基于神经网络的三维重建
1 对NeRF的思考
NeRF的核心是场景的隐式表示,给定一组影像,网络去学习这个三维场景,然后当指定任意一个位姿的时候,就输出它对应的图片。这其实和传统的SfM的流程是一样的,没什么新鲜的。唯一不同的是SfM构建的是场景的显式表达,而NeRF是通过神经网络进行了表达。现在很多NeRF的宣传都是一张静态图片搭配小幅度移动视角的动图,比如下面这样。

但这样宣传有些误导性。下面简单描述。
1.1 NeRF并非只利用单张影像
第一点,NeRF不是由单张影像得到的。上面这样宣传,很容易让人以为是单张图片得到了可以小幅移动视角的三维场景。这是不对的。如果从单张影像生成三维场景,这就是一个玄学问题了。NeRF并不是只利用单张影像估计三维场景。
我的个人看法是利用单张影像永远也无法恢复出准确的三维场景。这是一个病态问题。就如同单张影像深度估计一样,很多时候都是玄学问题。对于单张影像深度估计,我认为这个问题的核心在于两点:一是这是一个“无中生有”的信息缺失补全问题。如果说可以利用其它模态的数据作为参考,也许是有物理意义的,但仅靠单张图像是站不住脚的。二是深度本身和图像中的纹理、语义等没有明显的关联关系。对于这种没有明显对应关系的两个变量,深度学习能力再强,也很难学到真正有价值的东西。一个简单的例子就是,比如我有一面白墙,拍了一张照片,然后我在墙上挂了一幅山水画,又拍了一张,最后,我关灯了,墙变黑了,我又拍了一张。一共有三张照片。从常识都知道,这三张照片的深度不会有变化(如果考虑画的厚度,反映在深度图上会是一个规则的突出矩形)。但事实上,目前应该鲜有网络能真正准确估计——如果它学到的是和图片位置相关的知识,那么白墙从上到下的深度就不同;如果它学到的是灰度相关的知识,那么它估计的白墙和黑墙的深度就不同;如果它学到的是纹理的知识,那么在山水画上,它就会估计出不同的深度(但显然它只是一幅画而已,我们作为人是不会把它真的有深度的)。
当然你可能会反驳我,那现在有些单张影像深度估计做的很好的工作啊?难道没有意义吗?我的回答是,在某些特定场景下可能有意义。比如某个深度估计网络,它利用KITTI数据进行训练。由于KITTI数据都是采用同一套传感器在相似场景下拍摄的,它拍摄的所有影像都有相似的内容和深度分布,比如靠近图像下方的都是路面,图像上方中间的一般为天空等。深度网络确实可能学到这些与位置有关的信息(天空纹理较少、路面纹理较多、天空比路面深度更深等),进而给出深度估计。那么当输入一个和KITTI类似的影像的时候,它也可以估计出一个还不错的深度图。但是如果换了一个配置,比如输入EuRoC的数据,尽管它本身的内容、深度分布和KITTI相差很大,但网络还是按照KITTI的那一套估计深度,结果就显而易见了,所以泛化性较差。因此,在我看来这种数据驱动的方法还是没能从根本上解决这个问题,难以给出令人信服的解释。场景的几何结构是其固有属性,与外界的观测无关,不管你怎么观测,它都不会改变。但深度估计的网络恰恰就是依靠这种不可靠的“观测”学到的。利用缺失的信息是没有办法真正恢复三维场景的,至少说很困难。
1.2 NeRF并非只能合成特定视角影像
第二点,NeRF是三维场景的隐式表达,也就是说其包含了完整的三维场景。基于训练好的NeRF,我们有能力合成该场景任意视角的影像,比如360旋转的视角,而非仅仅只是可以小幅度移动视角的模型。所以,个人觉得最正确的NeRF表现形式应该是一堆图片+360旋转视角的动图。
1.3 没有图片位姿可以训练NeRF吗
对于一堆原本没有位姿的图片,可以训练NeRF吗?答案是否定的。NeRF的输入必须是影像+位姿。但是,我们可以“曲线救国”——我们可以先用COLMAP等传统的SfM软件对场景进行重建,重建好以后,当然就可以获得每张图片的位姿。事实上,不一定需要COLMAP,只要能输出影像间的相对位姿都可以,所以对于序列影像我们甚至可以拿SLAM来获得位姿。我们拿着这些位姿,配上图像,就可以输入NeRF进行训练了。
1.4 NeRF不能无中生有
NeRF还有一个值得注意的地方,就是NeRF作为某个特定场景的隐式表达,我们就可以把它理解为是一个三维模型。所以说,它只能合成出这个场景的不同视角影像,没有办法合成出新的场景的影像。另外,如果拿一张其它场景的影像,它也没有办法去匹配找到正确的位姿(因为就完全不在这个三维模型里)。
1.5 NeRF的应用场景
除了上面提到的合成新视角影像、辅助计算机视觉任务等,从某种程度上来说,NeRF可以用于逆向工程。对于一个没有精确三维模型的零部件,我们拍一堆图像(已知位姿),然后训练一个场景表示,最终把这个场景表示导出成三维模型。当然你可能会问,如果说你都拍了一堆图像(已知位姿),为什么不用传统的视觉方法重建场景呢?这就是一个典型的SfM问题啊。关于这个问题我也没有答案。是不是NeRF建出的模型更稠密、精度更高呢?
传统的方法重建场景还是比较麻烦的,我理解的狭义的sfm还只是到了稀疏点云的那一步,后续还有稠密重建、点云融合、网格重建、网格优化、纹理贴图这些MVS的步骤才能有一个实质的模型。
感觉NeRF从效果上讲应该是和后面的MVS作对比,因为他的输入就是稀疏重建的输出(图像位姿和稀疏点云,有些nerf网络好像需要点云这个输入),从方法上来说NeRF更一步到位,从稠密度来说,NeRF更加稠密。
1.6 NeRF与SLAM的结合
NeRF与SLAM从某些角度上来看具有一定的相似性。可能在地图存储、位姿估计方面有一定的结合点。比如现在的SLAM地图都是显式的存储三维点云,但如果可以用NeRF隐式地存储,也许会有一些新的应用。
2 Multi-view Reconstruction with SDF
2.1 什么是SDF
有向距离场的定义如下

简单来说就是,对于空间中的点,计算它距离最近表面的距离。如果在表面内就为负,表面外就为正。需要注意的是SDF它是一种思路与方法,它不仅仅可以用于场景的三维表示,还可以用于字体渲染等领域。

在SDF领域,有个DeepSDF的工作,如上图所示。其主要内容就是通过深度网络来给出空间中某个点的SDF的值。NeRF的网络结构设计在一定程度上就是受这个网络的启发。
2.2 如何用SDF建模

上面,我们介绍了什么是SDF,那么如何用SDF来进行重建呢?不妨先回忆一下NeRF的训练过程。我们得到一个密度场和一个颜色场,然后利用渲染方程,得到合成的图像,并将其与真值做Loss,不断迭代,减小误差。这是比较容易理解的。但前面也说了,基于密度场的重建效果是比较差的。进一步,我们能不能把NeRF流程里的密度场替换成SDF场呢?如果可以的话,那么我们就可以基于SDF得到质量较高的三维模型了。这样想法没错。但是如果真的这样替换的话又会有新的问题。直观来说,NeRF输出的2D影像就是基于密度和颜色渲染出来的。你现在直接把密度场给丢掉了,还怎么渲染影像呢?能不能把积分公式中的密度换成SDF呢?不行,因为NeRF中对密度进行积分是有物理意义的。所以这个问题的核心是,我们如何找到一种转换,把SDF转换成NeRF中的密度。如果可以的话,就可以继续使用NeRF的框架,并且还可以得到SDF。一个可用的工作就是NeuS,将密度场和有向距离场联系起来,如上图所示。

