高效的最近邻搜索;
- 另外,也可以考虑借助语义信息进一步增强位姿估计和回环检测。



