论文阅读《MIPS-Fusion: Multi-Implicit-Submaps for Scalable and Robust Online Neural RGB-D 》Reconstruction
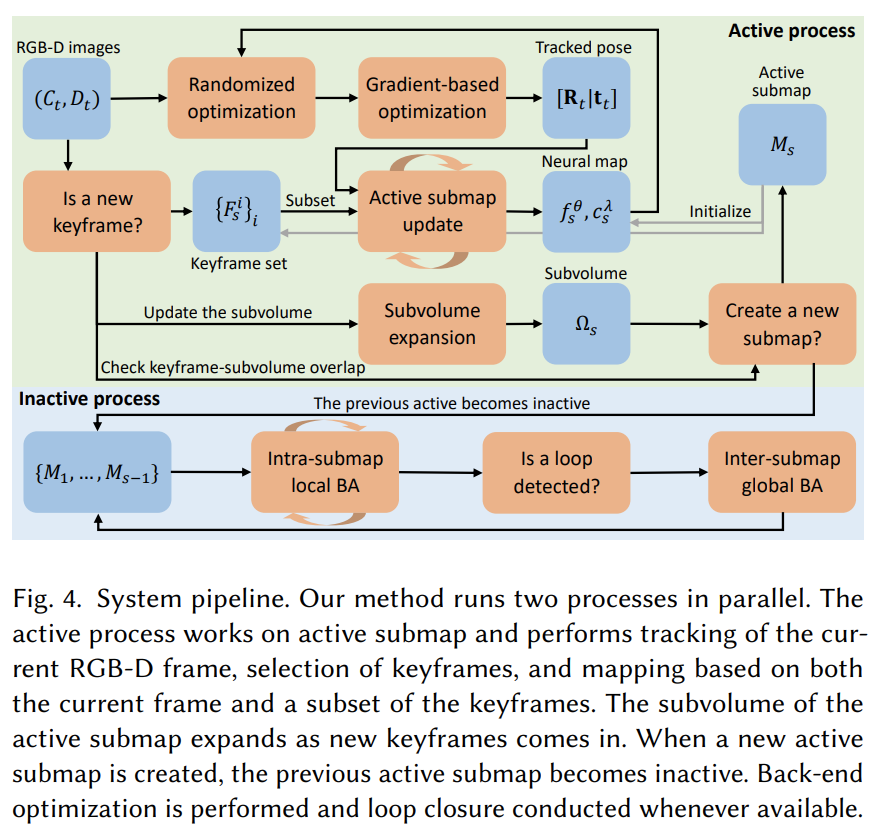
System Pipeline
Multi-Implicit-Submap Representation
对于每一个子地图,表示为:TSDF(MLP分类器)、radiance filed(MLP场景表示or解码器)、第一个关键帧在全局地图中的姿态、关联的关键帧集合、axis-aligned长方体体素。
这里提到一个观点:构建子地图比较灵活,每一个子地图都可以作为一个整体进行转换。同时,由于子地图局部坐标分布导致low data bias,这样更容易学习。
Classification-based neural TSDF
区域内不重叠的点就直接查询MLP分类器拿到TSDF值了,而对于重叠部分的点,会使用如下公式,根据不确定性计算权重,再求一个加权和:
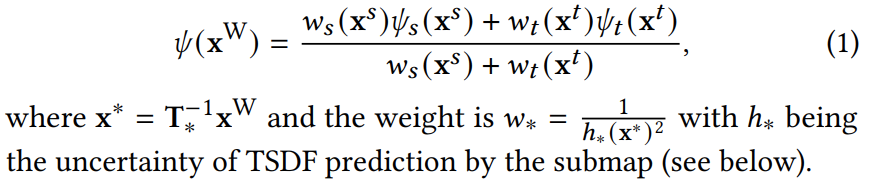
论文把TSDF值分成了5类,如下:

查询MLP分类器的话,就会得到该点处于这五个类别的概率,然后使用soft argmax函数就能拿到该点的TSDF值。
这一步还挺妙的,用分类器。看论文的Fig.6. 分类器的方法收敛的速度更快。
好像有一些深度估计的方法也是按照分类器的思路去做的。

这个所谓的soft argmax函数加了一个额外的参数,这个参数论文说是用来调整平滑度和梯度的。
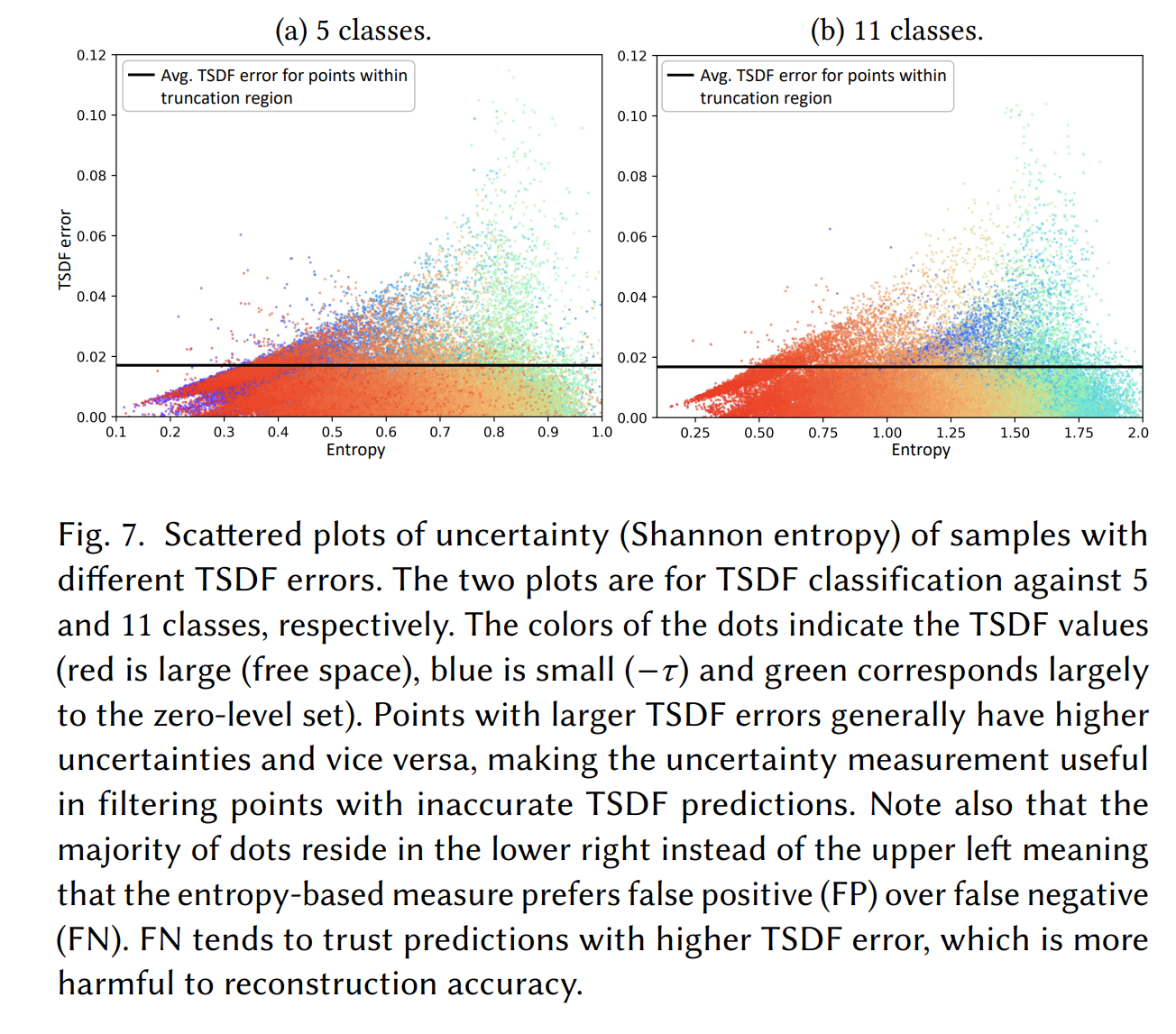
另外由于用这种分类器的方式,还可以计算出来TSDF的不确定度,而且对类别数量不敏感。下面这张图说明,至少Shannon entropy低的情况下,TSDF error极大概率也很低,所以可以只晒选Shannon entropy低的点。(主要是很多情况下Shannon entropy高,但实际上TSDF error又很低,存在假阳性的情况)
