NeRF学习笔记(五):神经隐式SLAM方法
iMAP: Implicit Mapping and Positioning in Real-Time
Motivation
A multilayer perceptron (MLP) can serve as the only scene representation in a real-time SLAM system for a handheld RGB-D camera.
Novelty

Methods
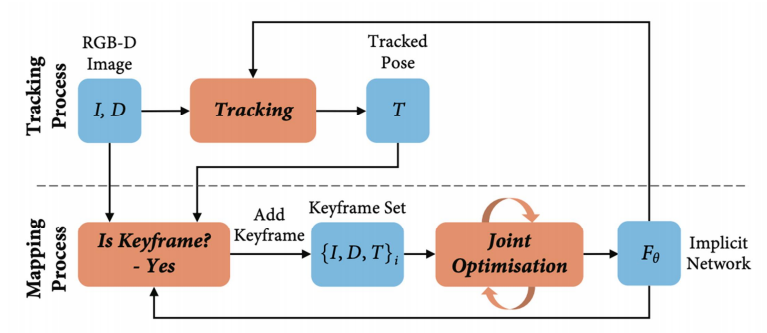
System Overview
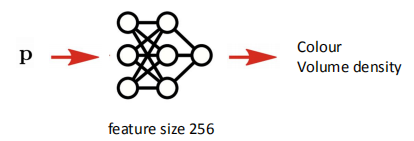
Implicit Scene Neural Network
Depth and Colour Rendering

Joint optimization/Camera Tracking

Keyframe Selection
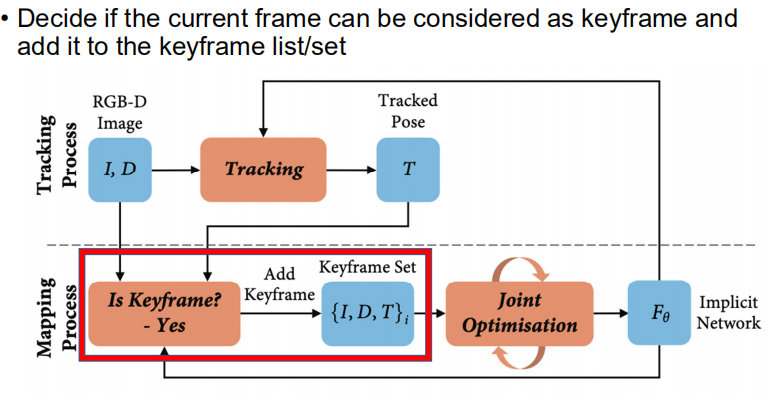

大致的流程如下:
- 假设有一个keyframe已经加入了,此时复制网络的参数,作为当前地图的snapshot(就是新增keyframe就更新当前地图的snapshot);
- 然后每次新得到一帧图像,就从当前的snapshot渲染一张depth图(这里不需要是渲染整张图,可以是渲染一部分,得到一个统计规律);
- 根据渲染的pixel samples,和ground truth的pixel相减,观察新观察到的一帧,有百分之多少的区域是已经被之前lock的network表达了;
- 如果这个区域并不是很多,说明这一帧有很多新的地方,就应该加入到keyframe list中。
Active Sampling
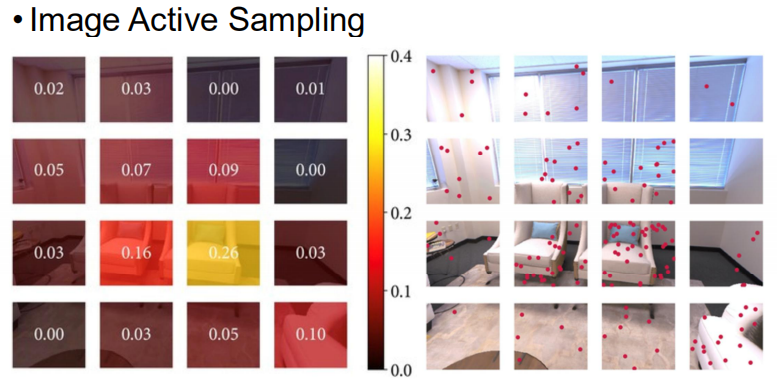
这里的操作是:
- 把一张图分成很多的bin(箱子),然后均匀的采样并且渲染出来,观察loss的分布是什么样的。
- 之后我们根据loss的分布来分配pixel的数量。如果有的地方loss相对较大,那这些区域就应该更多的优化,可以多sample一些pixel。(从上图就能看出来,loss大的地方,右边小红点也要多一些)

这里的操作是:
- 每次mapping的时候只选常数个keyframe,比如只选5个keyframe加入到mapping中。
- 可以设计更好的机制进行keyframe的选择,比如对每个keyframe都进行一下渲染,然后看看loss的分布是什么样子的。如果有的keyframe的loss比较大,就应该加入到mapping中,loss比较大就说明网络已经忘掉之前学习的keyframe了,我们应当让这些keyframe参与mapping来加强网络的记忆。
Experiments
Scene Reconstruction Evaluation
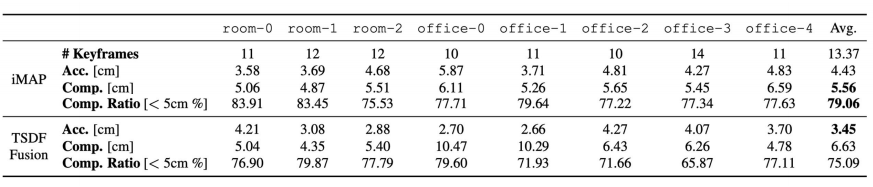