首先,我们可以模仿一下渲染方程里的密度函数σ,我们也找一个概率密度函数把SDF表示起来。在论文中,作者选用了一个Logistic的分布函数,它是Sigmoid函数的导数。事实上,我们可以选择不同的概率密度函数,只要它是单峰的、且以0为中心就可以了。进一步,对于体积渲染方程,我们可以简化成上图中最下面公式的样子。把T(t)和σ(r(t))变成一个权重w(t)。这样的意义就是,我们把某个像素最终的渲染结果看做是由某条光线上所有采样点的颜色加权求和得到(这里我们把密度作为权重的一部分了)。进一步我们思考这个权重应该具备什么性质?至少有两个:第一是无偏的。无偏是指在最合适的地方有最合适的值。举个例子,某条光线穿过一个表面。那么这个像素的颜色应该由在这个表面的那一点的颜色决定,权重最高。但如果还没到表面点的时候,权重就很大了,这显然就是不合适的。第二是可以反应遮挡的。举个例子,空间中有一个球体,一条光线穿过它,显然会有两个点(入射点和出射点)。从SDF而言,这两个点的SDF值都为0。但从渲染的角度,显然是里我们最近的那个点应该具有最大的权重,而不是远处的那个点,或者两个点等权。

基于上面提到的两点,我们寻找最优的权重的表示,如上图所示。一个简单的想法是,我们把SDF外面套一个Logistic分布,就可以得到新的σ(t)。然后以此组成新的权重w(t)。这样其实得到的是有偏的权重,如右图左边部分所示。蓝色表示SDF函数,在物体表面时,SDF=0。由于我们选用的又是Logistic分布,所以概率密度应该如红色曲线所示。看起来还不错。但如果我们把这个σ(t)函数积分出来,就会发现这个权重在还没有到达表面的时候就已经到达了峰值。这显然就是有偏的。所以在NeuS工作中,首先将Logistic积到了Sigmoid函数,然后利用它作为权重。如上图中右边所示。可以看到,当在物体表面的时候,w(t)有最大值,也就是最大权重,这是一个无偏的表示。进一步,可以对比NeRF和NeuS的渲染方程如下。

NeuS采用的Loss如下。

此外,上图中可以看到NeuS和NeRF的对比。NeuS比NeRF更加光滑、干净的三维结果。事实上,上面说的这些,核心的思路还是寻找密度和SDF之间的关联,找到这种关联以后,就可以把SDF应用到NeRF的框架中去。所以,NeuS是一种办法,当然也会有其它办法,如下图所示。