Neural radiance field
上面的TSDF分类器表示了场景的几何结构,但是对于外观,这篇论文还是沿用了神经辐射场的方法,这部分看起来是主要参考的iMAP,省略了视线方向的编码。
Color and depth map rendering
这部分就是根据TSDF值去计算权重了,权重的计算方法和Co-SLAM比较相似。
本文的:
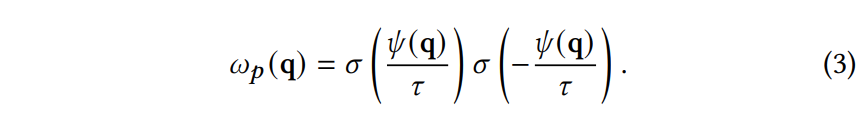
Co-SLAM的:
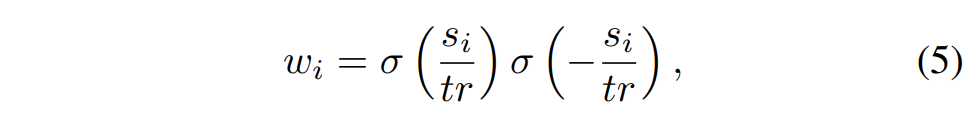
另外,Co-SLAM应该是沿着射线进行采样了一系列的点;MIPS-Fusion声称他们是截断区域内进行采样。
疑问:如何做到截断区域内进行采样?应该是NICE-SLAM那种,在深度值前后一定区域进行采样?
Optimization Losses for Mapping and Tracking
包括四种损失:
- depth to TSDT loss,d2t
- TSDF truncation-region loss,tr
- TSDF free-space loss,fs
- RGB rendering loss,rgb
d2t用于tracking(RO和GO),tr、fs、rgb用于mapping和GO-based pose optimization
疑问:RO和GO是什么,暂时没看到论文提及
RO指的是随即优化,randomized optimization
GO指的是gradient-based optimization
后面三种loss近期的工作经常使用,而d2t本文声称是highly effective and efficient for tracking optimization
另外,本文没有使用常见的depth rendering loss,因为tr和fs已经覆盖depth rendering loss了