这里做实验的时候,需要注意TSDF Fusion只是一个mapping的方法,必须给他一个相机位置,而如果给ground truth肯定不公平,所以给了iMAP的相机位置。
上面的表格中,加粗的数据是最好的,可以发现TSDF Fusion的误差(Acc.)最低,而iMAP的Completion和Completion Rational都是最高的。
分析:
对于TSDF Fusion,它确信的地方才会建图,不确定的地方不会建图,所以Accuracy会高一些(Accuracy指的是重建的结果到ground truth的距离),也是因为这个,他的completion会低一些。
TUM Evaluation
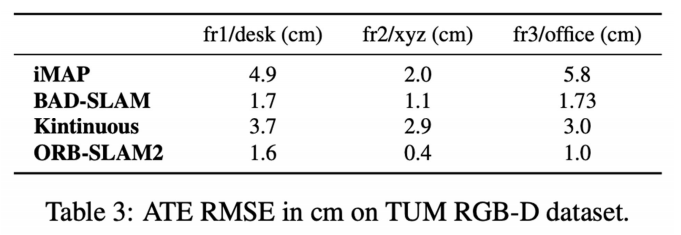
这里把iMAP和另外三种传统方法作了比较,表中的数据是误差。可以看到iMAP的误差比较大,但是还是说明iMAP能够在TUM这样比较复杂的数据集上面跑通。

类似于之前的比较,iMAP能够填补一些没有看到的地方。
Ablative Analysis
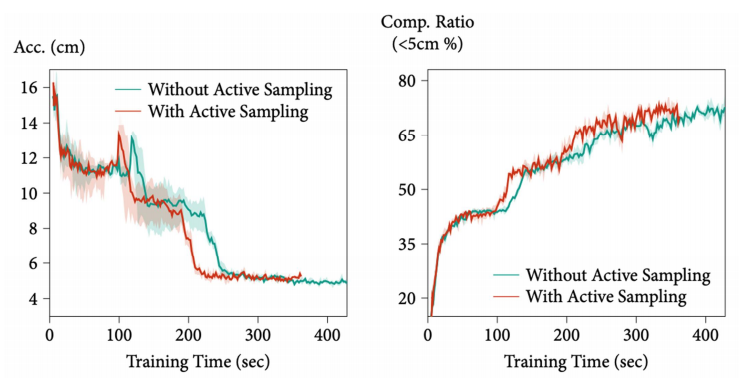
这里比较了有无Active Sampling的区别。Acc.是误差,越低越好,而Comp. Ratio是越高越好,可以看到Active Sample是能够起到比较好的效果。
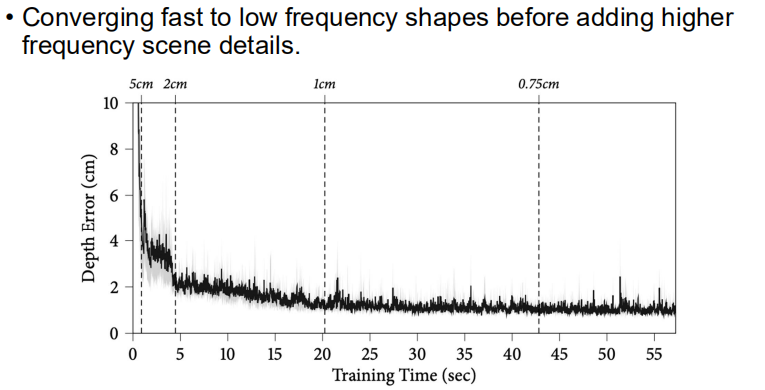
iMAP这个工作还发现,网络能够很快的把低频的信号收敛的比较好,而高频的细节需要慢慢的加入。
从上面可以看到,网络可以很快地把Depth Error降到比较小,但如果要继续的降低误差就比较难了。

这里展示了网络重建的过程,和上面的图是对应的。可以看到网络能够很快把大致的样子重建出来,然后再慢慢的加细节,比如书柜上面、墙上面的一些细节。
NICE-SLAM: Neural Implicit Scalable Encoding for SLAM
NICE-SLAM可以在大规模的室内场景中生成密集的几何与准确的相机跟踪。
Neural Implicit Representations
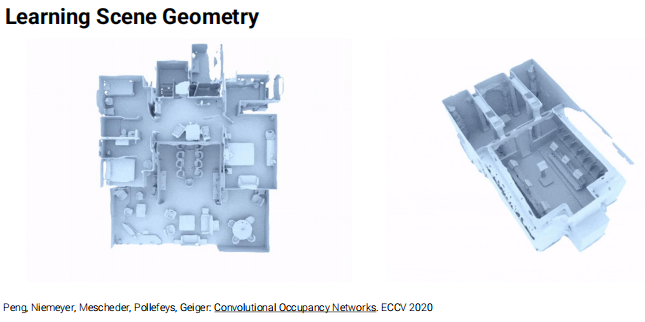
神经隐式表达可以捕获高保真的几何
也可以渲染很高清晰度的图片