比如VolSDF利用拉普拉斯分布表示密度和SDF之间的变换。Unisurf则是采用Occupancy Field,而不是SDF。此外,除了关注前景,我们还可以同时关注背景,这方面的工作是NeRF++。通过将前景放到圆里,背景放到圆外,分别训练两个模型来分别合成。
3 场景三维重建
3.1 传统COLMAP
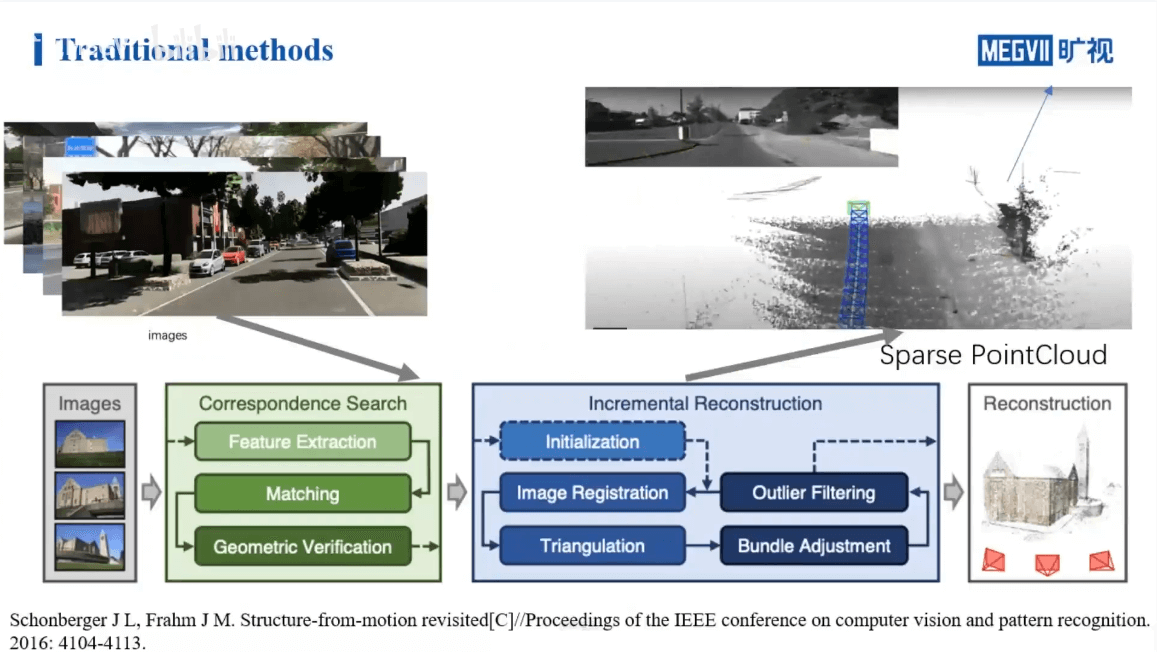
如上图所示,展示了COLMAP进行三维场景重建的步骤。简单来说就是首先对输入的影像进行特征提取与匹配等操作,找到对应关系,得到相机的位姿。然后在此基础上进行增量式重建。当然这个过程不可避免地会引入一些误差,所以会用BA等进行优化。上面提到的是用COLMAP进行三维重建的流程。如果用NeRF进行三维重建,应该有什么样的流程呢?
3.2 NeRF
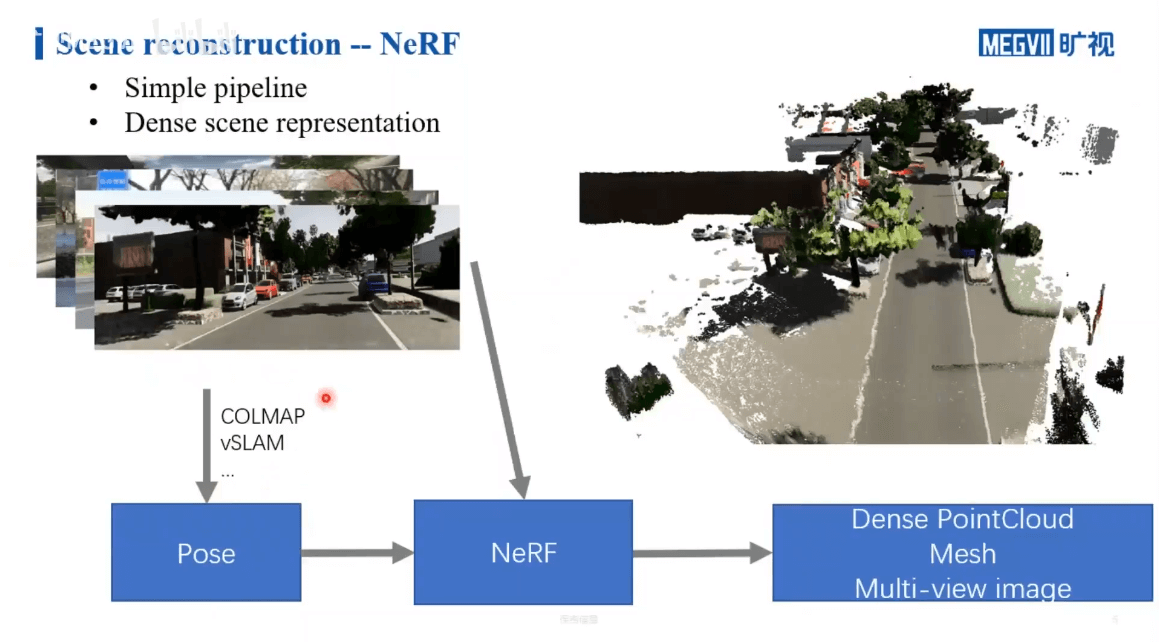
利用NeRF进行三维重建,首先要有一堆拍摄的影像。然后我们还要有对应的每一张影像的位姿。这个位姿可以是通过SfM的方法获得,也可以通过SLAM获得,或者说外部直接测量提供都可以。然后将影像+位姿输入NeRF进行训练。训练好以后,给定一个位置和视角,网络就可以给出密度场和颜色场,基于此就可以渲染出合成视角影像。那么相比于传统COLMAP,NeRF有什么优劣呢?主要体现在两个方面:第一,NeRF的重建结果相比于COLMAP而言是更加稠密的;第二,根据上面的介绍也可以看出,NeRF相比于传统方法,流程会更加简单。一句话概括就是:用更简单的流程获得了更稠密的重建。
4 场景重建中的挑战
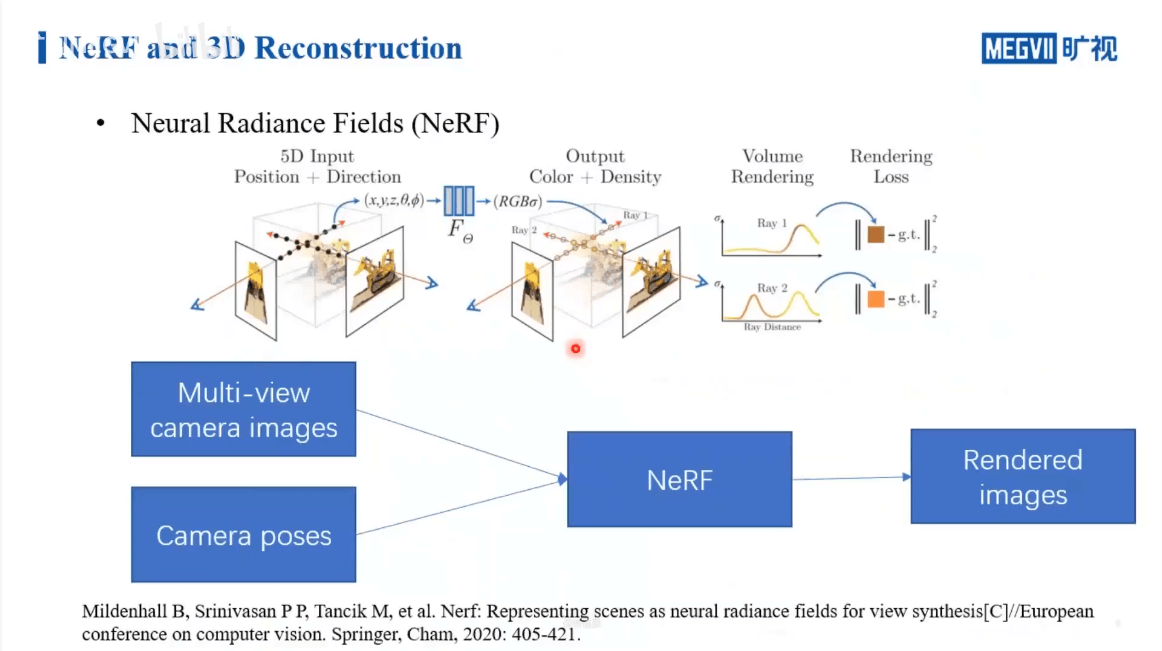
毫无疑问,NeRF跟传统重建技术的区别主要还是在于NeRF可以隐式地学习体素的表示。通过带有位姿的多视影像,NeRF可以学习到场景的表达,最终合成新视角影像。进一步,我们分析各个步骤,如下。
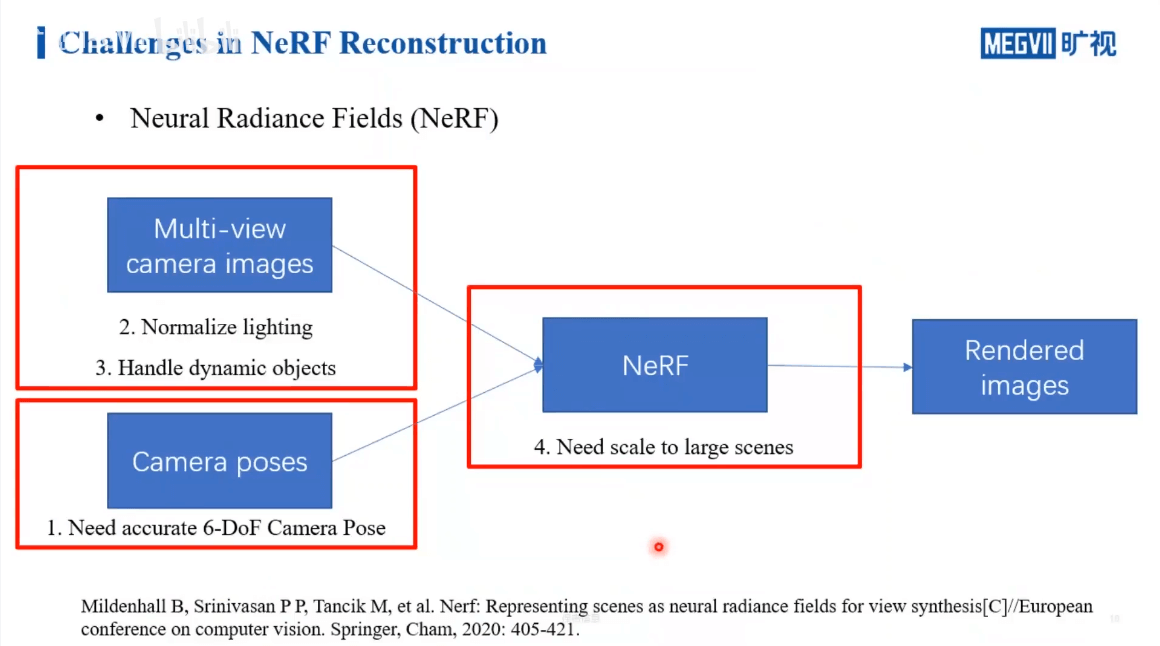
首先,我们的网络在训练阶段对于输入是有一定要求的。首先是相机位姿,我们需要输入的相机位姿是非常准确的,不然训练的网络效果不会很好。另外一个输入是多视影像,我们自然希望是要有稳定、统一的光照。不然就如同RGB-D SLAM一样,建出的图颜色不均匀。第二个是自然希望场景中没有运动物体,不然这种不统一的运动会给位姿估计带来影响。最后,可能出现真实的大场景,如何平衡性能,进行优化也是值得思考的问题。所以之后的内容主要围绕输入影像、输入位姿以及大场景这三个方面介绍。
5 Neural Approach to Scene Reconstruction
5.1 位姿优化

