论文阅读《ESLAM: Efficient Dense SLAM System Based on Hybrid Representation of Signed Distance Fields》
和co-slam同时期的工作,他们都使用了TSDF来表示场景。
似乎E-SLAM不知道有co-slam,但是co-slam知道E-SLAM。
宣称:
- 比iMAP和NICE-SLAM准确度高了50%
- 比他们快了10倍
System Overview
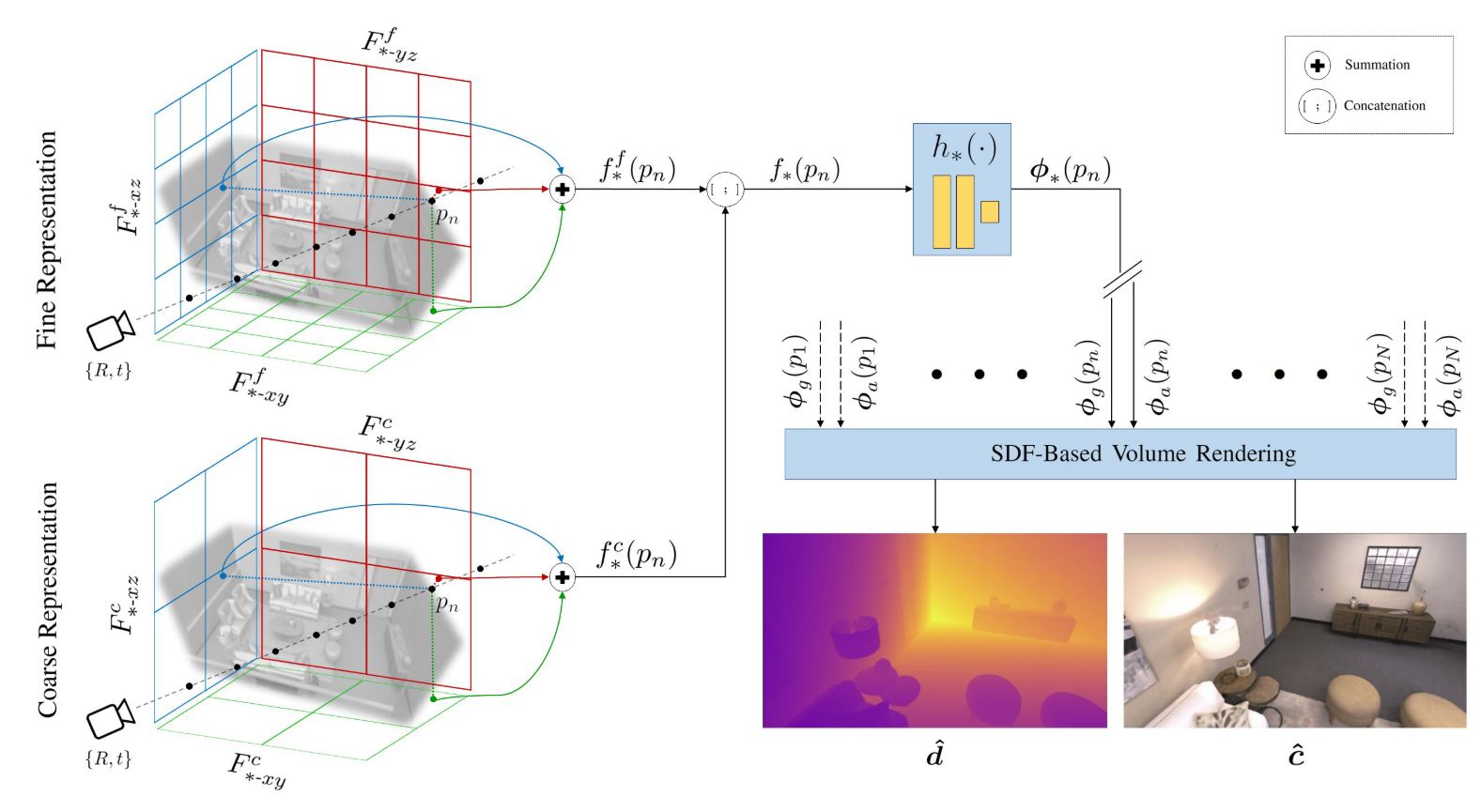
Axis-Aligned Feature Planes
上图左边是他们的Axis-Aligned Feature Planes,他们宣称基于体素网格的NeRF能快速收敛,但是对于更大的场景表示还是有困难的,内存消耗会越来越大。而他们这种三平面结构可以环节这样的问题。他们在垂直轴对齐的平面上存储和优化特征。
feature plane的细节:
coarse to fine
单独的feature plane表示几何和外观。考虑到外观(颜色)是经常变化的,而几何体比较稳定,所以把它们分开表示了。
这样的话,又回到了iMAP的问题了,容易遗忘。
如何进行采样:
对于空间中某一个点,通过双线性插值获取每个特征平面上的特征
对于几何和颜色特征平面,都是:
coarse平面的三个特征向量求和,fine平面的三个特征向量求和
最后,coarse和fine求和的特征向量拼接到一起。
求和是不是太简单了?