iMAP vs NICE-SLAM

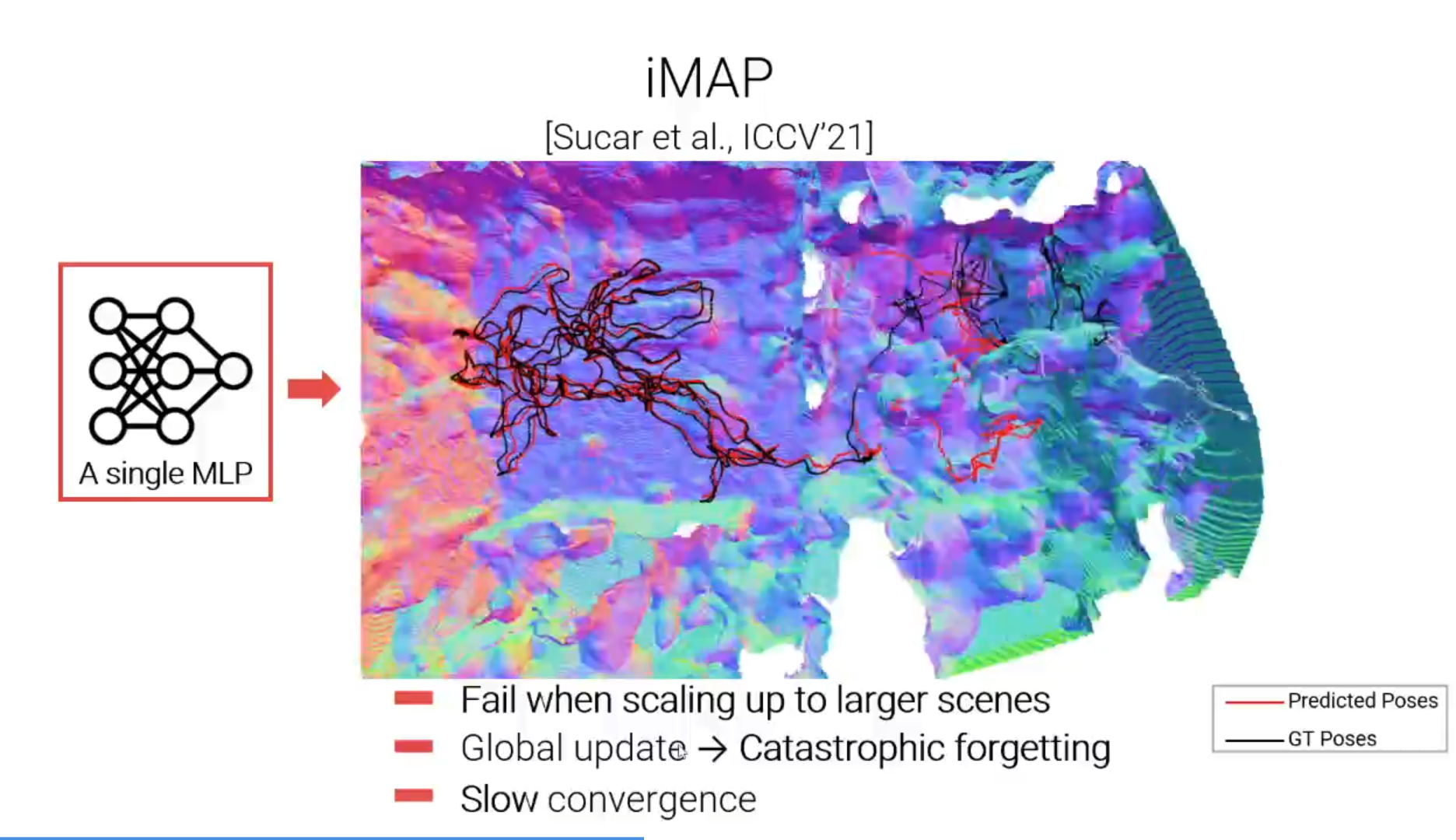
iMAP是通过持续学习的方式同时估计相机位姿和密集的场景几何。但是由于iMAP使用单个MLP作为场景的唯一表达,所以存在以下问题:
- 容量有限,当场景变大时,iMAP会失败;
- 每个新输入的RGBD帧都可以更新整个MLP,因此会遇到遗忘的问题;
- 优化整个MLP非常慢,尤其是当MLP变得非常大时。
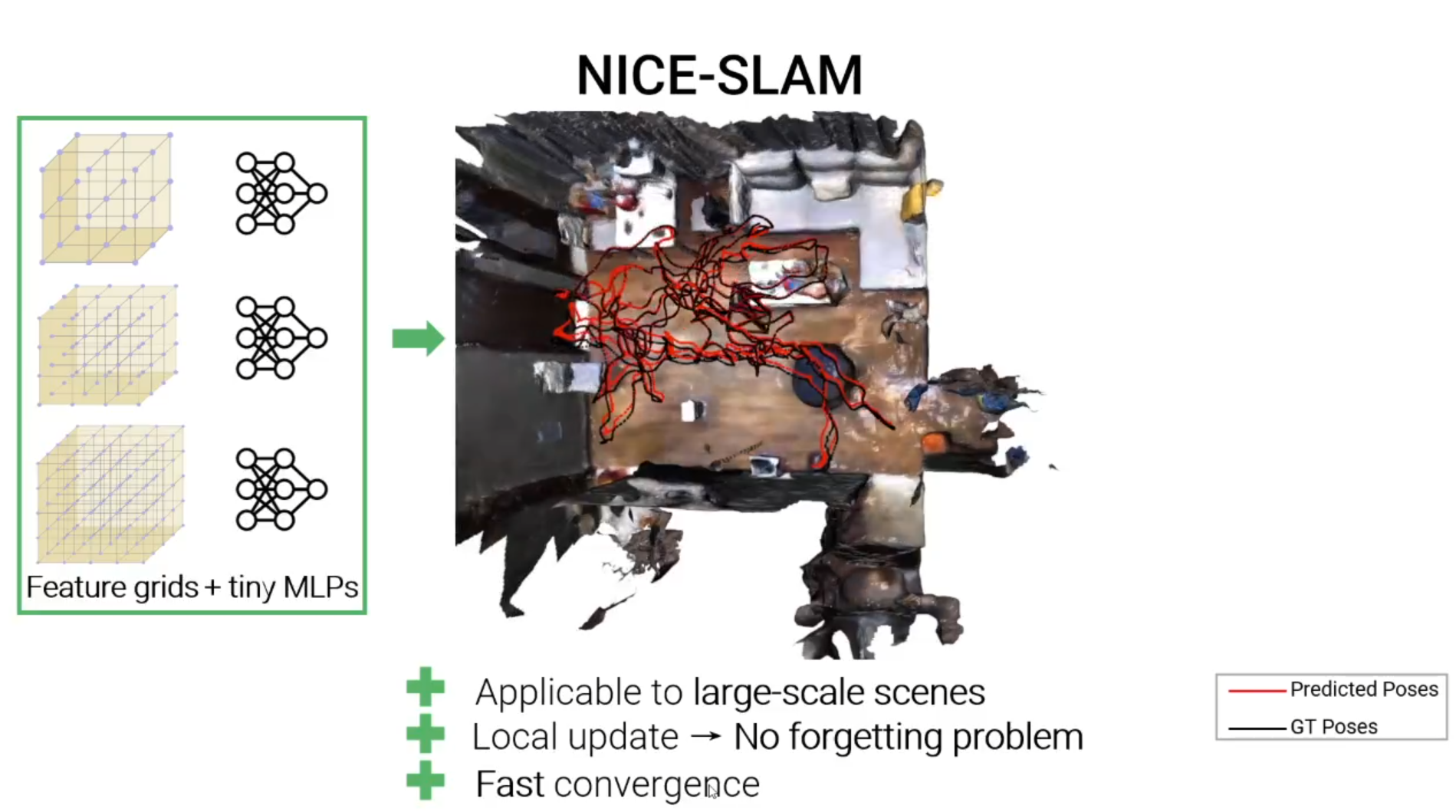
相比之下,NICE-SLAM对场景表达做了简单有效的改进,优化分层特征网格,并且结合不同空间层级下训练的微型MLP的归纳偏差,使用这种表达NICE-SLAM在大规模室内场景表示中表现良好,解决了网络遗忘问题,并且保证了更少的运行时间,可以快速收敛。
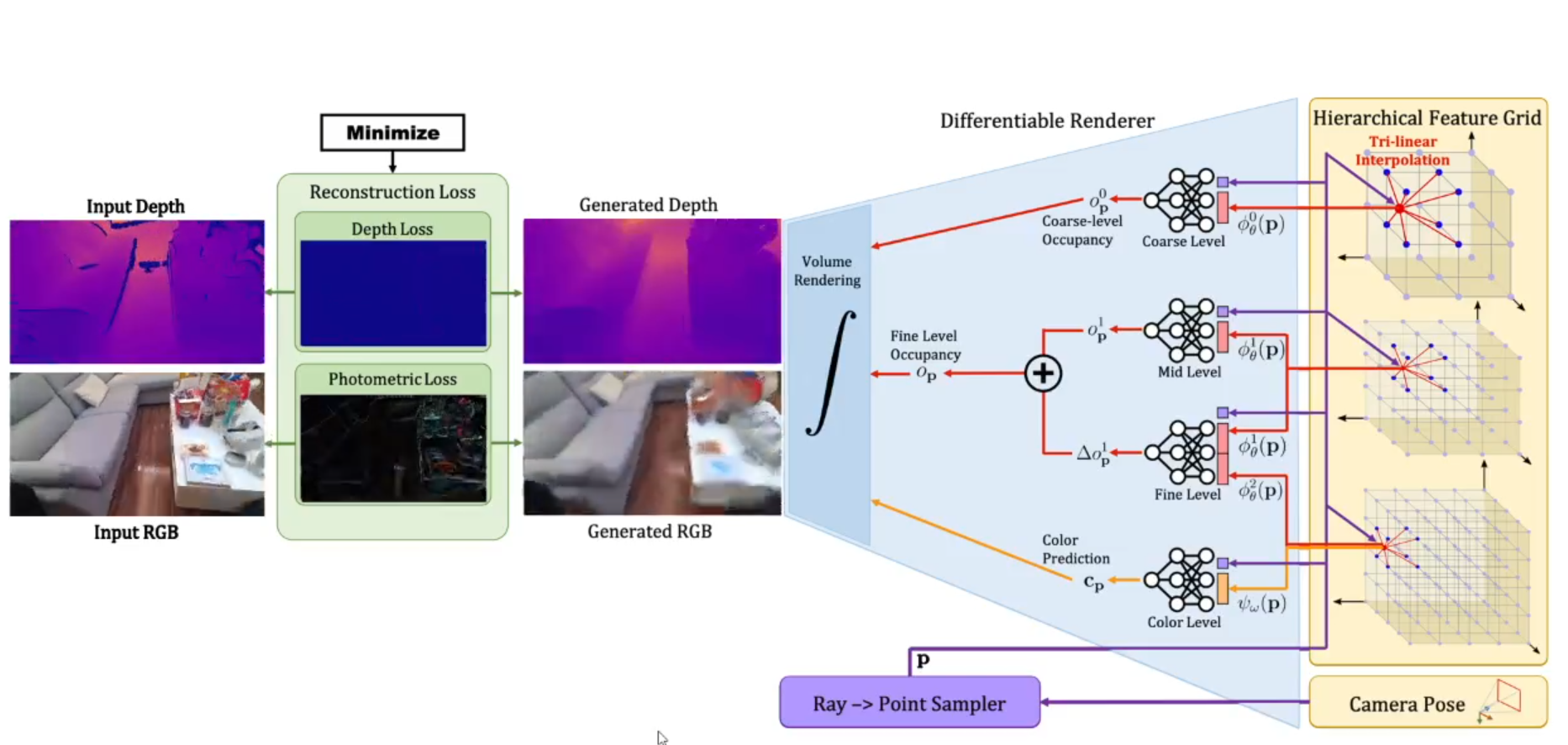
Pipeline