前面说了,NeRF的输入之一是相机的位姿,除了物理意义上通过外部测量直接获得位姿真值,我们也可以通过各种手段去算位姿:
- 第一种方法是,我们可以用各种标定板,如Chessboard、AprilTag、ArUco board等,通过特殊的算法,就可以求得相机相对于标定板的位姿;
- 第二种方法是使用各种SLAM方法进行位姿估计;
- 第三种方法是使用SfM方法,如COLMAP等;
- 第四种方法是基于NeRF,比如之前提到的iNeRF工作,通过给定一个影像,得到该影像相对于场景的相对位姿。
这四种方法各有千秋:
- 对于基于标定板的方法,显然只适合于小场景,对于室外等大场景就比较无能为力;
- 对于SLAM方法,其本身没有场景大小的限制。但是由于其更关注于实时性,在一定程度上牺牲了一定的精度,导致其估计的位姿相比于SfM方法精度要差一些。
- 对于SfM方法,相比于SLAM方法则是相反,其更关注于精度,但是运行效率会差一些,更加耗时,只能离线处理。
因此,我们也就进一步回答了之前“没有图片位姿可以训练NeRF吗”。但显然的,除非是非常高精度设备测量的位姿,否则算出来的位姿或多或少都会有点噪声或者说不准确。所以我们就想,能不能让网络有一定的噪声容忍能力,所以BARF就出现了,来自于CMU,如下:
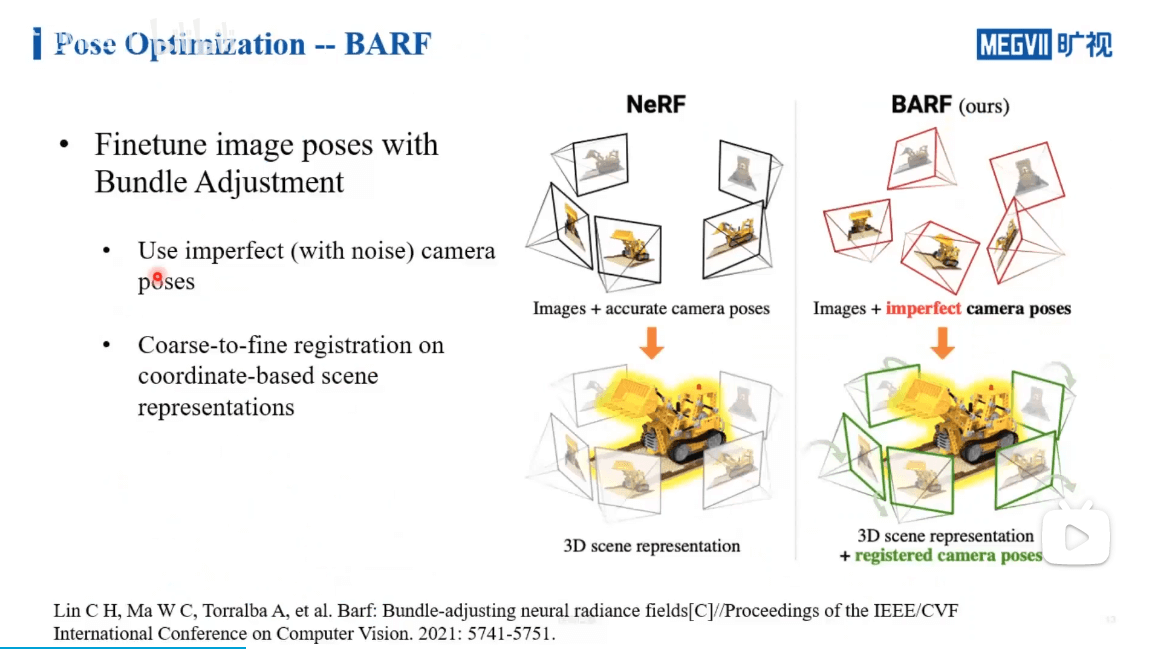
在这个工作中,作者利用传统SLAM中的BA方法优化影像位姿,如上图所示。一般NeRF需要精确的位姿,但是BARF输入的位姿可以是有误差的,通过他们的方法可以调整这种误差,最终得到和NeRF相同的效果。
一些基本的三维重建坐标系介绍如下,此处不再赘述
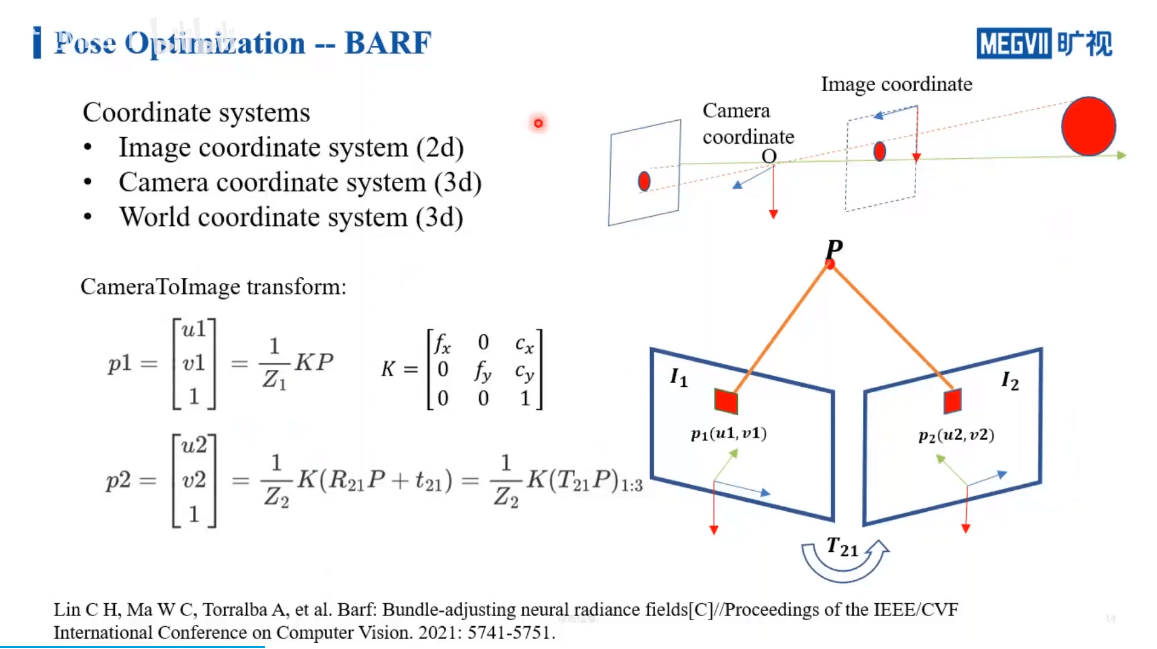
在BARF中是怎么做呢?如下图所示。
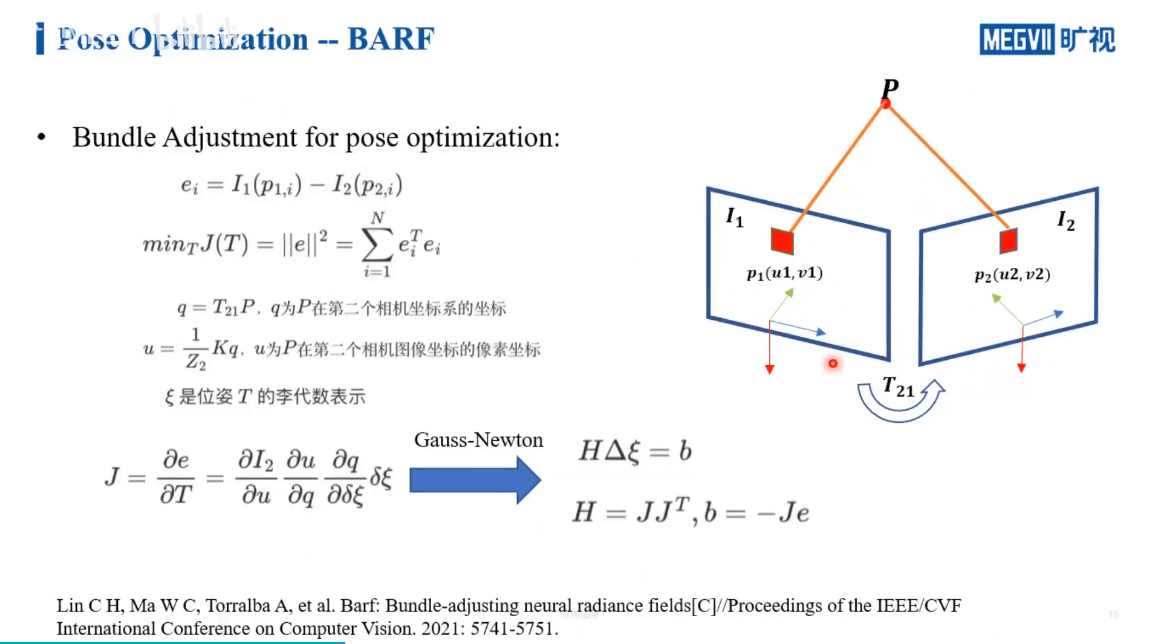
我们做一个帧间BA,使得重投影误差最小。当然学过SLAM的应该知道,这一块理论推导还是挺难的,如果从实际应用的角度,可能会简单一些,因为很多东西已经写好了,我们只需要拿来用就可以了,如下。
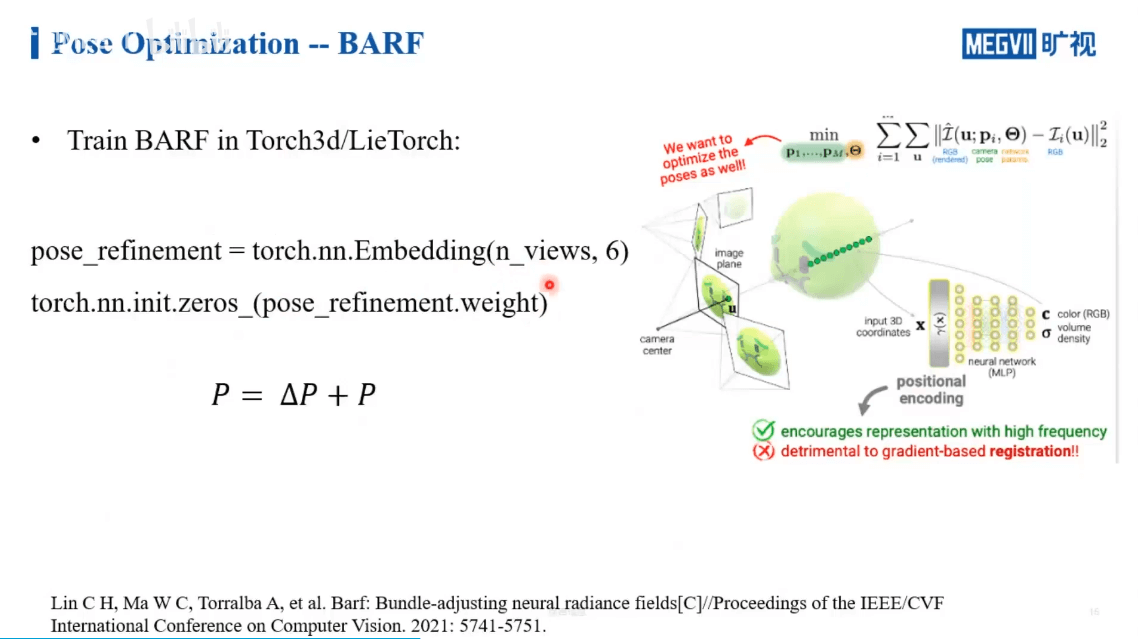
但还有个问题,那就是我们前面提到过的NeRF中的positional encoding。我们利用这种手段使得网络有能力感知到影像中的低频和高频信息,而不是简单的x、y、z坐标。但这确实会给位姿优化带来困难。