Depth-to-TSDF loss we define a frame-to-model error metric to measure the fitness of how well 𝐷𝑡 “fits into” the TSDF under pose
大概意思就是,在这个pose下,对于某个像素p,根据观测的深度值计算出它世界坐标系下的坐标,再拿到在当前子图的坐标,去查询子图下定义的TSDF,如果pose正确的话,这个点到曲面的距离应该为0,即TSDF应该为0

TSDF truncation-region loss The truncation-region loss is devised to supervise the MLP to output correct SDF values for points within the truncation region
大概意思就是,根据传感器观测深度和采样深度计算一个SDF值,然后和网络预测的值做差,看看对不对。

TSDF free-space loss The free-space loss directs the neural map to output a value equal to the truncation value 𝜏 for the empty region in the visible side of the viewing frustum
这里应该是希望TSDF MLP能够准确表示free space,即相机到物体表面的视锥内,TSDF值应该为1,对应的,网络的输出也应该尽可能地接近截断距离。这样设计有助于提高三维重建的质量和精度。

RGB rendering loss 非常常规的损失函数了

Tracking with Hybrid Optimization
这里的Hybrid Optimization指的是结合了随即优化(RO)和基于梯度的优化(GO)。在固定次数的 RO 迭代之后,针对另外固定次数的迭代的两个损失调用 GO。
关于RO:Randomized pose optimization
是比较新鲜的东西,很遗憾我不会,需要再好好了解一下!