如下图,左侧为RGBD序列,NICE-SLAM同时估计相机位姿和场景的三维几何,表示为分层特征网格,如右侧所示。
首先,根据相机参数随机采样射线,沿每条射线进行三维点的采样,并且使用三线性插值提取每个点的特征(对应图中右下角”Ray -> Point Sampler“部分);
接着,使用微型的MLP预测光线上三维点的占用值和颜色值(对应图右侧浅蓝色部分);
最后,使用类似NeRF的体渲染方程,沿射线去和,生成深度和彩色图像(对应图中间深蓝色的部分)。
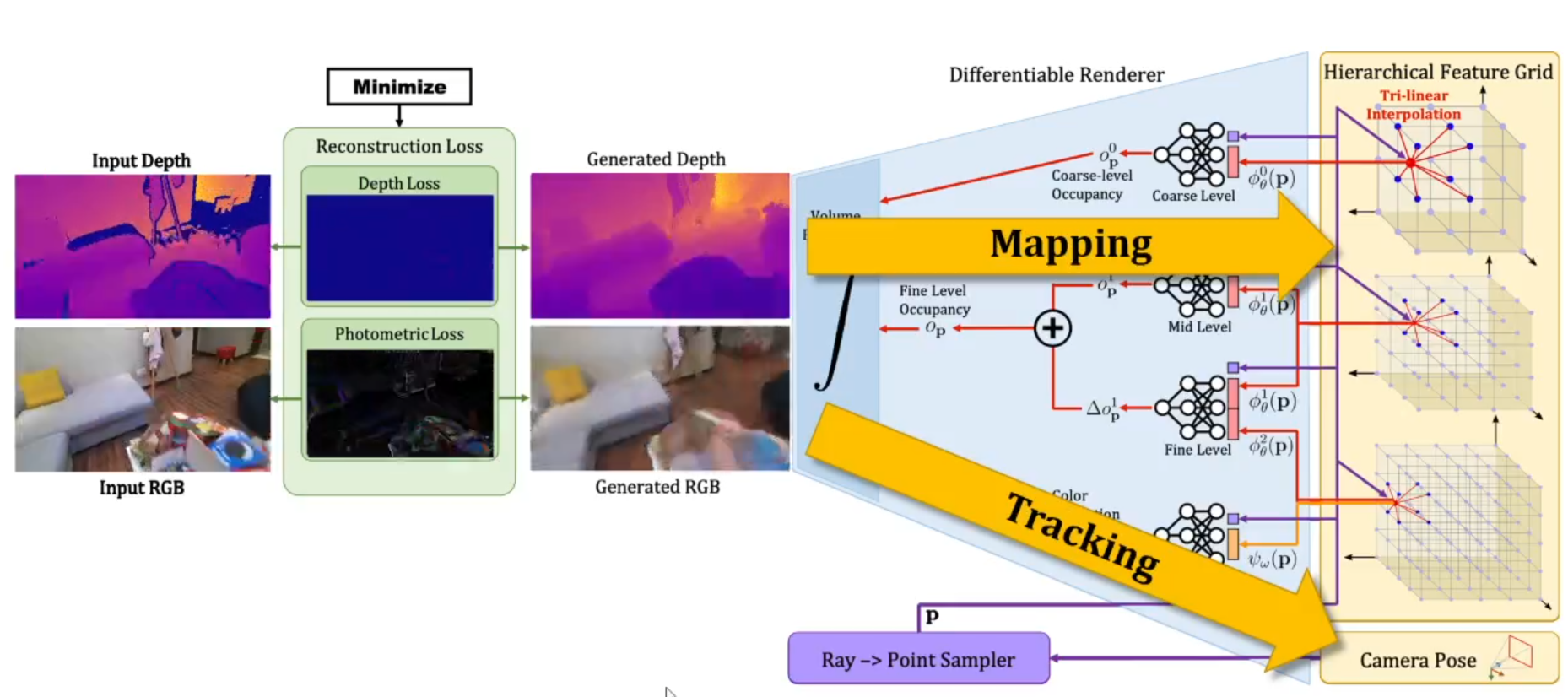
我们关注输入和生成图像之间的重渲染损失,由于渲染过程是可微的,能够以交替方式反向求导,最小化重渲染损失。通过优化分层特征网格来实现mapping;通过优化相机参数来实现tracking。
MLP pretraining