我们如果对positional encoding求导,就会得到左下角的式子,可以看到有个比例系数。而且这个系数与层级有关,层级越高,代表频率越高,但是权重越大。这样的结果就是对于高频和低频的信息表达是不均衡的,网络更容易学到一些高频的部分。
因此,BARF提供了一种新的机制,如下。

可以看到,BARF采用了退火机制。本质上来说就是对positional encoding增加了一个权重。简单来说就是,在网络刚开始训练的时候,只开放了低频的响应,而随着训练次数的增加,逐渐开放高频部分。这也是一种由粗到细的策略,可以保证网络在一开始的时候就不会学到什么奇奇怪怪的东西。
下图是BARF的效果展示。

可以看到,加了BARF以后,场景的细节恢复地非常好。然后,另一个工作iNeRF,如下所示。

在有了一个训练好的NeRF以后,我们可以实现基于影像的定位。
5.2 影像优化
在处理完了位姿不准的问题以后,另一个问题就是要对图像进行优化,如上面描述,又主要分为光照变化和动态物体两个方面,下面分别介绍。
5.2.1 光照变化

这个问题的核心在于,我们输入NeRF的影像自然是希望每张影像光照都比较均匀,变化较小。这在光照条件控制较好的室内或者小场景中还比较容易,但是对于室外等大场景几乎是不可能的。如何对这些不均匀的光照进行优化,是这部分要讨论的问题。

一种解决策略是在RGB域建模,通过设置某个可调整的参数,使得网络具备调整影像的能力。另一种是在第一种的基础上更进一步,把ISP处理pipeline中的步骤同样进行建模,让网络学习。最后一种是直接对传感器直出的RAW数据进行训练,得到NeRF。
这方面的第一个工作是NeRF in the Wild,如下。
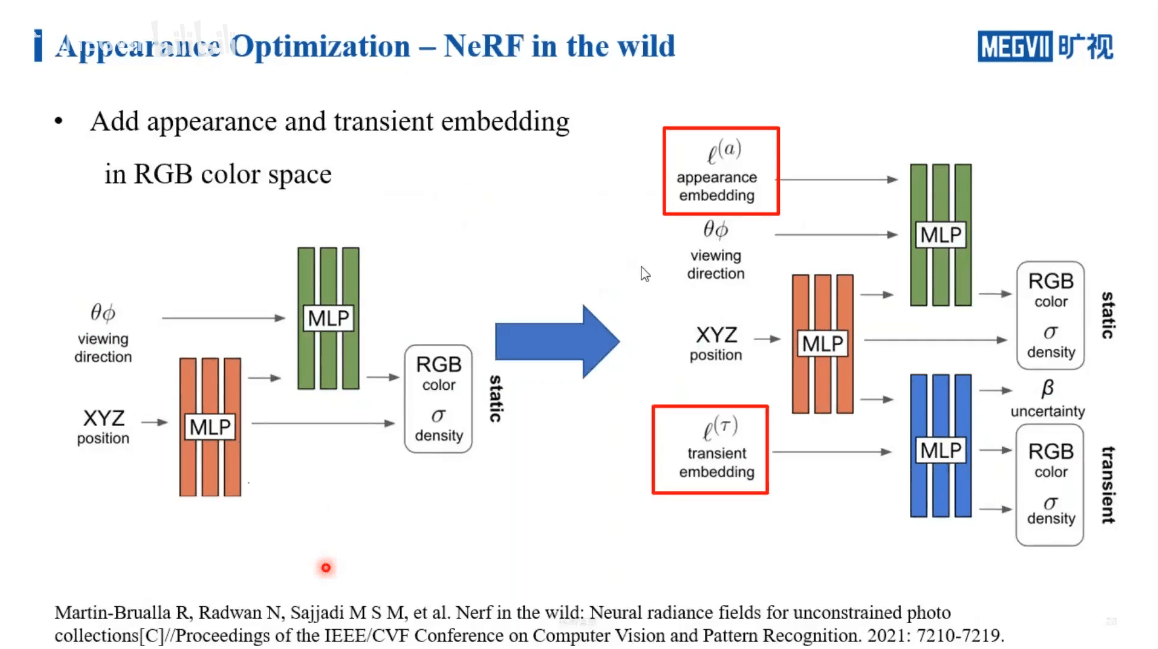
左侧为原始NeRF的流程。右侧作者增加了appearance embedding和transient embedding这两个变量来学习颜色的变化。结果如下。

