Feature-Realistic Neural Fusion for Real-Time, Open Set Scene Understanding
回顾iMAP
这篇工作很大部分都基于iMAP,去年暑假我翻译了这篇论文
使用隐式神经场景表示并能够联合优化完整 3D 地图和相机姿势的稠密实时 SLAM 系统。(使用多层感知器 (MLP) 作为手持 RGB-D 相机的实时 SLAM 系统中唯一的场景表示)
iMAP系统框架
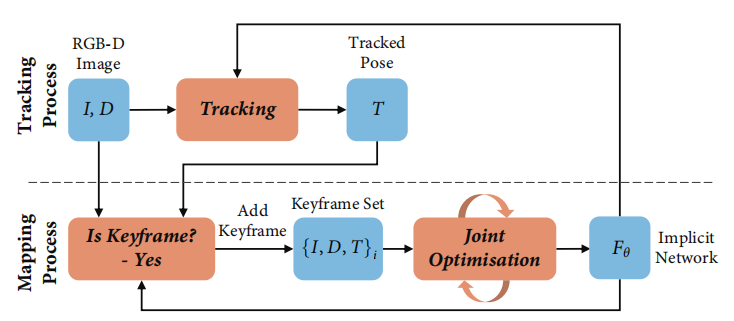
大概是这么运行的,个人猜测
Implicit Scene Neural Network
MLP的作用是保存3D场景,输入一个3D坐标经过处理可以查询到这个点的颜色和体积密度值;
通过查询的结果可以渲染出该点的深度和颜色。
Depth and Colour Rendering
根据当前的相机位姿和某些关键点的像素坐标,反投影得到这些关键点的世界坐标;
通过MLP查询这些世界坐标的颜色和体积密度值;
根据颜色和体积密度值进行深度和颜色的渲染;
将渲染的颜色图和深度图与当前相机真正看到的图作比较,计算误差;
根据误差进行优化,更新了?(更新的是相机位姿?还是网络参数?这两个怎么处理?)
Joint optimisation
根据误差进行联合优化,更新网络参数和相机位姿;(光度损失和几何损失表面上是和位姿有关的,但是渲染是通过网络渲染的,所以应该就可以联合优化,但具体怎么做我不清楚。。。)
这里损失函数专门赋予光度误差权重,应该是要减轻光照的影响。
Keyframe Selection
根据稀疏的关键帧来进行联合优化。其中,第一个关键帧用于初始化网络和固定世界坐标系。
这篇工作关键帧选择的方案是:
检测新区域的显著性(新区域是不是非常新?非常新就加入关键帧!)
这里似乎是用深度误差来判断的,判断一个新区域里面已经被解释的帧的比例。
Active Sampling
略。这里印象中不重要,并且nice-slam里面似乎说这部分对性能提升的影响非常有限。
主要工作
提出了一种算法,该算法将来自标准预训练网络的一般学习特征融合为实时SLAM期间高效的3D几何神经场表示。融合的3D特征图继承了神经场几何表示的一致性。这意味着在运行时交互的微小数量的人类标签使对象甚至对象的一部分能够以开放集的方式被稳健地准确地分割。
把iMAP和预训练特征融合起来了?