微型MLP,也就是MLP的解码器,是作为Convolutional Occupancy Networks的一部分进行了预训练。而Convolutional Occupancy Networks由一个CNN的编码器和一个MLP的解码器组成,与其相同,我们在训练的时候也是使用了预测值和真实值之间的交叉熵损失来训练编码器和解码器。
训练之后,NICE-SLAM使用解码器的MLP,这样在优化特征网格时,预训练的解码器可以利用从训练集中学习到的特定先验来指导优化。
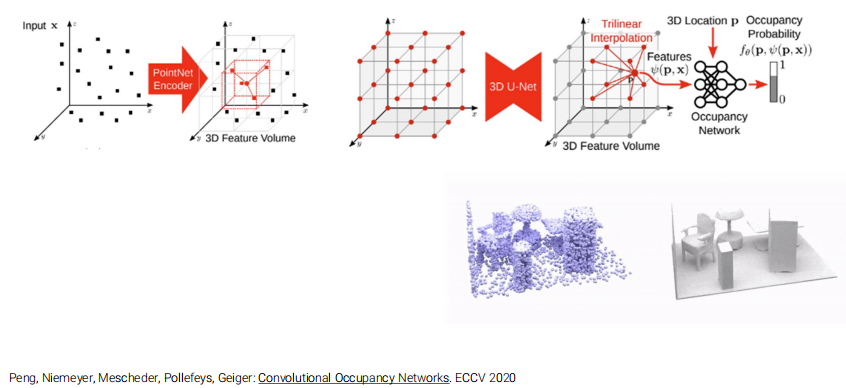
More About Feature Grid
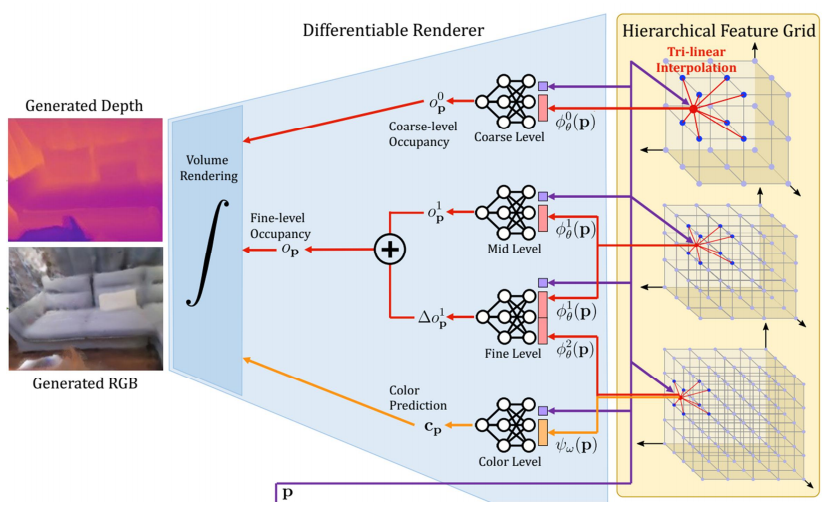
图中的MLP都是在上面Convolutional Occupancy Networks的框架中训练出来的。
Coarse Level对应的网格分辨率比较大,单独的出一个Occupancy,单独的渲染一张depth图,只会用在没有被观测到的部分上;
Mid Level对应的是分辨率中等的特征网格,从中拿到feature和点坐标,过MLP可以得到一个occupancy值;
Fine Level是在Mid Level的基础上预测一个Δ,它是从更高的分辨率里得到feature,并且把中等分辨率的也考虑进来。最后这两个MLP得到的occupancy叠加起来,得到最后Fine Level的Occupancy;
Color Leve这里,颜色是需要比较高分辨率的Feature Grid,因为高频信息比较多,然后只从Hierarchical Feature Grid里面取到feature,然后跟点坐标一起过MLP,拿到color prediction;
最终通过类似NeRF的渲染器得到depth和color图。
需要注意的是,这里的几何MLP(Coarse Mid Fine Level)都是fixtures的,这样就可以进行局部的更新,因为这样voxel feature是和位置有关的,不会像iMAP一样改变MLP的一个参数就影响整个梯度。
Depth and Color Rendering

