3DGS SLAM泛读(一)
GS-SLAM
贡献:
- 第一个3D高斯的稠密RGB-D SLAM方法
- 自适应3D高斯扩展策略,coarse to fine的选择可靠的3D高斯
- 8FPS的速度,平衡效率与精度
Overview:
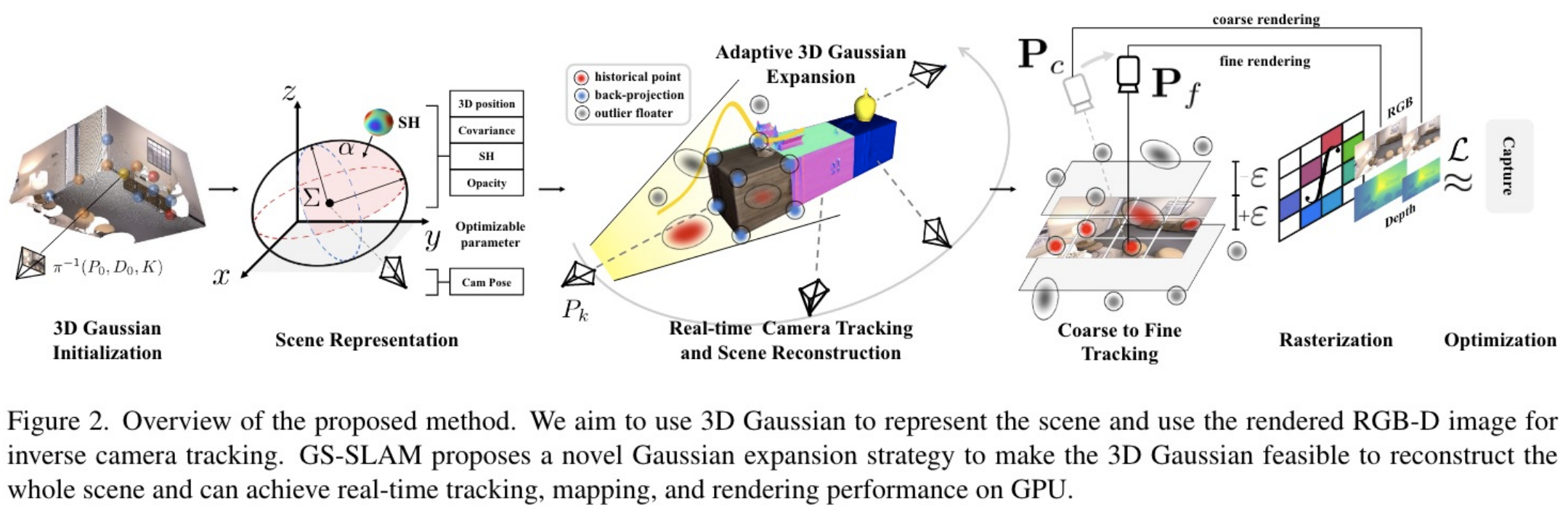
场景表示:
与3dgs一模一样的表示方法

个人观点:
做的比较粗糙,没有特别亮眼的地方,感觉就是按照之前NeRF SLAM的思路,简单的用3DGS又做了一遍。不过可以基于这篇论文,了解一下3DGS SLAM应该是怎么样去做的,这篇论文比较好理解。
实验部分能看到受益于3DGS,渲染做得很好、速度也很快,但是跟踪和建图的精度以及速度却和之前NeRF SLAM的方法却差距不大(甚至不如ESLAM和COSLAM),这里个人感觉是有问题的。
Gaussian-SLAM
贡献:
- 3D高斯表示场景的RGB-D SLAM方法
- 扩展了Gaussian splatting,更好的编码几何形状
- 高斯分布的在线学习策略,将场景分成很多子场景,并且引入了seeding和优化的策略
- 通过最小化光度误差,实现了frame-to-model的tracking,并且和现有的frame-to-frame的方法作了比较
Limitations of Gaussian Splatting for SLAM:
这篇论文讲了Gaussian Splatting运用到SLAM算法中的局限性,个人认为是比较值得参考的。这里讲了几点问题:
Seeding strategy for online SLAM
原始3DGS的自适应密度控制策略是iterative dynamic behavior的,可能会导致mapping的迭代和计算时间发生剧烈的变化,这种方式不适合SLAM。
因为SLAM既要建图又要跟踪吧,如果建图时间过长,或者地图更新太大,会对跟踪造成很不好的影响
Online optimization
对于较长的序列来说,在线优化所有帧太慢了
这个,就好像sfm和slam
Catastrophic forgetting in online optimization
为了避免每个新帧带来地图的线性增长,一种候选的方案是使用当前帧去优化高斯场景表示。但是这种方法会导致之前mapped views严重退化。
这里我不理解,为什么会导致之前优化的结果严重退化?