看起来是只围绕d2t这个loss的优化。
疑问:这里提到的particle filter optimization(PFO)、Particle Swarm Template(PST)等优化方法不是很了解。
关于GO:Gradient-based pose optimization
和NICE-SLAM、Co-SLAM等方法一样,很传统的优化方法
根据公式17,是围绕d2t+rgb的loss优化,而且有权重
Mapping of the Active Submap
Submap allocation这里提到“the far clipping plane is set to 5m”,这样的话,我觉得可能比较适合室内场景,而且后面也说subvolume的任意一边达到7m的时候,就会停止扩展,那应该就会开始准备开启新的submap了。
Submap initialization这里提到创建新的submap的话,会使用共享的那个关键帧迭代500轮。
由于这里毕竟是TSDF MLP+NeRF MLP的形式,所以必须迭代了
如果是point slam或者3dgs based的方法,我认为完全可以用这个关键帧对应的点云
Keyframe selection的选择标准是information gain of a frame。在论文所使用的方法下,基于depth-to-TSDF loss就可以进行过滤了。直接看像素的比例,如果误差小的比例低于某个阈值,就认为可以作为新的关键帧了。论文这里还规定了两个关键帧的最小间距为30帧。
放到3dgs里面的话,我可以做不透明度mask,看看mask掉了多少区域,然后选择一下;
另外,也可以看视角变换的幅度,比如即使没有mask的区域,视角变化大,也可以作为关键帧。
Active submap optimization这里提到每个帧的优化包括5个不同的帧,包括:当前帧、submap第一个关键帧、随机选择的另外三个关键帧。
根据下面的损失函数,看起来pose和d2t、rgb关联比较大,而mapping更关心tr与fs。
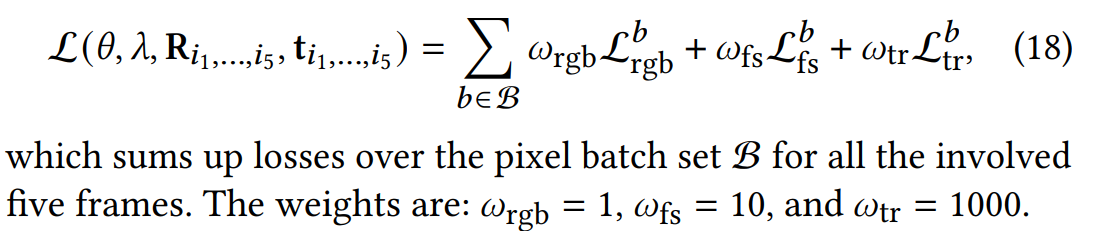
Back-end Optimization and Loop Closure
开头提到这个工作分成两个线程,一个是tracking and mapping activate submap的,一个是refinement inactive submap的。
Optimization of inactive submaps这里说,按顺序重复优化每一个inactive submap,对于每一个正在优化的submap,从中随机选择四个关键帧+第一帧进行优化,迭代10次。
这个是因为之前追求效率优化的比较少,所以回头再继续优化优化吗?
Handling pose jump at submap revisiting这里说,当相机移动到inactive submap的subvolume中时,这个inactive submap会被激活。为了避免位姿漂移和错位,先用这个重叠关键帧和其他关键帧对新激活的submap进行local BA,然后再开始新的tracking。
这不就,阻塞住了?不会影响后续帧的tracking嘛???
不过现在的nerf based or 3dgs based slam都是读数据集,不太在乎实时性,这里阻塞了肯定也不会说。。。说到底还是看个平均fps,中间阻塞几下不在乎。
Loop detection and closure这里说论文更关心submap级别的回环检测,并且目前实现的是涉及至少四个submap的loop。论文认为两个连续子地图之间的漂移通常非常小。
论文的方法肯定只能做submap级别的loop closure
疑问:这个涉及至少四个submap的loop,或许指的是四个以上submap的subvolume重合的时候才回环一次???也可能是说相机轨迹跨越了至少四个不同子地图之后,才开始检测闭环???
