论文阅读《DENSE RGB SLAM WITH NEURAL IMPLICIT MAPS》
本论文提出了一种具有神经隐式映射表示的稠密RGB SLAM。该方案不需要深度输入,并且不需要任何预训练模型。为了实现这一目标,本文引入了一个分层的特征体积来辅助隐式地图解码器,有效地融合不同尺度的形状线索以促进地图重建。同时,通过匹配渲染和输入视频帧来同时解决相机运动和神经隐式地图。为了更好地约束相机姿态和场景几何,本文进一步在损失函数中应用了光度曲翘损失(sophisticated warping loss)。
本文亮点如下:
- 第一个使用神经隐式表达实现了稠密重建的RGB-SLAM系统
- 不需要任何预训练模型,如单目深度估计和光流,就能同时优化场景和相机位姿。
- 相机位姿的准确度超过了以前的方法并且甚至超过了一些最新的RGB-D SLAM方法。
系统概述
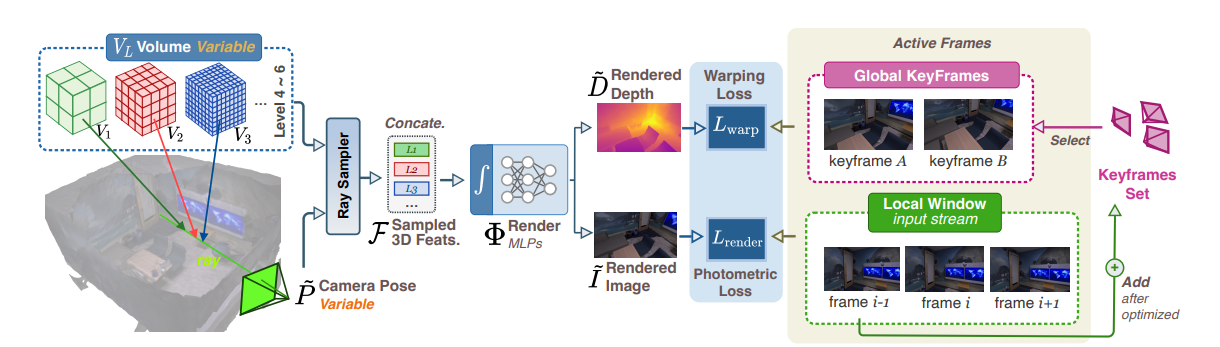
给定RGB视频作为输入,本文的方法旨在同时恢复3D场景图和相机运动。通过具有可学习的多分辨率特征体积的神经隐式函数来表示场景图。通过沿着视图光线从体积网格中采样特征,并使用MLP解码器查询采样特征,可以在给定估计的相机参数的情况下渲染每个像素的深度和颜色。由于此渲染过程是可区分的,因此可以通过最小化在光度渲染损失和翘曲损失上定义的目标函数来同时优化神经隐式贴图以及相机姿势。
IMPLICIT MAP REPRESENTATION
这部分和NICE-SLAM差不多,省略了。
JOINT OPTIMIZATION
这里应该是这个工作最关键的地方
本文用的损失函数和单目深度估计的一些工作比较相似
本文所使用的损失函数由三种损失构成:
Photometric Rendering Loss:
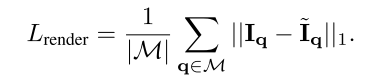
PhotometricWarping Loss:

Regularization Loss:
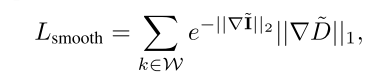
最终要优化的目标函数为:
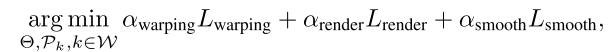
System
本节介绍了构建完整的视觉SLAM系统的几个关键组件。
初始化 当收集到一小组帧(在本文所有的实验中为 13 帧)时执行初始化。 第一帧的姿势设置为单位矩阵。 然后剩余帧的姿势从 Ni 迭代的目标函数中优化。 初始化后,第一帧被添加到全局关键帧集中并固定。 MLP 解码器的参数在初始化后也是固定的。
初始化这一步应该类似传统的单目SLAM,目的是得到尺度和世界坐标系?
另外,解码器是MLP网络,而编码器是Nerf里那种Positional encoding?