需要注意的地方:
- NICE-SLAM没有第二轮采样(NeRF和iMAP都有第二轮采样,第二轮采样根据第一轮采样的结果进行分配),因为本身有depth图,可以在depth图对应的表面附近多采样一些,根据经验将采样间隔定义为5%的depth值(depth值指的是当前光线的深度值)。所以这里的Importance就直接在表面附近采样。
- NICE-SLAM使用了Occupancy作为几何的表达而不是volume density,因为volume density过了marching cube之后结果都不是很好(主讲人这里说有一些工作中有对比图)
Mapping

需要注意的地方:
Geometric loss指的是渲染出来的depth要和ground truth观测的depth尽可能接近的loss
Photometric loss就是渲染出来的颜色也要和ground truth接近的loss
Staged optimization
- 第一阶段只优化mid-level,使用几何损失
- 第二阶段联合优化mid 和 fine level,仍然使用几何损失,因为目前还是没有color图
- 第三阶段进行BA操作(Bundle Adjustment),在之前的基础上加上了color图和相机位置
总的目标函数是两个几何的loss(一个是coarse level的depth图,一个是mid和fine level加起来渲染出来的depth图),和一个根据颜色的loss
最小化的待优化变量是所有的网格的参数,由于color的MLP没有找到比较好的训练方式,所以这里把color的MLP参数(w)加到里面去,同时相机的外参(R和t)也要加到里面去
NICE-SLAM使用了三个线程。一个线程是coarse level,一个线程跑staged optimization,一个是前端相机的tracking
Tracking

保证局部更新的两个系统设计
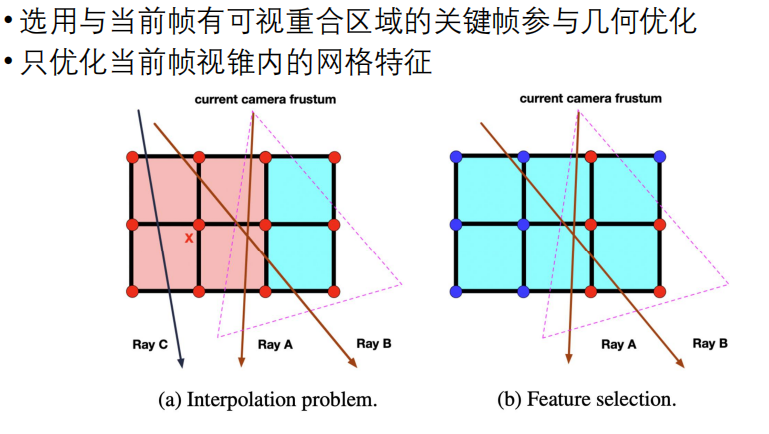
NICE-SLAM基于网格的表示是只支持局部更新并且不会遭受与iMAP相同的遗忘问题,这两个设计不仅可以确保当前视图之外的几何保持静态,同时使得优化非常有效,每次只需要优化必要的参数,即优化当前视锥内的网格特征,不需要把整个网格所有特征放进来优化。
上图说明了只优化当前视锥内的网格特征的有效性。图中每一个节点都表示一个网格特征,节点是红色的表示可以被优化,蓝色表示不可以被优化。
左图中,所有的feature都可以被优化,选择一些keyframe,这些keyframe会射出一些射线。假设射线A和B就是目前要进行优化的,射线上面会进行采样,影响到x点的feature,而x点的feature会影响到左图中红色区域。如果有一个射线C,因为射线C没有参与到mapping,所以我们希望射线C渲染出来的结果跟以前一样,但假如x点变了,那么渲染的结果就变了,与我们的希望不符。
为了解决上面的问题,就只对当前视锥内的网格特征进行优化,如右图所示。这样不仅会保留之前重建的几何形状,并且在优化的过程中也会显著的减小参数的数量。
Results
Reconstruction Results on the Replica Dataset

