论文阅读《MotionGS : Compact Gaussian Splatting SLAM by Motion Filter》
关键词:Compact、Motion Filter
提出了一种融合深度视觉特征、双关键帧选择和3DGS的基于3d图像的SLAM方法。
与现有的跟踪方法相比,该方法通过对每帧进行特征提取和运动滤波来实现跟踪。姿态和三维高斯的联合优化贯穿于整个映射过程。此外,通过双关键帧选择和新颖的损失函数实现了从粗到精的姿态估计和紧凑的高斯场景表示。实验结果表明,该算法不仅在跟踪和映射方面优于现有方法,而且占用的内存也更少。
本文提出了一种新颖的基于3dgs的密集SLAM方法——MotionGS。该方法集成了深度特征提取、双关键帧选择和三维图像。在跟踪线程中,我们从每张图像中提取深度特征,通过运动滤波获得运动关键帧,并采用针对3DGS的直接姿态优化,减少处理帧数,提高跟踪性能。最后,跟踪线程通过信息过滤器不断更新和维护一个信息关键帧滑动窗口。在映射线程中,设计了一个新的损失函数来同时优化关键帧位姿和diff-gaussian-rasterization中的三维高斯。跟踪和映射线程的双重优化实现了从粗到精的姿态优化,减少了存储需求。对室内RGB-D数据集的广泛评估表明,我们的方法在跟踪、渲染和映射方面具有一流的性能。综上所述,主要贡献如下:
- 提出了一种新的基于3DGS的密集视觉SLAM方法(将深度特征提取、双关键帧选择和3DGS相结合)。该方法不仅实现了精确的实时跟踪和高保真重建,而且同时支持RGB和RGB- d输入。
- 设计了一种新的双关键帧策略和新的损失函数,以提高跟踪精度和保持渲染质量,同时减少内存消耗。
- 我们的方法在Replica和TUM-RGBD数据集上实现了最先进的跟踪、映射性能,运行速度为2.5 fps,内存使用更少。
System Pipeline
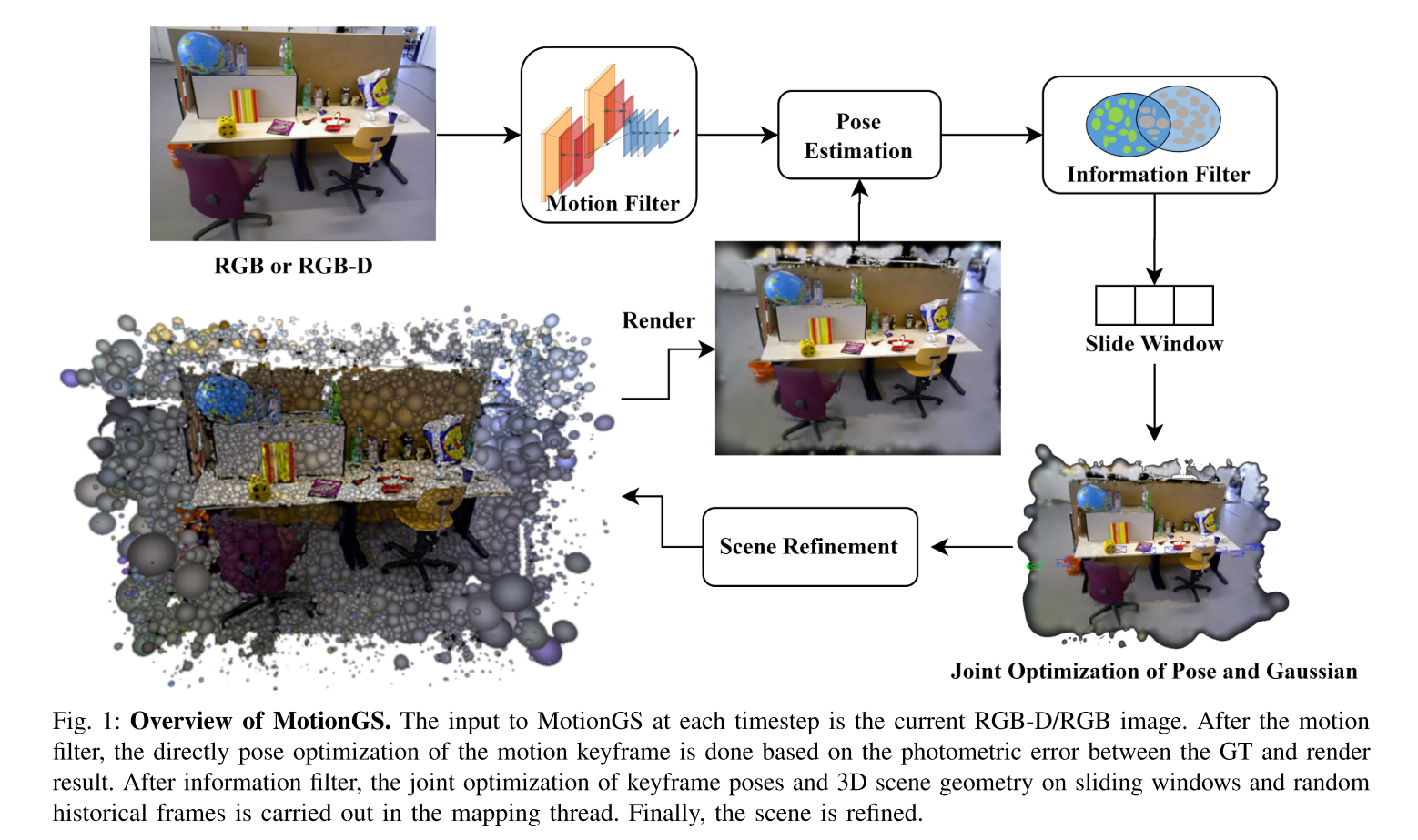
场景表示
受到了Compact 3DGS的影响,使用了原版的3DGS+learnable mask的结构,其中learnable mask的损失函数直接用的Compact 3DGS的。
最终的损失函数很简单,如下:

Dual Keyframe Strategy【暂时略过】
双关键帧策略,由运动滤波器和信息滤波器组成,分别对应于运动关键帧和信息关键帧。
之前有学长提到,这部分其实就是Droid SLAM里面的内容,只是这篇论文写的很隐晦。
这里我还要自己确认一下,把Droid SLAM这篇论文好好看看才行。
Motion Filter
对每一帧进行特征提取,只保留超过相关阈值的帧。与Droid SLAM类似,我们将三种不同的网络设计为:特征网络、上下文网络和更新网络。

Correlation Pyramid
略。。。
3DGS-based Direct pose optimization
这里提到了3DGS渲染的结果是有一定的模糊的,因此优化gt和渲染之间的部分像素是不切实际的。虽然优化整张图象速度会比较慢,但是它和3DGS的可微分渲染框架是一致的,因此这里还是使用所有像素直接用于位姿的优化。
深表赞同,但是这样速度真的会很慢吧。。。
这里说受到Gaussian Splatting SLAM工作的影响,李代数可以帮助找到最小的Jacobian

SLAM System
看到这里我可能大概明白这篇论文的实现了,我猜测是:
- 模仿Compact 3DGS,场景表示为:原始3DGS+learnable mask
- Tracking:基于Droid SLAM
- Mapping:3DGS和pose的联合优化,参考Gaussian Splatting SLAM
在上面的基础上,还有一些小细节、小调整。
实验部分
略
直播课程
MotionGS是基于MonoGS的,理由如下:
其中2、3、4点是最最重要的!!!

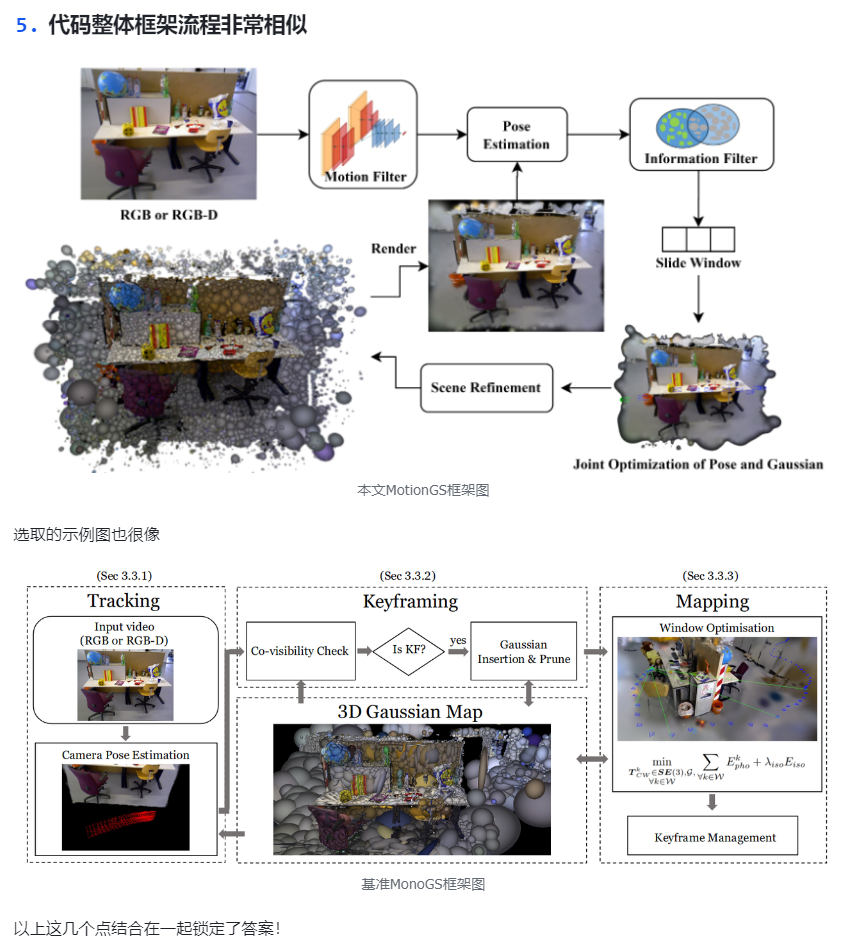
Dual Keyframe Strategy中,运动滤波器 Motion Filter 和 相关金字塔 Correlation Pyramid是从Droid SLAM缝合过来的:


而信息滤波器可能只是在MonoGS的基础上做了一些小修改:

思考
必须要好好看一下Droid SLAM了,很多新工作都用的这个。
Gaussian Splatting SLAM这篇工作做的公式推导、以及他们修改的diff-gaussian-rasterization有一些新的工作用上了,后面要多注意一下。
最值得注意的还是论文里面的这个观点,我也是很认同的:
Firstly, it is crucial to acknowledge that the rendering results of 3DGS inherently exhibit some degree of blur. It is impractical to optimize the partial pixels between real photos and rendered images. Although the pose optimization using the entire photo may slightly lag in speed, it aligns with the differentiable rendering framework of 3DGS. Therefore, all pixels are directly used to the pose optimization framework based on the photometric error between real photos and rendered images.
首先,承认3DGS的渲染结果固有地表现出一定程度的模糊是至关重要的。优化真实照片和渲染图像之间的部分像素是不切实际的。虽然使用整个照片的姿态优化可能会在速度上略有滞后,但它与3DGS的可微分渲染框架保持一致。因此,所有像素直接用于基于真实照片和渲染图像之间光度误差的姿态优化框架。