Method
Overview
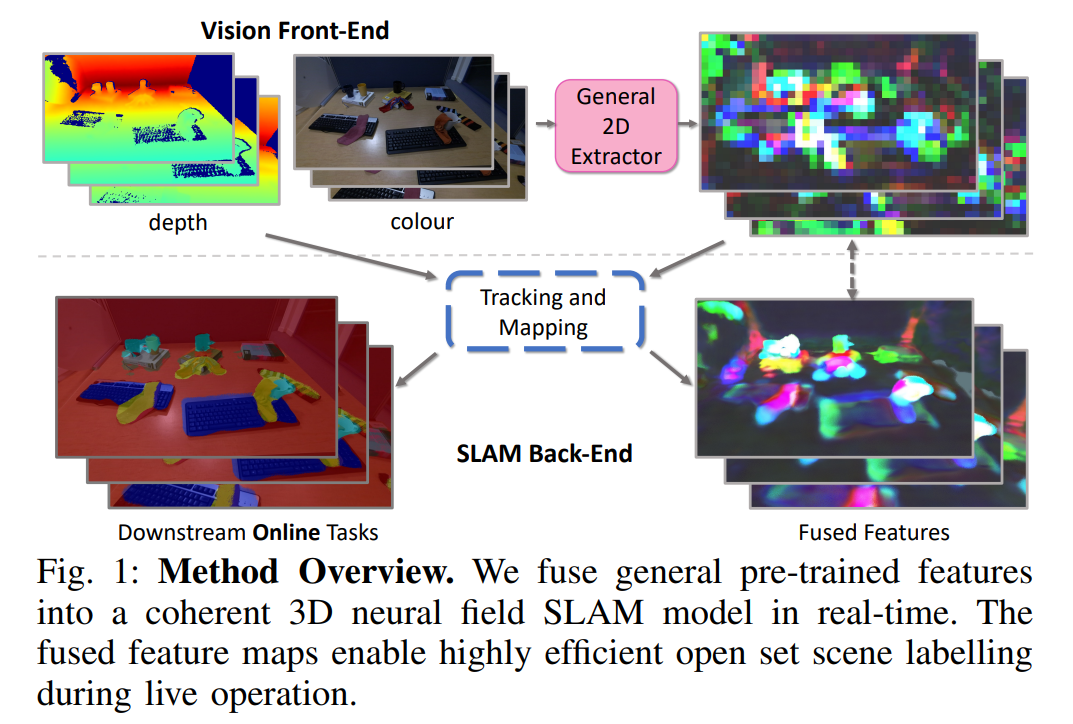
该系统主要由两个部分组成:
预训练的2D图像特征提取器
被冻结了,指的是网络参数不会被改动?所以输入的图像特征就是固定不变的了,相当于相机的参数被固定了?
类似iMAP的SLAM系统,即SLAM后端
本文的一般方法是通过体积渲染来近似一组特征图,这些特征图是用特征提取器 F 从一组图像中获得的。这里放弃了对颜色和依赖视图(view-dependant)的效果进行建模,以缓解场景MLP的问题。
A. Scene Network

该场景表示网络由两个部分组成:
左边是类似Nerf的MLP,用于表示整个场景,即三维神经场;
右边是单层感知器,根据2D渲染的结果得到最终的特征图。
MLP网络:
输入三维坐标,输出体积密度、特征向量、语义对数。
在进入MLP网络之前,有一个Positional Encoding过程,这里目的是确保拟合高频特征映射的表示能力
nerf里面有一个差不多的过程,见NeRF学习笔记(一):论文翻译
根据MLP输出的体积密度计算了体积渲染权重,然后根据这个权重计算深度、特征、语义逻辑。
这里的“语义逻辑”有什么用处?这是每个特征的标签吗?
这部分,前两个公式和iMAP基本一样,w的意义也一样

关键帧选用与iMAP一样,根据深度渲染的误差来选择。
B. Latent Feature Rendering
这里主要介绍前面讲的一种潜在的特征渲染方法。
本文没有使用之前Nerf那种的渲染方法,而是使用了感知器来解决渲染问题。
看起来是只有一个感知器,然后渲染了每个点的特征?