是因为当前帧和前面的帧有重复的内容,而这个候选的方案只考虑当前帧,优化之后的3D高斯只能和当前帧“合得来”,而和之前的帧就“合不来”了?
Highly randomized solutions
提到了splatting优化的结果高度依赖于高斯的初始化。并且优化过程中,会受到相邻高斯的影响,高斯可能会向不同的方向增长。
3D高斯固有的对称性导致了不影响损失函数(损失不变)的情况下,3D高斯的参数可以被改动,就是说存在不唯一的解,而这种情况是优化过程不希望出现的。
这可能会导致有时候优化了,损失函数没有被改变?
Poor extrapolation capabilities
高斯函数经常不受控制的生长到未观察到的区域。原始3DGS的方法因为良好的视图覆盖,可以约束大多数高斯模型;但是稀疏视图的SLAM中,新视图往往包含由于先前约束不足的高斯模型产生的伪影,这对于model-based tracking影响很致命。
因为存在伪影,使用color或者depth计算的损失都会有一些影响?
Limited geometric accuracy
单目的情况下,3DGS不擅长编码精确的几何形状。
其实根据这里所讲的几个问题,我认为对于3D高斯来说,SLAM似乎是这样的一个问题:稀疏视角(我们可能不会mapping每一帧,每次对于新的观测区域也都可以算是稀疏视角的)、位姿未知(需要tracking每一帧)、在线(数据是一帧一帧来的,不是一次性给到位的)的重建问题
另外,这篇论文是我见过,提出问题最多的论文。
Overview:
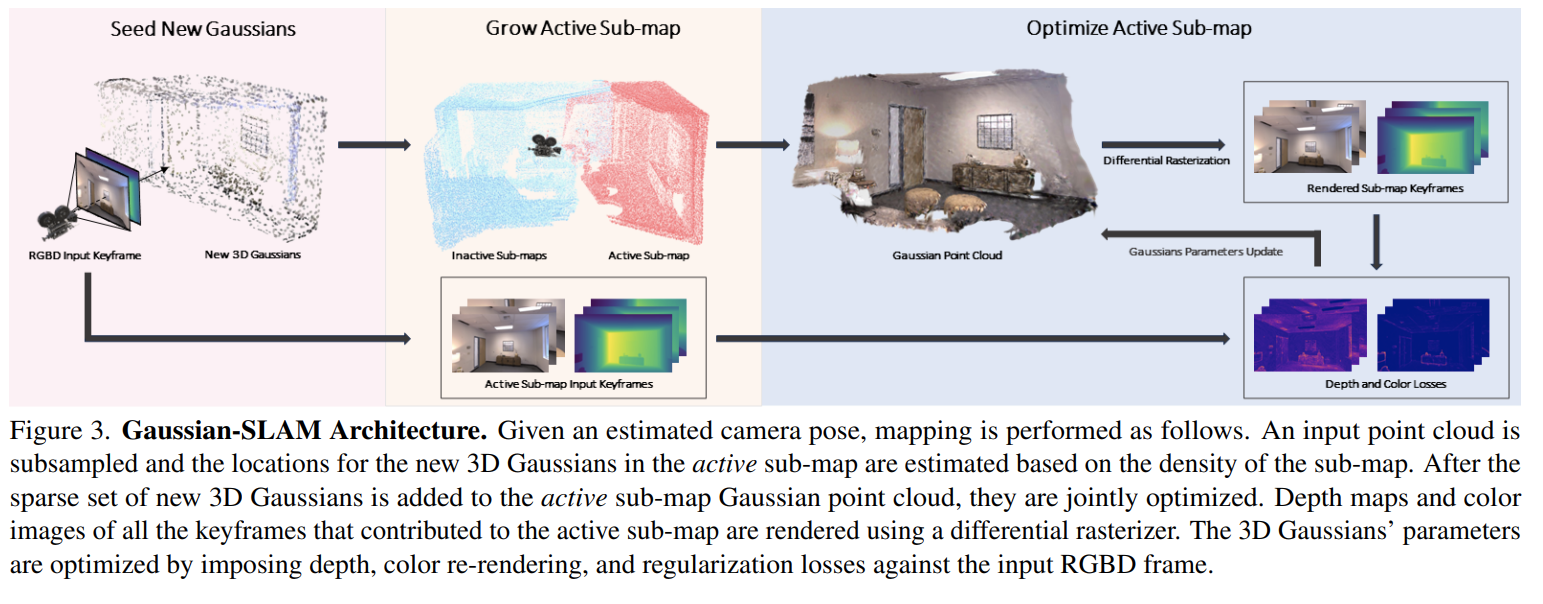
看起来是借鉴了ORB-SLAM3的思路,用sub-map的方式去尝试解决3DGS在SLAM中的一些问题。
场景表示:
看起来也是用的原版的3dgs,没有做什么改动???