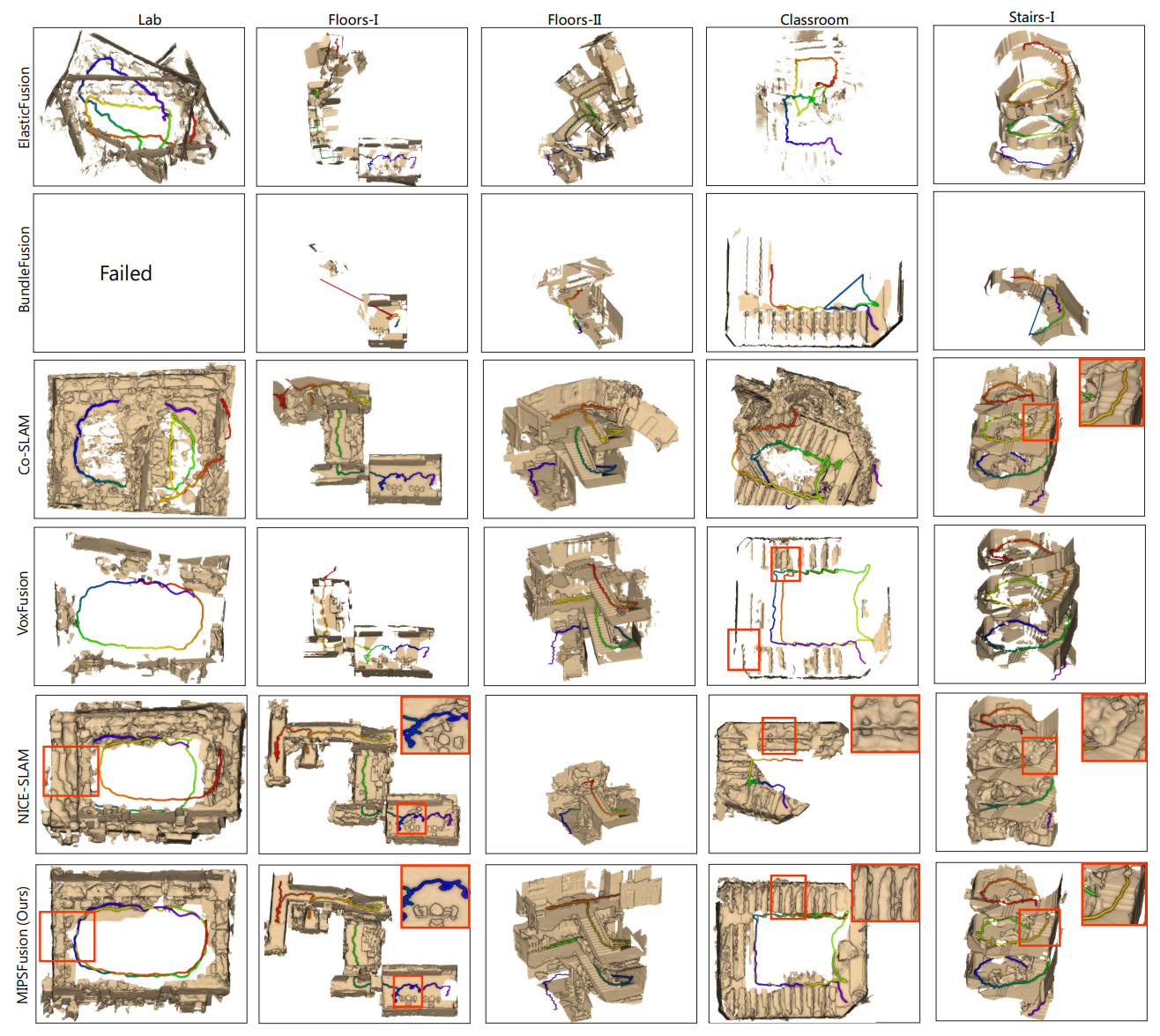
实验部分
看论文的消融实验,看起来RO、SR、LC对结果的影响很大。其中如果没有SI、SR、LC,甚至可能会跑不完一个数据集。
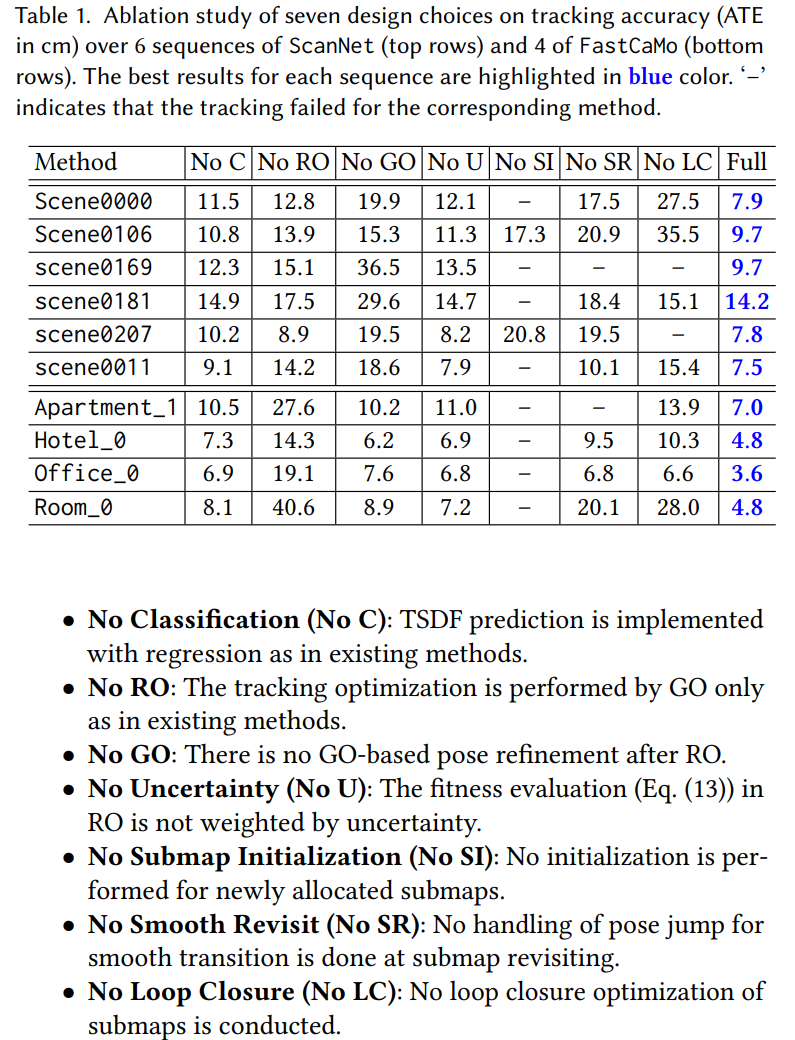
另外实验也证明了RO、GO、RO+GO的方法中,RO+GO是最好的。
