论文阅读《RTG-SLAM: Real-time 3D Reconstruction at Scale Using Gaussian Splatting》
Abstract
我们提出了实时高斯SLAM (RTG-SLAM),这是一个基于RGBD相机的实时三维重建系统,用于大规模环境的高斯溅射。该系统具有紧凑的高斯表示和高效的实时高斯优化方案。我们迫使每个高斯函数要么是不透明的,要么是接近透明的,不透明的高斯函数拟合表面和主色,透明的高斯函数拟合剩余色。通过以不同于颜色渲染的方式渲染深度,我们让单个不透明高斯很好地拟合局部表面区域,而不需要多个重叠的高斯,从而大大降低了内存和计算成本。对于动态高斯优化,我们显式地为每帧三种类型的像素添加高斯:新观察到的,具有大颜色误差的,和具有大深度误差的。我们还将所有高斯函数分为稳定的和不稳定的,其中稳定的高斯函数被期望很好地拟合先前观察到的RGBD图像,否则不稳定。我们只优化不稳定高斯函数,只渲染被不稳定高斯函数占用的像素。这样,无论是需要优化的高斯数还是需要渲染的像素都大大减少,并且可以实时进行优化。我们展示了各种大型场景的实时重建。与最先进的基于nerf的RGBD SLAM相比,我们的系统实现了类似的高质量重建,但速度约为两倍,内存成本为一半,并且在新视图合成的真实感和相机跟踪精度方面表现出卓越的性能。
看完Abstract,感觉这篇文章主要的工作是:研究了各种让SLAM结果变好的==策略==
Method

Compact Gaussian Representation
使用Gaussian表示场景:
- 每个高斯要么不透明,要么几乎透明。Each Gaussian is determined once after being added to be opaque (𝛼 = 0.99) for fitting the 3D surface and dominant color, or to be nearly transparent (𝛼 = 0.1) for fitting the residual color.
- 每个高斯认为是一个ellipsoid disc或者surfel。We also treat each Gaussian as an ellipsoid disc (or surfel), and record the surfel parameters including the normal n𝑖 , the confidence count 𝜂𝑖 , and the initialization timestamp 𝑡𝑖 .
对于image rendering,这里应该是和Gaussian Splatting一样的,没有做什么特殊的处理;
对于depth rendering,论文说这是他们这部分的关键:
当前的所有Gaussian SLAM渲染深度的方式都和渲染颜色的方式一样,用alpha blending。但是这会导致单个高斯渲染的深度是从中间到两边下降的,不适合用来单独拟合一些近似是平面的区域。论文这里放了一张图来展示;
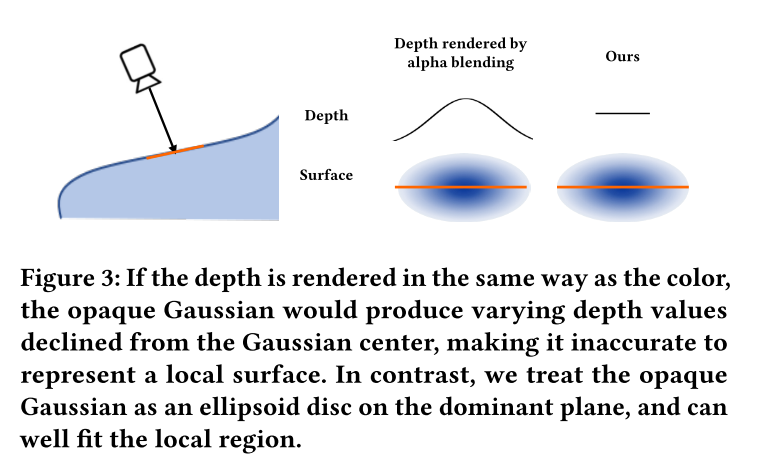
==疑问:目前对rendering部分理解的不是很透彻,有两个疑问==
为什么会导致深度从中间到两边是下降的呢,是因为3D向2D投影的过程导致的吗?
如果这样的话,RGB的渲染会不会也是从中间到两边下降的?或者说球谐可以解决这个问题,因为每个像素都是一条单独的射线?(如果球谐可以解决这种问题,还不如让深度单独带几个球谐系数)
每个高斯都能很好的拟合表面的局部区域,不需要多个高斯;
depth rendering的核心思路是:对于每个像素,计算view ray与距离最近的不透明ellipsoid disc的交点来获得像素的深度。
ellipsoid disc就是高斯椭球两个相对长的轴构成的椭圆面,因为论文前面提到了把短轴作为高斯的法向。
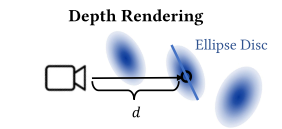
The normal vector is defined as the direction of the smallest eigenvector.
看下面的公式,其实做的也挺保守:
- 不相交就空着,当成-1(为什么会不相交呢)
- 如果有个高斯和相机平面的夹角比较小,影响的像素点比较多,才会把这个高斯当成Ellipse Disc来看;
- 而如果夹角比较大,影响的像素点少,当成Ellipse Disc处理可能误差也比较大,于是这部分的像素的深度都是根据高斯的中心点来算的。