实验部分:
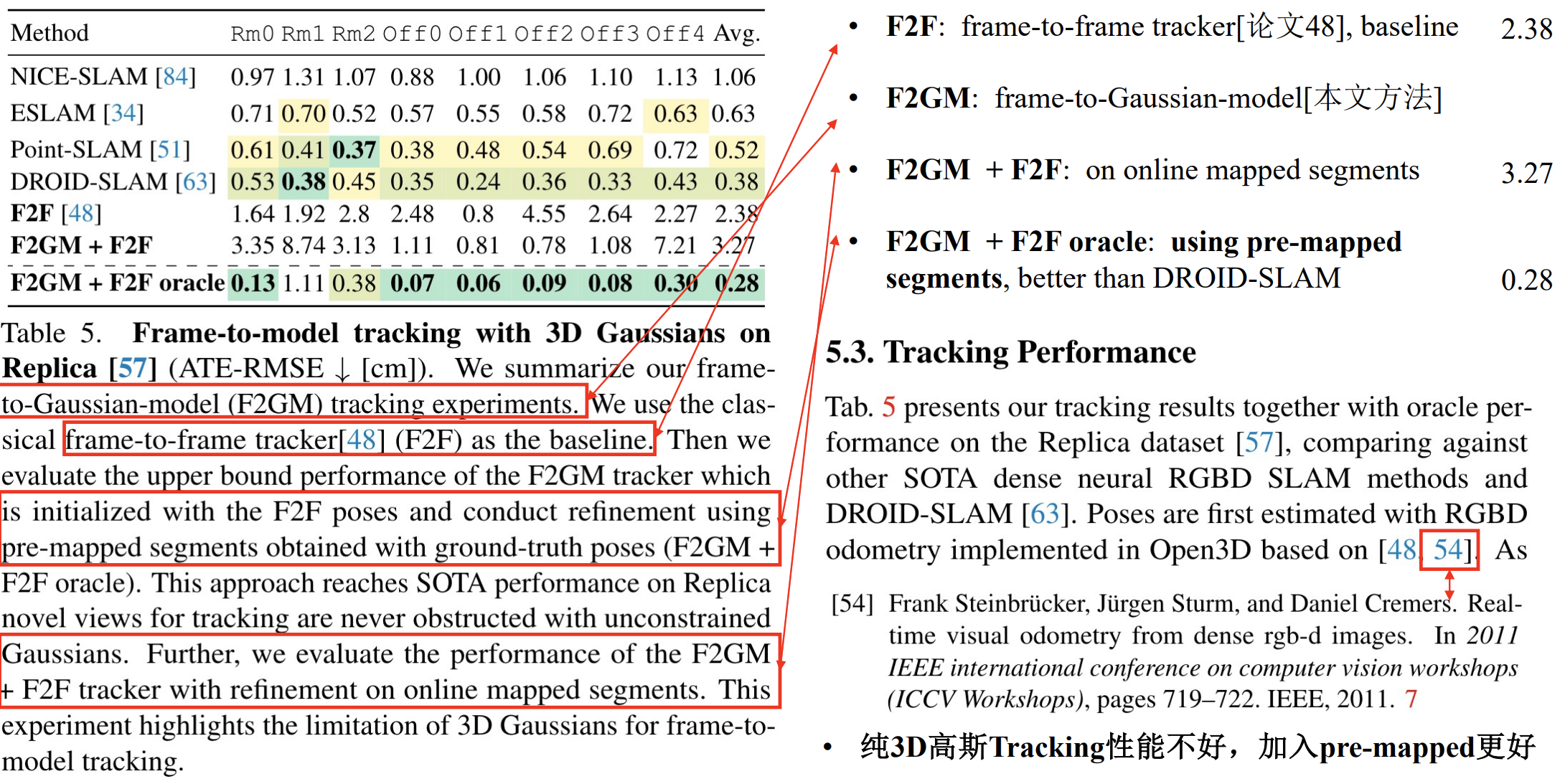
实验部分很有意思,展示了一个比较关键的问题:纯3DGS的tracking性能不好,加入pre-mapped效果会好很多
但是也反映了一个和GS-SLAM一样存在的问题:Rendering的速度很快,但Mapping的速度并不快
个人观点:
对于3DGS应用到SLAM中可能存在的问题,做了一个很好的介绍,很有参考价值。
实验中体现了两个值得关注的问题:
- 纯粹的依靠3DGS的tracking,性能不好,但是加入pre-mapped之后效果会好很多;
- 目前的3DGS SLAM,Rendering速度都很快,但是Mapping和Tracking的速度普遍与之前NeRF-SLAM的方法差距不大。
SplaTAM
贡献:
SplaTAM解决了之前基于辐射场表示的局限性,包括:快速渲染和优化、确定区域先前是否已建图的能力、通过添加更多高斯函数进行结构化地图扩展。
对显示3D Gaussian用于SLAM的优点做了分析:
Fast rendering and rich optimization
能够实时使用dense photometric loss进行SLAM
具有明确空间范围的地图,可以轻松控制现有地图的边界
但是我认为它主要是和用MLP表示场景的方法相比,而feature grid+mlp的方法其实已经可以控制地图的边界了,不过也没有3dgs这么灵活。