通过两层的MLP进行解码,拿到TSDF和颜色
根据上面的说法,我猜测特征平面的初始化会比较重要,也比较难处理,容易导致错误的重建。
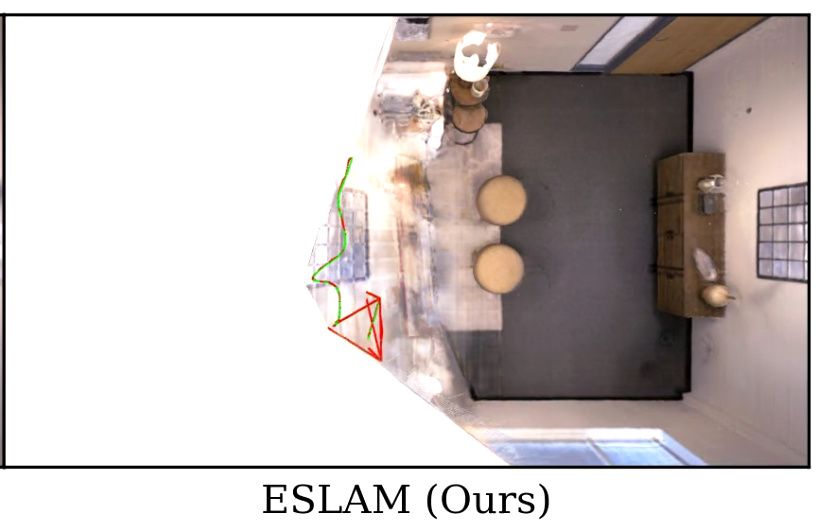
在看E-SLAM运行的过程中,发现他对于相机后没有观测到的的部分,会给重建成相机前观察到的部分,比如展示在replica数据集中重建结果时:
SDF-Based Volume Rendering
与NICE-SLAM几乎一致的流程,不过考虑到了某些像素点不一定有深度信息的情况:
- 采样N_start点
- 对于有深度信息的,深度前后截断距离T内,采样N_imp个
- 对于没有深度信息的,类似iMAP用N_start计算一个权重再采样N_imp个
对于TSDF值,E-SLAM是将其处理成了体密度,再根据体密度去计算权重等等,其他部分和NICE-SLAM没有区别。
在看了co-slam之后再来看E-SLAM,发现E-SLAM在处理TSDF的时候还是太过于保守了。
在E-SLAM中,是先将TSDF值转换成体密度,再根据体渲染的公式去计算权重,这样还是太麻烦了;
而co-slam中,是直接通过sigmoid(tsdf)*sigmoid(-tsdf)拿到权重了。
个人认为,毕竟我们是在做一个隐式神经表示的SLAM,过程都是可学习的,在权重这个部分,保证越接近表面的点权重越大的趋势就行了,其他的都是可以学习到的。
Loss Functions
除了和NICE-SLAM相似的颜色、深度损失外,由于使用了TSDF,可以考虑采样点的损失:
free space loss 鼓励TSDF在free space中具有1的数值,在这个公式中,看起来是鼓励相机中心到物体表面之间被采样的点应当TSDF=1
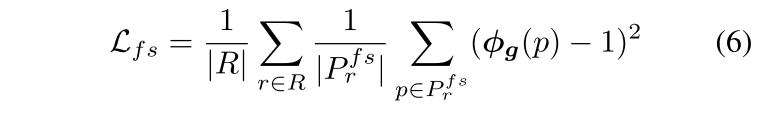
signed distance objective 看起来是希望靠近物体表面的那些被采样的点,能够拥有正确的SDF值。
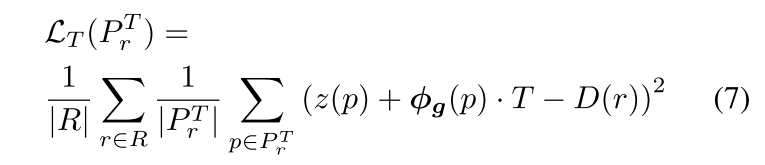
最中心的公式含义为:
采样点沿射线的深度 + tsdf * 截断距离 - 深度真值
根据距离物体表面的远近,E-SLAM把接近物体表面的点分成了两批去计算损失(方便用不同的权重)
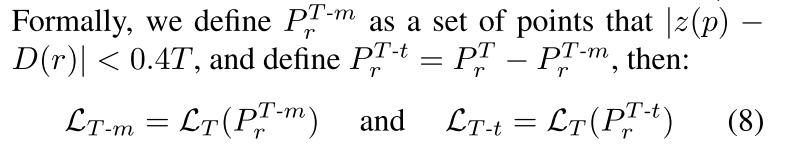
Mapping and Tracking
Mapping和NICE-SLAM差不多,特征平面和MLP都是随机初始化的。
Tracking看起来也没有什么特殊的地方。
Experiments
与NICE-SLAM和iMAP比较,效果确实好一些
Conclusion
这部分提到了E-SLAM接受并处理遗忘问题,以此来换取更小的内存开销。E-SLAM像iMAP一样,更新特征会影响之前重建的几何形状,因此还需要不断地学习之前的关键帧。如果能够更有效地处理遗忘问题,可以进一步加快运行速度。
Supplementary Materials
这里提到E-SLAM使用marching cubes算法获取mesh,并且没有进行任何的后处理。