C. Feature Extractors
这里就提了一句本文构建的系统对2D前端是不可知的,大概用什么样的特征提取器提取特征都可以,但是这个系统还是能够融合这些提取出来的特征。
总结
根据目前我理解的内容,本文的系统框架应该是下面这样的:
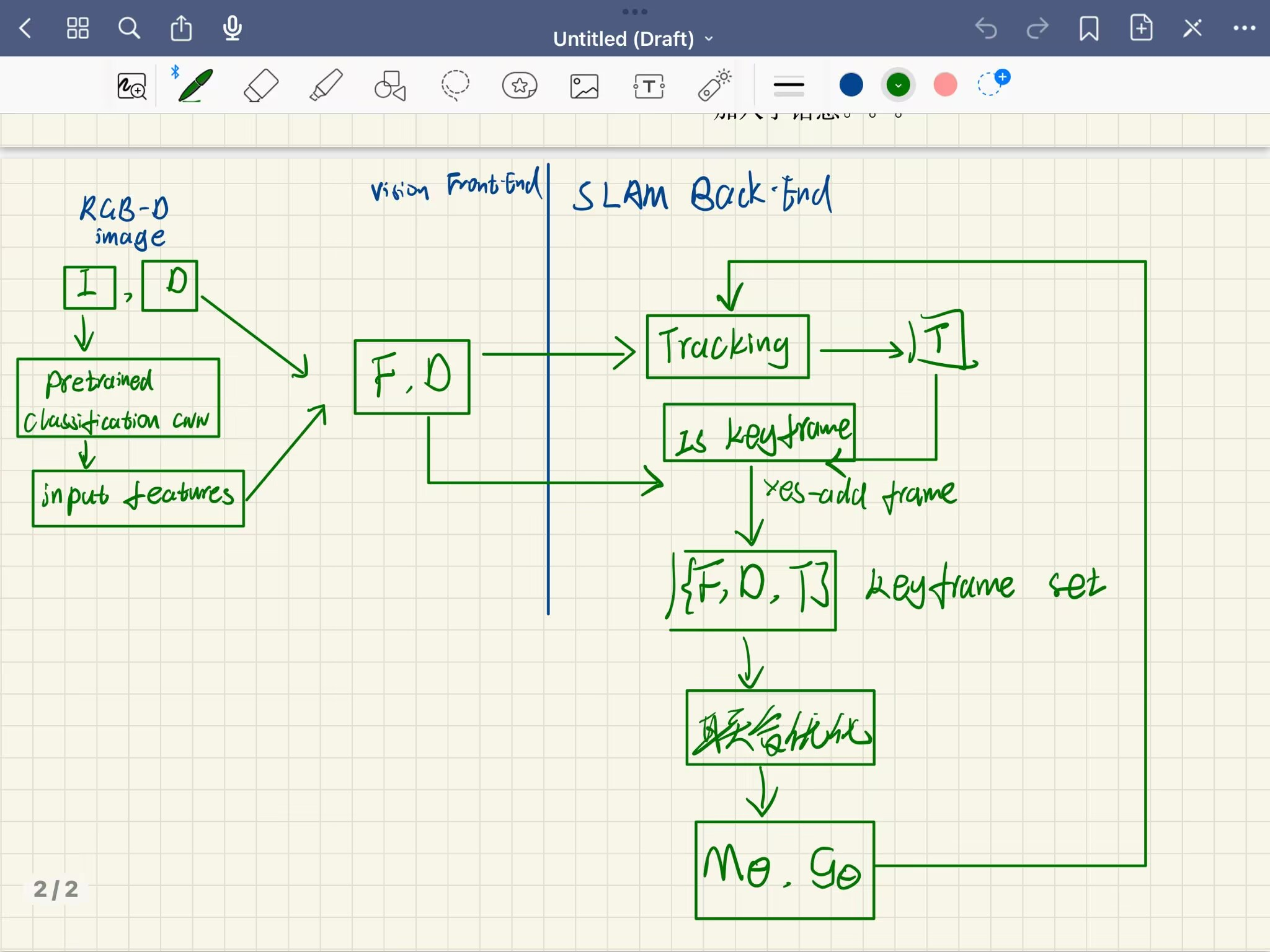
和iMAP不一样的地方是:
- 输入:对输入的RGB图像做了一个特征提取,将原本的{I,D}输入变成了{F,D};
- 网络部分:都是输入三维点坐标,iMAP网络输出颜色和体积密度值,而本文是特征、体积密度和语义(多了一个语义);
- 渲染部分:本文和iMAP的公式基本一样,但本文把渲染后的特征又用感知器进行了一遍处理。