显示的地图
目前来看,显示的地图更好编辑和增加容量
到参数的直接梯度流
不太懂这个。。。
SLAM System

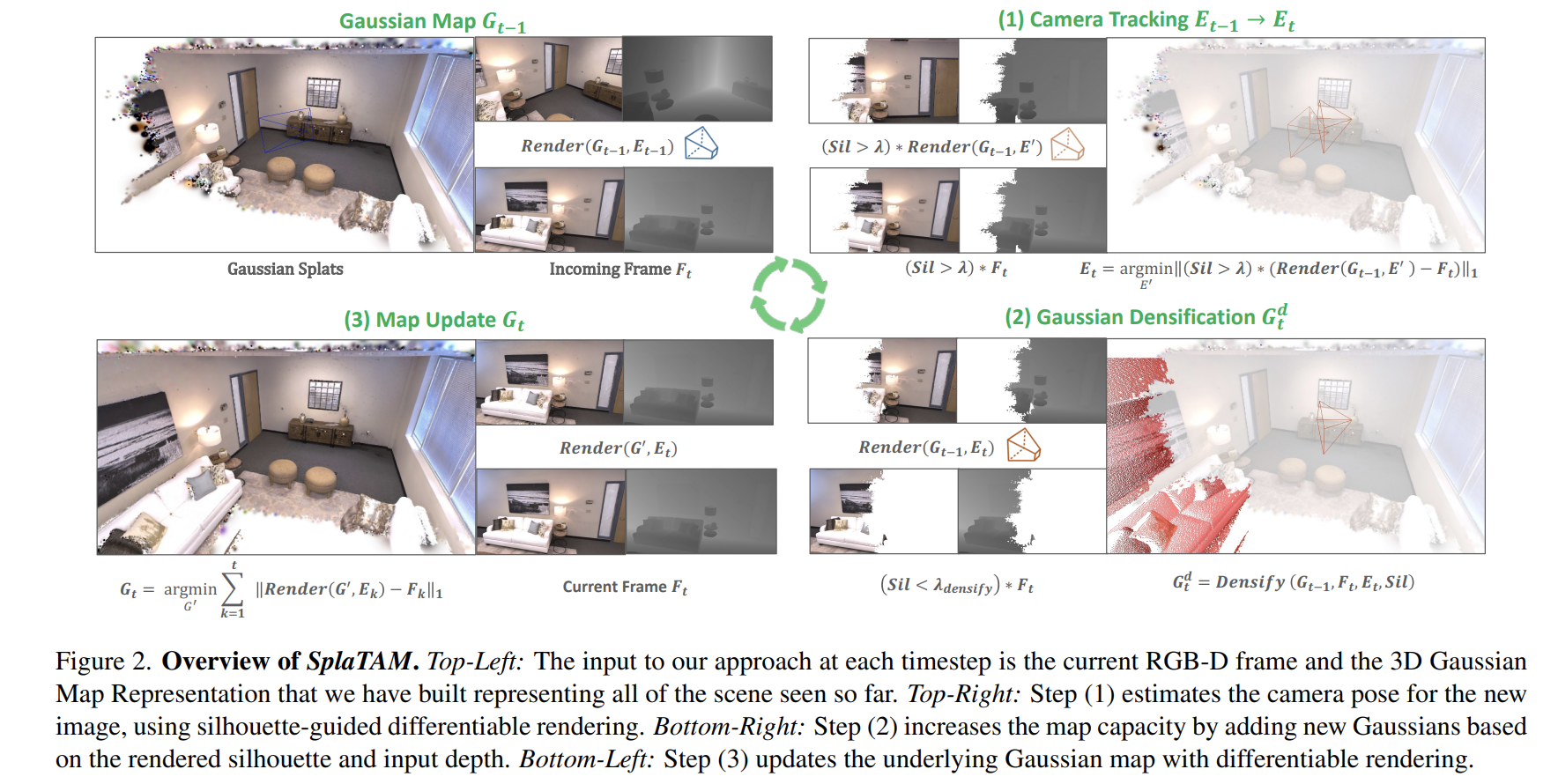
Initialization

Tracking


Gaussian Densification

Gaussian Map Updating

场景表示:
与原始的3dgs相比,使用了与视图无关的颜色,强制高斯分布为各向同性。
与视图无关的颜色指的是没有用球谐函数了???从论文的说法看确实是这样的
每个高斯对应了8个值:颜色R、G、B,中心位置x、y、z,半径r,不透明度o
实验部分:
这里我主要关注耗时,SplaTAM其实并没有在Tracking和Mapping的耗时上彻底优于之前基于NeRF的SLAM方法,只能说在渲染的速率上快了很多。

Limitations and Future Work

个人观点:
感觉不是非常有特色,和其他3dgs slam相比,最大的不同可能只是场景的表示不一样了,放弃了球谐函数,每个3dgs都只有8个参数。有一个博士评价这个工作拼凑感太强。
不过这篇论文是第一个开源的,而且也把工作的流程讲的很清楚,可以拿来好好学习。
Gaussian Splatting SLAM
贡献:

论文提及的一些观点:
- NeRF近期的发展都引入了显示的体积结构,从这些工作中可以推断出:高质量新视图合成的关键不是神经网络,而是可微分体积渲染。以Plenoxels为例,可以避免使用MLP就实现与NeRF相当的渲染质量。
场景表示:
anisotropic(各向异性)的3DGS,但是省略了球谐函数相关的部分

部分公式推导、理解

公式3:回顾《视觉SLAM十四讲》,可以比较简单的推导出来。但是对于这里面表示反对称的符号为什么有两种,个人不太理解。
公式4:我好像对雅可比矩阵等内容非常不熟悉,还需要好好了解一下才能继续写这部分!!!
System Overview
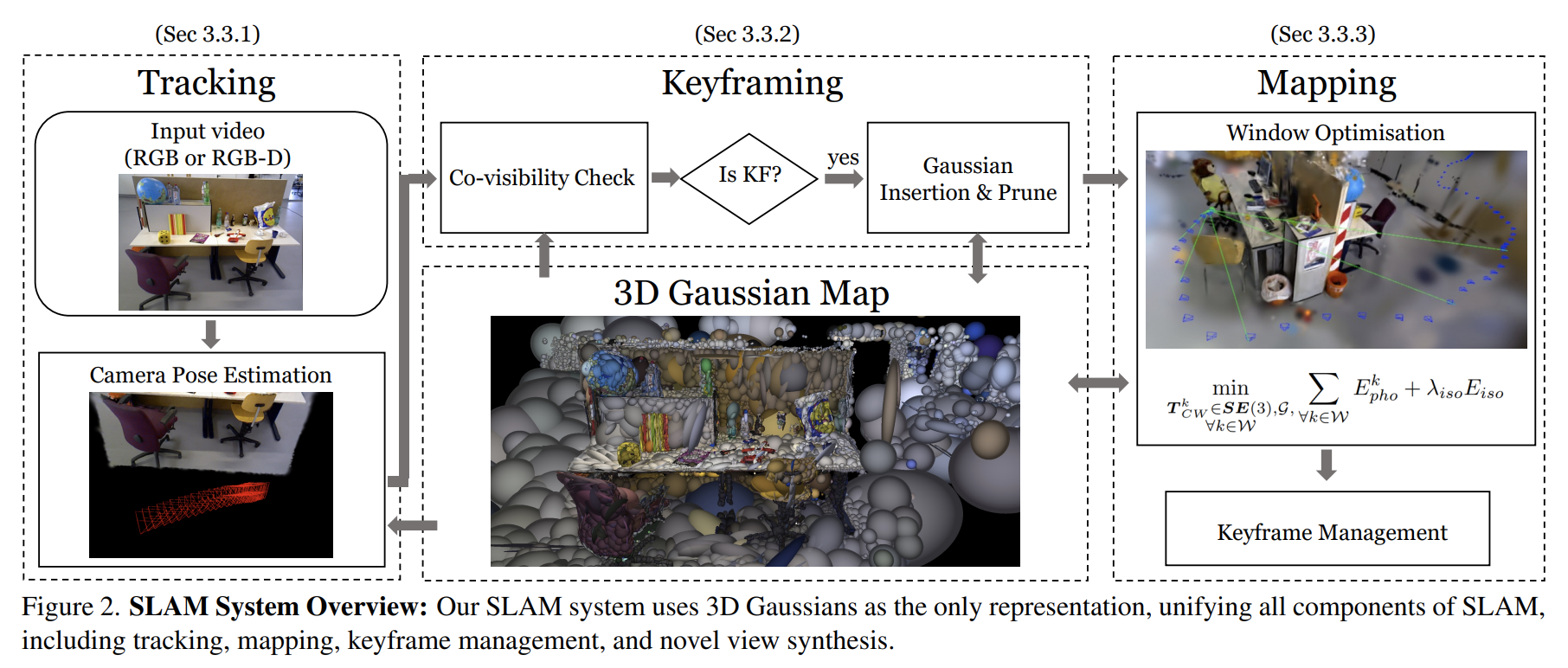
Tracking部分还是老样子的感觉,毕竟无论NeRF SLAM还是3DGS SLAM基本都是用frame-to-model优化位姿,玩不出新花样来。
Keyframing有点传统slam的意思了,通过共视关系选择关键帧,并且使用DSO的方式管理关键帧。同时3DGS也遵循可见性排序,考虑Gaussian Covisibility又进一步简化了关键帧的选择与管理。另外,看起来3DGS场景也只能由keyframe去加入点,同时也会看这些高斯函数是否被其他关键帧看到,没看到就会被修剪掉。
关键帧选择对mono slam来说应该是很重要的,因为只有只有multiple-view observations才能够决定场景的几何结构!
Mapping部分之前的工作我也没好好了解,但是这部分其实才是3dgs slam中最重要的部分。这里详细记录一下:
基于共视关系选择一系列的关键帧,用于优化当前的可见区域;
另外每次迭代优化都随机选择两个过往关键帧,防止遗忘全局地图。
3dgs这种表示为什么会担心遗忘全局地图呢?
最近刚好自己写了一个简单的3dgs slam,一帧进来优化位姿、优化场景,这种的最后也就学出来了一个几何结构,但是颜色、视图很差,我这里用的RGB各16维的球谐系数,不过场景是各向同性的3dgs,我认为是球谐函数被影响的问题。
但是放到这里,mono GS放弃了球谐函数,但是选择了各向异性的3dgs,会不会是各向异性的问题?
引入了一个各向同性正则化,减少伪影,方便SLAM的tracking
为什么不干脆用各向同性的3dgs呢???
实验部分
略,懒得记了,到时候直接看论文!
Photo-SLAM
Motivation:Our proposed Photo-SLAM seeks to recover a concise representation of the observed environment for immersive exploration rather than reconstructing a dense mesh.