进一步,我们如果考虑ISP处理的一些步骤,也可以对其进行建模。这是ADOP的工作,如下。
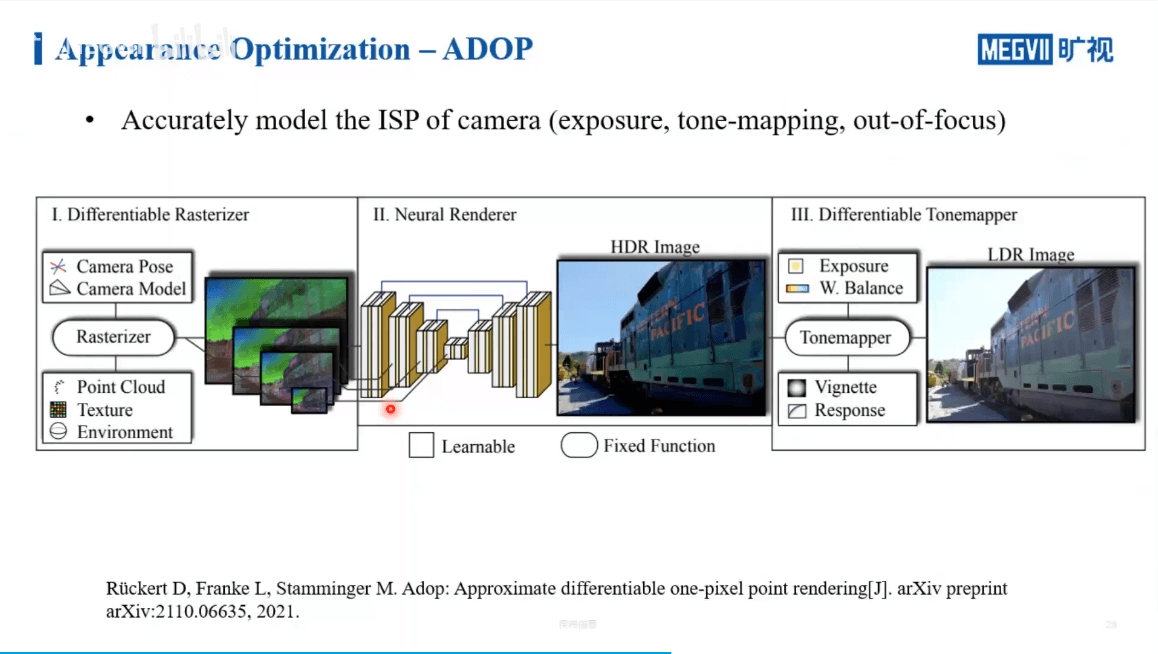
可以看到,网络有能力学习到场景的一些本征的颜色。比如黄色的沙发因为逆光在真实影像中偏暗,但是在合成的影像中,就被恢复的比较好了。

最后一种思路是在Raw数据上做NeRF,这是NeRF in the dark的工作,如下。

其实想法也比较简单。常规的NeRF拿到的影像是经过ISP处理以后的影像,这种处理引入了各种非线性变换,那么网络去拟合这种变换其实是比较困难的事情。另外,在处理的过程中,也会压缩位宽,导致一些信息损失。所以作者就直接在RAW数据上训练NeRF。
5.2.2 动态物体
在处理了光照不均衡的情况以后,影像相关的另一个挑战就是动态物体。