Online Reconstruction Process
这部分看来是把整个系统都讲了一遍
Input pre-processing
根据输入的RGB和Depth,计算local vertex map和local normal map,再利用估计的相机位姿转换成global vertex map和local normal map
Gaussians adding
这里评价了Gaussian Splatting的Density Control策略是低效的,然后说自己利用基于几何和外观的高斯添加策略是更有效更可靠的,具体是根据渲染的结果计算一个掩码来确定为哪些像素添加高斯:
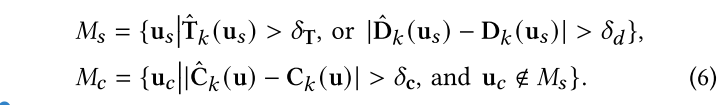
这里$M_s$是应该添加新几何图形的区域,它的计算依据是:像素射线经过很少的高斯或者没有经过高斯,即新观测的区域;以及深度重渲染的误差过大,即新观测的表面区域与现有场景在这个视角下渲染的结果有区别。
这里$M_c$表示几何上准确但颜色误差过大的区域。
这里添加的策略是:
对于$M_s$,添加高斯并且不透明度设置为0.99;
对于$M_c$,它已经与场景中现有的不透明高斯相关联,如果是不稳定的高斯,就可以进一步优化来适应颜色,这样就不继续添加高斯;如果是稳定的高斯,那就在它的基础上加入一个不透明度为0.1的高斯来校正颜色误差。
使用透明高斯光束的优点在于,这种低不透明度的高斯光束不会引起光能的明显衰减,对其他视图的颜色影响很小。另外,在深度渲染的过程中,它们会被算法自动过滤掉,因此不会影响深度渲染。对于不透明高斯点,它们的大小被初始化为尽可能多地覆盖场景,很少重叠,而透明高斯点的半径被限制在0.01m以下,以消除对其他像素渲染结果的干扰。
从这里看,论文更关注几何信息,而对于颜色信息则通过添加透明高斯并加以重重限制来保证不干扰深度渲染结果的同时让颜色的渲染尽可能准确。
Gaussian optimization
根据时间顺序确定了一个窗口,每次优化都是从窗口内随机采样一帧。
不透明度的学习率设置为0,因此不透明度是固定的,不会被优化。
直接不放到优化参数里不就好了,设置成0是因为,懒得改代码?
color和depth还是很经典的损失函数,这里论文希望透明高斯函数专注于在不影响其他区域的情况下精炼局部的颜色,因此设计了一个正则化项。总体的损失函数是:

论文注意到优化后的高斯函数能很好拟合当前时间窗口,但是对于之前的视图,渲染质量会下降。这里他们提出了一种融合策略,通过加权平均的方法把当前的结果和以前的结果融合到一起,这样可以有效避免遗忘问题:
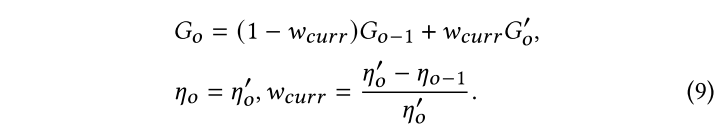
优化所有高斯是非常耗时的,因此论文不优化稳定高斯,只关注受到不稳定高斯分布影响的像素,从而避免对所有像素的优化。
State management
一些稳定高斯和不稳定高斯之间的转换策略,以及错误高斯(长时间不稳定)的删除

Camera tracking
使用frame-to-model的ICP算法作为front-end odometry,使用前一帧中优化的高斯函数来渲染深度图、法线图,并且转换到全局空间,然后给定当前帧,通过最小化3D反向投影误差得到位姿:
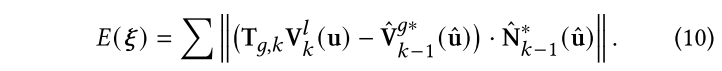
论文还提到为了减小大场景的累积漂移,用了类似ORB-SLAM2的后端优化线程,完成位姿估计的同时还会保留一组3D landmark用于后端的优化。
和GS_ICP SLAM相比,这里ICP用的还是挺生硬的,需要保留一组3D landmark,存在数据冗余的情况。
我怀疑这里用的就是ORB-SLAM2的RGB-D前端,因为实验部分Table 2的数据也太好看了,非常接近ORB-SLAM2的结果。
Keyframes and global optimization
- 基于相机的运动构造关键帧列表,旋转角度或者相对平移超过了阈值就添加关键帧。
- 只优化每个关键帧上误差前40%的像素,并且优化过程中不更新高斯的位置,使用0.1倍率的原始学习率来优化其他的参数。
EVALUATION
见原论文
SUPPLEMENTARY MATERIALS
只记录个人认为值得注意的细节
GAUSSIAN INITIALIZATION
每个新的高斯都会初始化为一个平面圆盘,根据最近的三个高斯来计算轴的长度,三个轴的比例为1:1:0.1
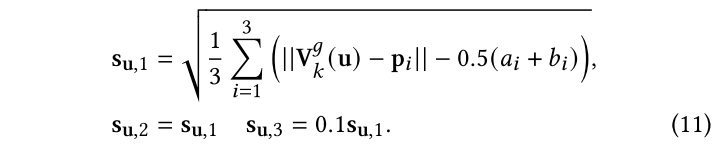
IMPLEMENTATION DETAILS
系统由三个线程构成:高斯优化、前端在线跟踪、后端图优化。
前端在线跟踪是用python+pytorch实现的,而后端优化部分是基于ORB-SLAM2用C语言实现的。
个人评价
这篇文章主要是用了很多简单有效的改进策略,在工程上做了很多的工作。
另外,这篇论文的前端里程计也是基于ICP的方法,后续可能会有越来越多的RGB-D高斯SLAM使用传统的点云配准方法来做前端的里程计。高斯毕竟还是显式地表示,和点云很相似,从基于渲染损失优化位姿到传统点云配准求解位姿的发展是必然的。