贡献:

Overview:
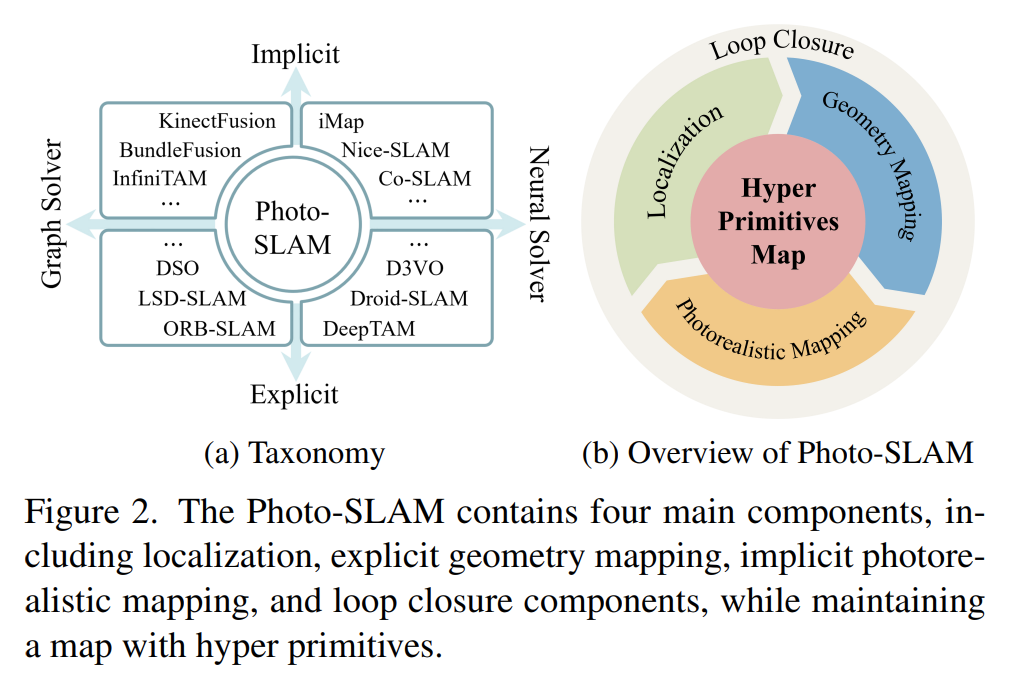
根据论文的描述,photo-SLAM包括:localization、geometry mapping、photorealistic mapping、loop closure,并且每一个组件都有一个单独的线程,而且他们共同维护了一个hyper primitives map。
ORB-SLAM3分为tracking、local mapping、loop and map merging这三个线程
ORB-SLAM2分为tracking、local mapping、loop closing这三个线程
个人感觉photo slam是基于orb slam2或3的工作,在上面加了一个3DGS的photorealistic mapping线程。
Hyper Primitives Map【场景表征】
Hyper Primitives由一系列的点云组成,而这些点云包括了:ORB特征、旋转、缩放、密度、球谐系数
point cloud: 3维
ORB features: 256维
rotation: 3维, SO(3)
scaling: 3维
density: 1维
SH: 16维
个人观点:在原始的3DGS上加入了ORB特征,而3DGS点云的添加来自于ORB-SLAM产生的地图点(ORB特征点),ORB特征用传统方法得到,而其他的都是原汁原味的3DGS
这样做对于传统SLAM方法而言,还是非常自然的,但是photorealistic mapping真的能够实时运行吗?
Localization and Geometry Mapping
作用:实时的位姿估计、稀疏的3D点云,创建所谓的Hyper Primitives
感觉很经典,,,先不仔细看,后面和ORB-SLAM比较一下
Photorealisitc Mapping
作用:负责优化geometry mapping thread线程创建的Hyper Primitives
这部分就放了个损失函数欸
Geometry-based Densification
这部分说为了保证实时性,只生成了稀疏的Hyper Primitives,后面还需要致密化。他们额外设计了一个基于几何结构的致密化方法。
他们做的实验表明:只有不到30%的特征点是active的并且有对应的3D点。而他们认为2D几何特征点的分布表示这些区域有更复杂的纹理,因此需要更多的Hyper Primitives,他们会把inactive的特征点主动创建成额外的临时Hyper Primitives。

这个也不太像是基于几何结构的致密化方法,感觉做的很简单。
不过思路很不错,特征点多的区域确实是纹理复杂的区域,但是如果我想重建场景的话,特征点少的区域、纹理弱的区域也是很重要的,这部分应该怎么去处理呢?