解决这个问题一般来说有两种做法,如下。
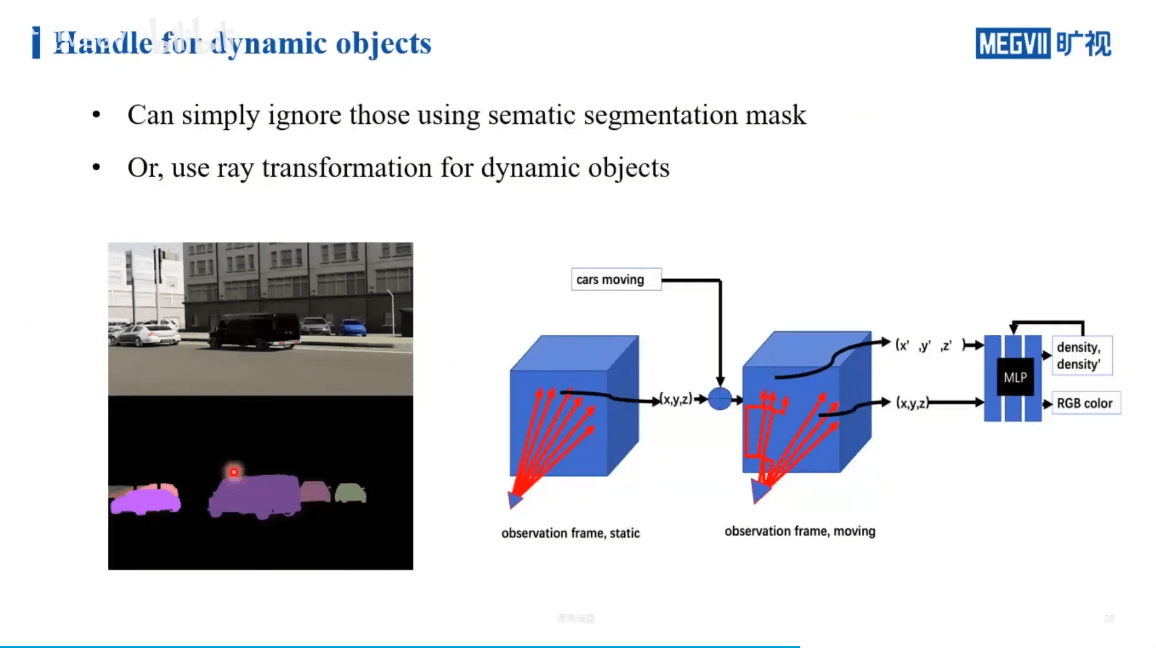
一个简单的想法就是,利用语义信息识别出一些可能运动的物体,然后把它们忽略掉(上图左边)。但这样有个潜在的问题,如果被擦除的物体在其它视角下也没见过,那么就会产生空洞。另一种办法就是,真正的对动态物体的重建完成,具体可以通过光线变换来重建动态物体(上图右边)。
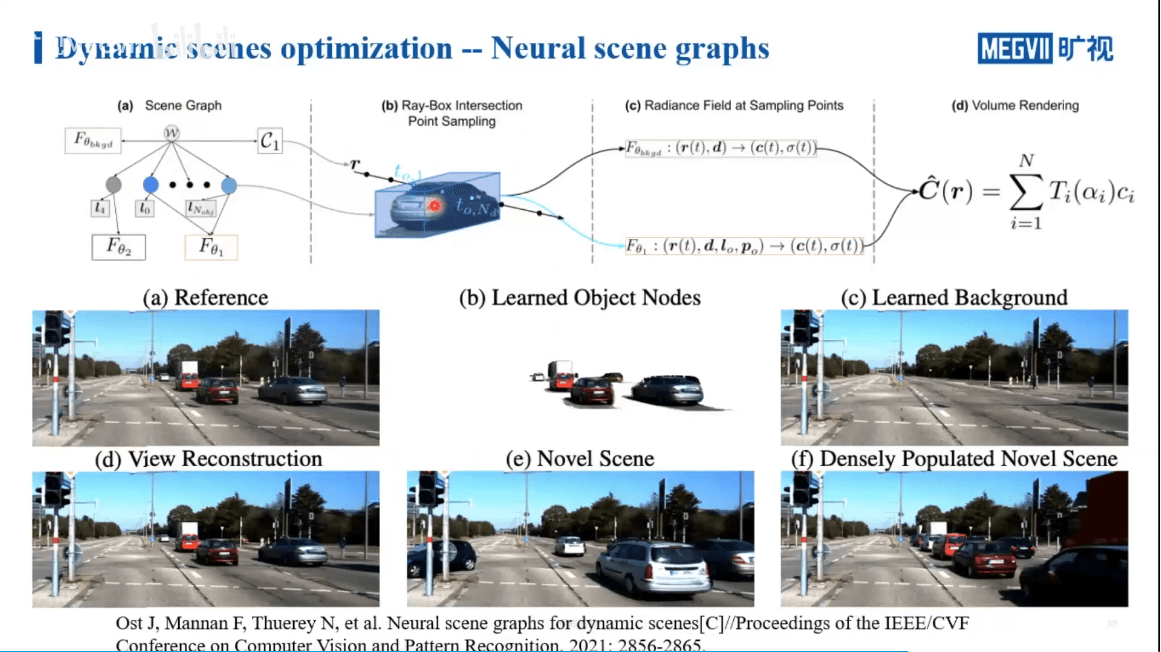
一个工作Neural Scene Graphs就是这样一个工作,如下图所示。
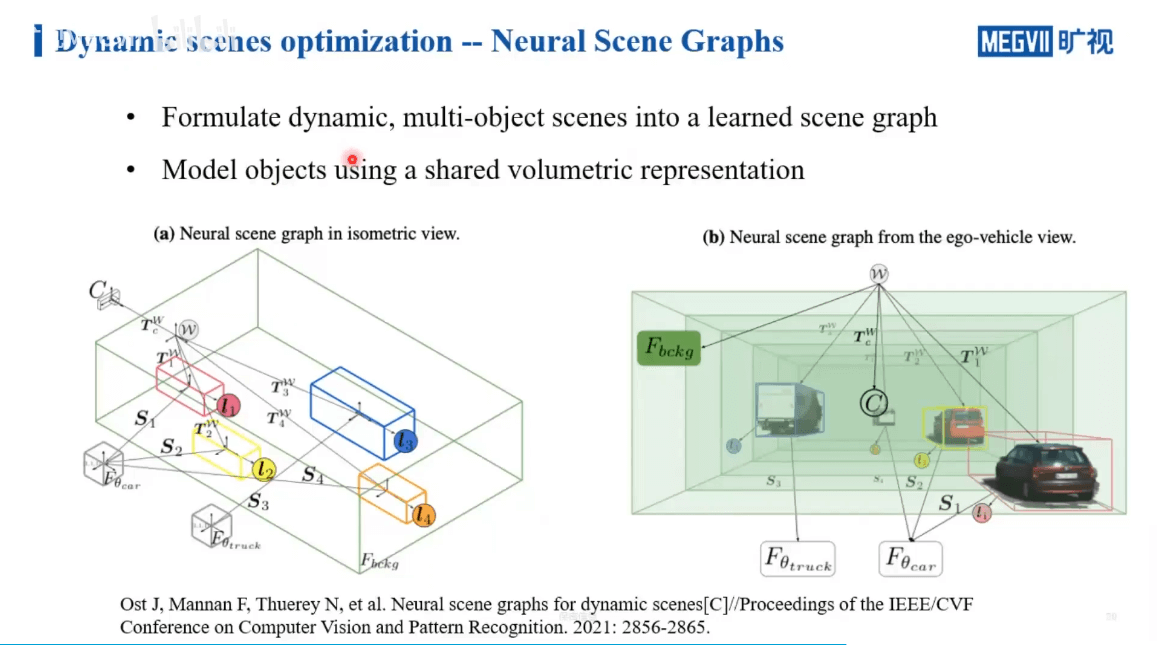
作者通过场景图将场景和运动目标分割开,如上图所示。各个节点之间的关系是通过相对变换得到的。在训练过程中,背景单独用NeRF训练。而对于前景目标,有两种不同的做法,如下图所示。
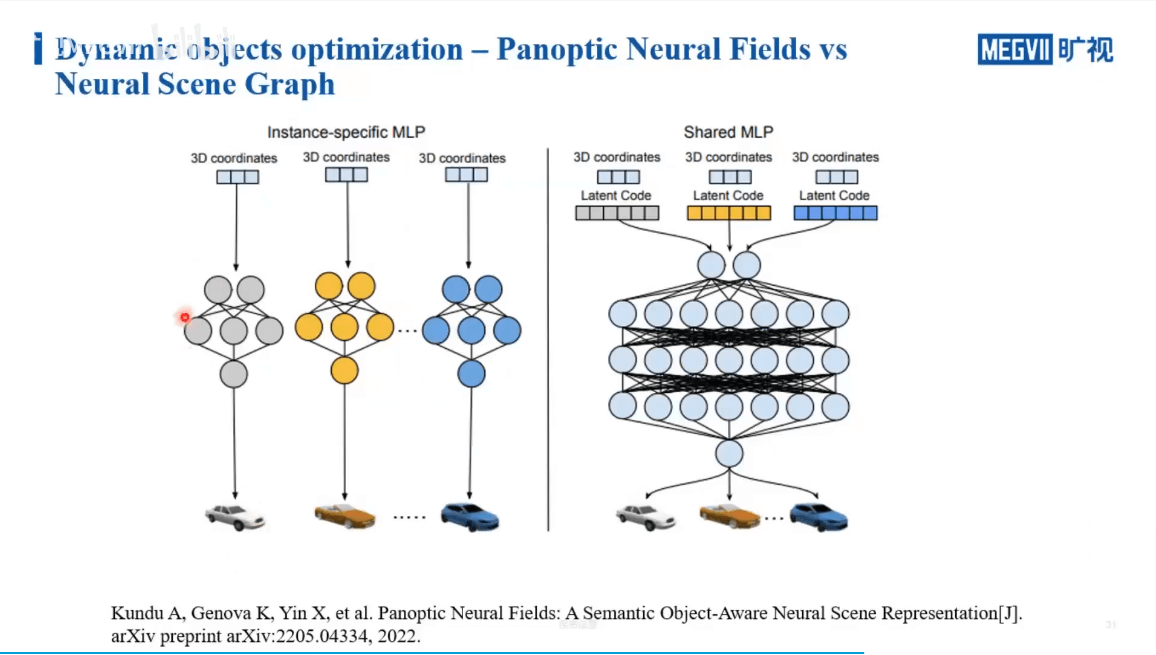
一种方法是,我们可以对每一个运动物体单独用一个很小的NLP来学习,通过多个NLP最终对每个运动目标进行恢复。另一种则是,对于一类物体,共享一个大的NLP,通过学习latent code来区分不同的实例。这两种方式需要根据具体场景决定。当场景中车辆很多的时候,前者的参数量或者学习难度是随着数量而线性增长的,而后者因为共享参数则不会有明显的增长。但如果我们需要对每个车进行精细的建模,那么显然前者更加合适一些。实际渲染过程与结果如下图所示。
5.3 大场景挑战
最后一部分是NeRF在大场景中的挑战,如何平衡性能与精度等问题,如下所示。
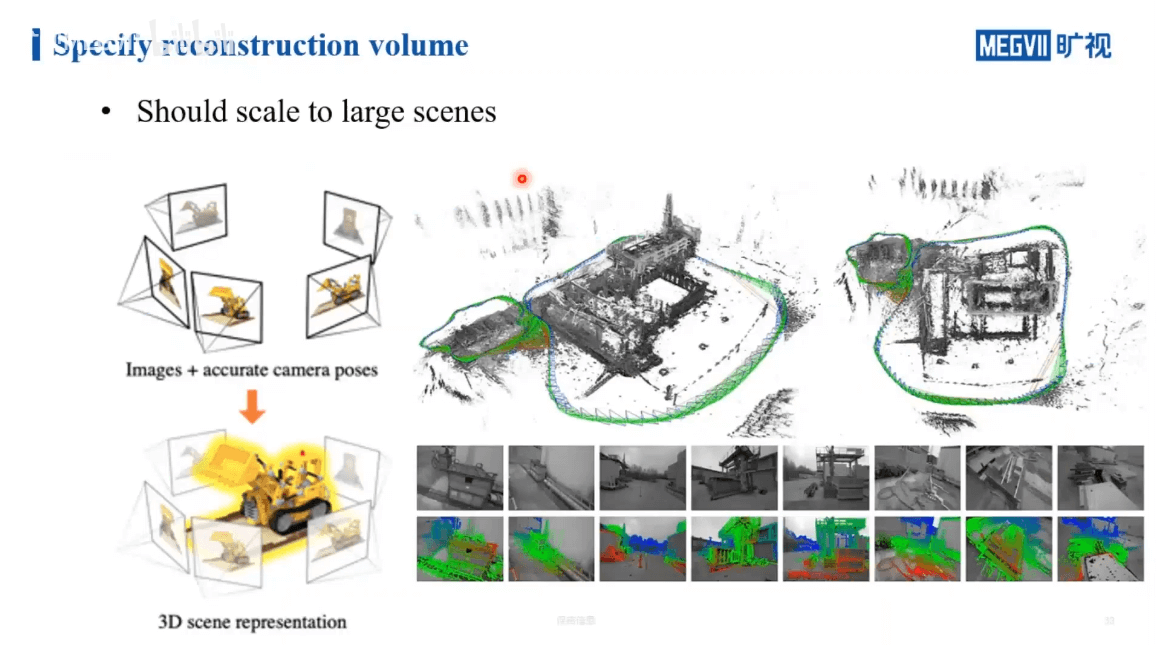
如上图所示,对于一些较小的场景,观测一般都是由外向内进行聚合的。这样我们很容易得到被摄物体的三维包围框。但在室外等大场景中,很难有一个三维的包围框可以把整个场景包含在里面。另外,对于室外的场景,还不可避免的有“天空”问题。在采集过程中,很多视角都会采集到天空的像素,但事实上这些像素是我们重建中不需要考虑(简单的方法是增加mask)。此外还有远处场景的细节优化问题等。对于大场景的建模,还是相对复杂的。