窗口优化 在摄像机跟踪期间,本文的方法始终保持活动帧的窗口(在本文的所有实验中为 21 帧)。 活动帧包括两种不同类型:局部窗口帧和全局关键帧。 对于帧 k,本文将索引从 k − 5 到 k + 5 的帧视为局部窗口帧。 本文进一步从全局关键帧集中采样 10 个关键帧。 具体来说,本文在帧 k 上随机绘制 100 个像素,并使用估计的相机位姿 P 和深度 D 将它们投影到所有关键帧。 然后,本文通过计算投影在这些关键帧边界内的像素的百分比来评估视图重叠率。 之后,本文从重叠率超过 70% 的关键帧中随机选择 10 个关键帧来构成全局关键帧集。 然后,所有这些活动帧都用于优化隐式场景表示和 N_w 次迭代的姿势。 窗口优化后,最旧的局部帧 k-5 被删除,一个新的具有等速运动模型的 k+6 帧被添加到局部窗口帧的集合中。在跟踪期间,所有全局关键帧的相机姿势都是固定的。请参阅附录中有关窗口优化的两个线程情况下的映射。
应该是比较常见的方法
关键帧选择 遵循类似于iMAP和NICE-SLAM的简单关键帧选择机制。具体来说,如果视野发生显著变化,则会添加一个新的关键帧。
思考
Q1:训练Nerf需要的输入是什么?需要深度吗?
训练NeRF的输入数据是:从不同位置拍摄同一场景的图片,拍摄这些图片的相机位姿、相机内参,以及场景的范围。若图像数据集缺少相机参数真值,作者便使用经典SfM重建解决方案COLMAP估计了需要的参数,当作真值使用。
Q2:Nerf的流程是什么?
NeRF里的五维向量(位置+视角)是指从相机原点出发的一条射线上的点和射线的方向(变换到世界坐标系)?如果是的话,NeRF整个流程应该是下面这样:
- 数据预处理:根据所有图像数据,得到相机内参(焦距,1个参数)、相机位姿(坐标变换,12个参数)和稀疏3D点(推理物体离相机最近和最远距离,2个参数),给每张图像赋予17个参数(1+12+2+2,其中最后一个2为图像的长宽)
- 训练:准备好图像(用于提供real像素值)和17个参数,根据相机位姿和相机焦距得到成像平面,并根据图像的长宽限制成像范围。取成像平面中某一位置(对应的real像素值是已知的),与相机位置的连线构成一条射线,得到二维的视角参数,在最近和最远距离内采样 n 个点,得到三维的位置参数,构成n个五维向量。然后根据相机位姿参数转化到世界坐标系,送入MLP中,预测每个点的rgb和sigma,此时并不会直接对采样点进行监督,而是根据体渲染得到fake像素值,通过real和fake之间的误差来监督训练。
- 测试:只要事先确定17个参数,其他步骤和训练类似。
需要注意的是,原始的nerf代码假设光心偏移量是H/2, W/2。另外,实际代码实现的时候,视角用的是三维的方向向量表示。
Q3:Nerf、iMAP、NICE-SLAM、DIM-SLAM在损失函数上的区别
Nerf:损失函数是粗略和精细渲染的渲染像素颜色和真实像素颜色之间的总平方误差。
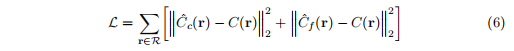
iMAP:光度损失是渲染和测量颜色值之间的L1范数;
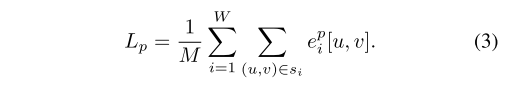
几何损失测量深度差异,另外还使用深度方差作为归一化因子,在对象边界等不确定区域降低损失。
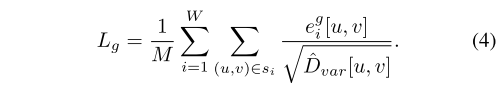
最终优化的目标函数是这两个损失的加权和:
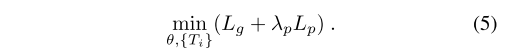
NICE-SLAM:几何损失只是在粗糙层和精细层上观测深度和预测深度之间的L1损失;
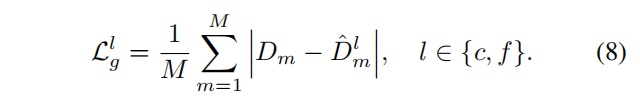
光度损失是M个采样像素点上渲染颜色和观测颜色值之间的一个L1损失。
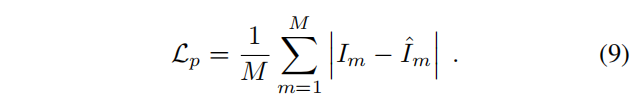
最终优化的目标函数为:
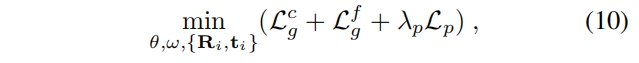
DIM-SLAM:见本文的[JOINT OPTIMIZATION](#JOINT OPTIMIZATION)部分。
Q4:NICE-SLAM、Nerf等工作是如何沿着相机射线进行采样的,深度d要如何确定?
TODO,这里完全不了解。。。
分享两篇文章:
- 深度学习之单目深度估计 (Chapter.1):基础篇 - 桔子毛的文章 - 知乎 https://zhuanlan.zhihu.com/p/29864012
- 深度学习之单目深度估计 (Chapter.2):无监督学习篇 - 桔子毛的文章 - 知乎 https://zhuanlan.zhihu.com/p/29968267