是不是可以特征点多、纹理丰富的区域做一种处理方法,多放小的3DGS点;
在特征点少、纹理弱的区域另外处理,比如放一些大的3DGS点
Gaussian-Pyramid-Based Learning
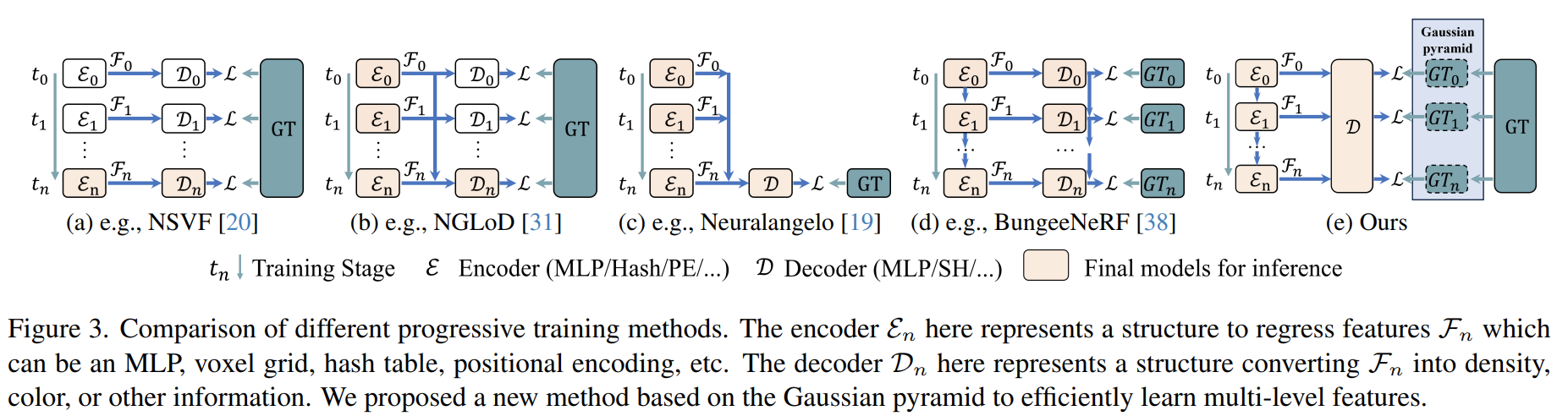
论文在这里介绍了一些Progressive training的方法,比如NSVF、NVGO是训练中逐步增加特征网格的分辨率,较低分辨率的decoder用来初始化较高分辨率的decoder;NGLoD是逐步训练多个MLP做编码器解码器,最后只保留最终的那个解码器;Neuralangelo是在训练过程中只保持一个MLP;BungeeNeRF是用不同模型处理不同分辨率的图像,算是一种显示的方法。
论文提出的方法是基于高斯金字塔的学习方法,分辨率逐渐增加。
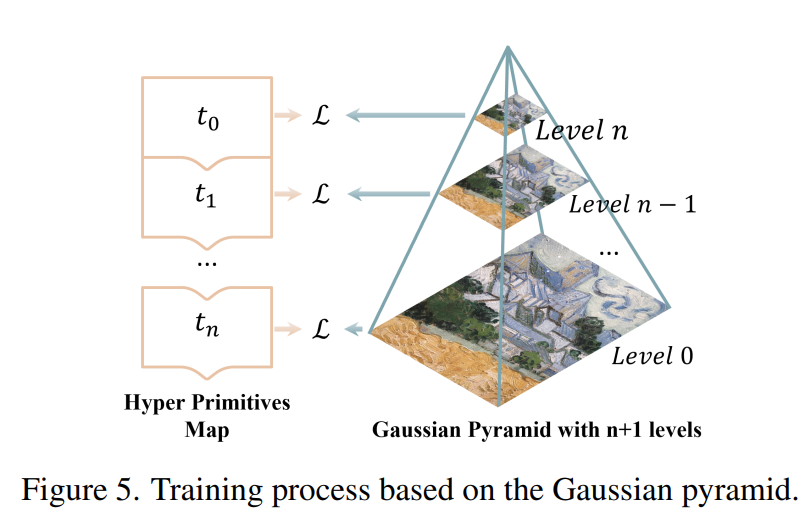
看起来其实也是很好地利用了ORB-SLAM提供的一些东西
Loop Closure
论文这里写的很简洁,个人认为就是套用ORB-SLAM的回环检测。
这里只是提到了检测到闭环之后,通过相似变换矫正关键帧和Hyper Primitives,然后还需要优化来消除一些重影。
实验部分
论文提到Photo-SLAM是用C++和CUDA写的,使用了ORB-SLAM3、3D Gaussian Splatting和LibTorch的框架。
实验部分略过,但是有一个很大的疑惑:既然说了用了英伟达的Jetson平台,为什么没有指明到底用的什么平台?而且看Table 1,这种方法即使在Jetson上也需要4GB的显存,Laptop也是4GB,然后桌面端显存需要6GB。这个Jetson跑的效果也还行,渲染速率也是100fps左右。