如上图所示,在最左边的图中,我们给远处分配较大权重,那么近处就会相对模糊。反之,近处权重高以后,远处又会变模糊。所以其实是比较难的问题。在KITTI数据上也是一样,远处的树木可能发生一些偏移。所以总结起来就是,我们没有办法通过有限的资源来掌握场景中的所有细节。尽管很困难,但还是有相关工作,如下。

Block NeRF主要是针对街景数据的处理,通过对场景进行分块,并保证各个块之间有重叠,实现多个NeRF的联合。Mega NeRF主要是针对无人机数据的处理。它的思路和Instant NGP和KiloNeRF有一定的相似之处。下图展示了Block NeRF更细节的内容。
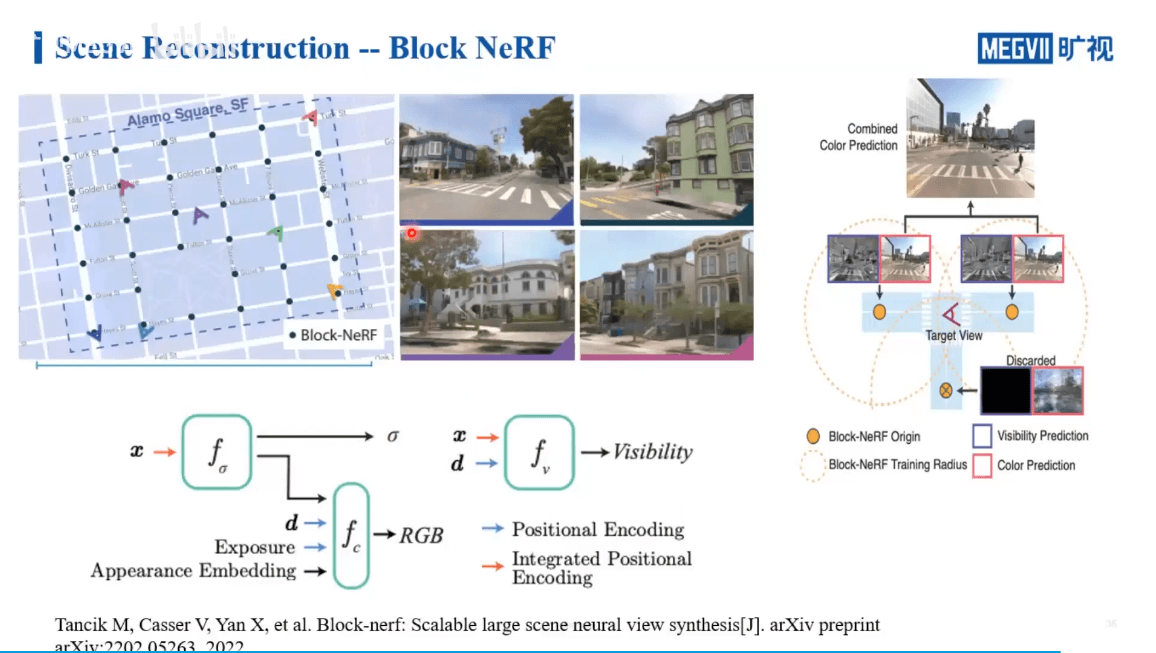
这里还引入了Visibility概念。简单来说就是,如果我们要渲染某个位置的影像,理论上来说我们要查询所有的NeRF网络,找到那些和当前视角相关的进行渲染。但这样每个NeRF网络都查询,显然是非常耗时的。所以作者又训练了一个小网络。这个网络的作用是判断某个位置是否在当前NeRF的场景中。这样只需要查询相关的NeRF网络就可以,而不需要每个都遍历,提升了效率。