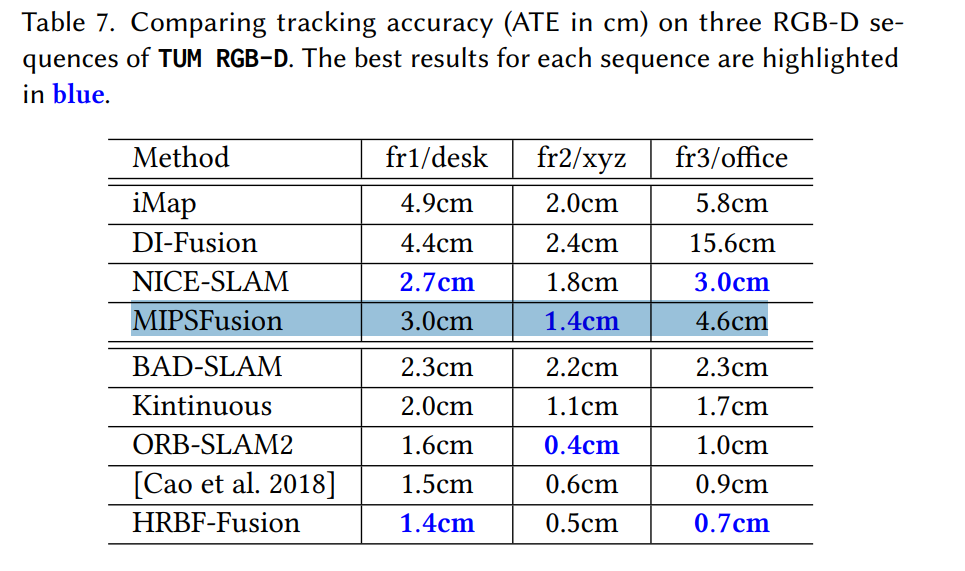
看了TUM RGBD数据集的结果,还是有一个问题:在常见的三个数据集上,MIPS-Fusion没有表现出非常亮眼的效果,可以理解。但是,为什么不放一些大场景、带回环的数据集的结果呢???
不过这里倒是展示了FastCaMo-Large datasets的一些结果,可以看到论文方法的优越性