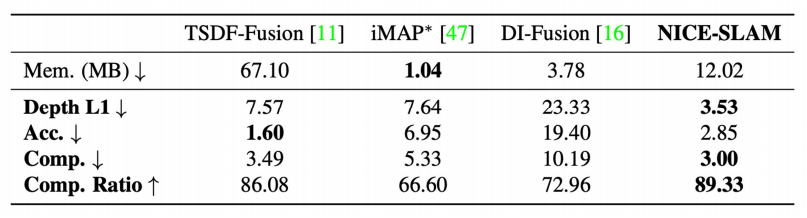
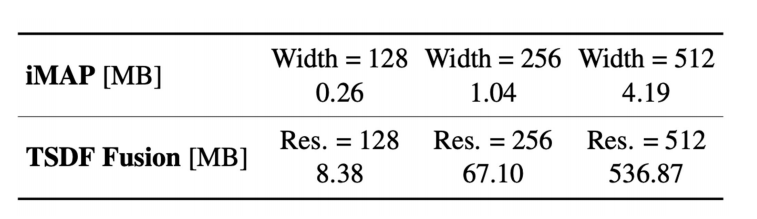
由于NICE-SLAM使用的更偏显示的表达,所以占用的空间比iMAP高。
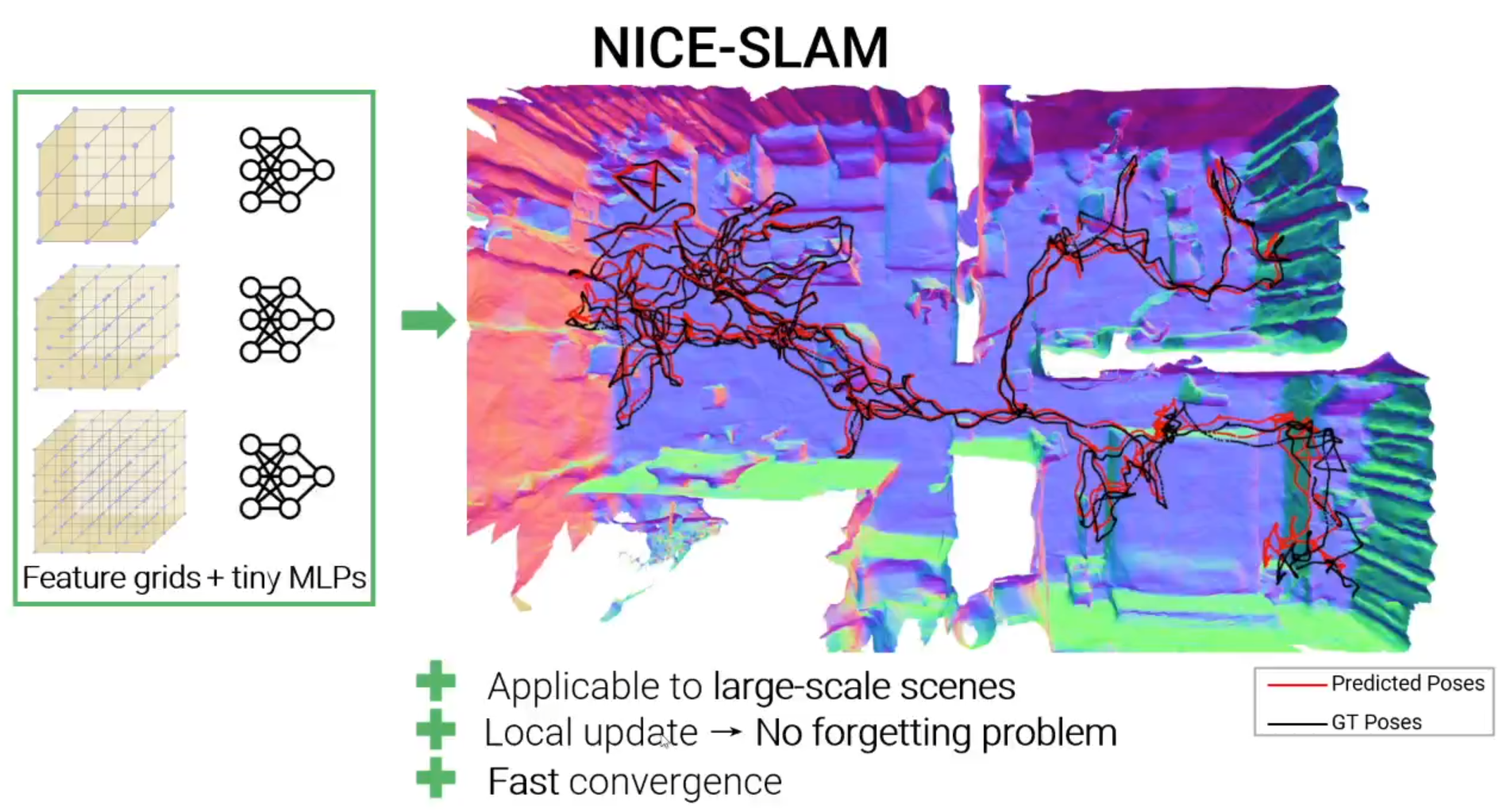
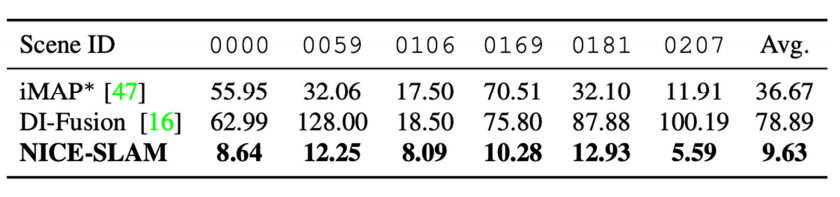
Tracking results on ScanNet

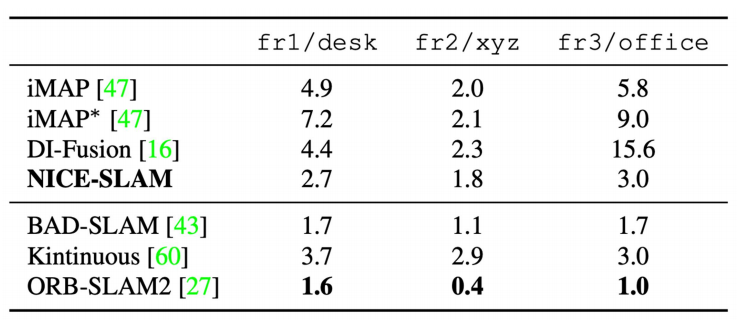
Camera Tracking Results on TUM RGB-D
3D Reconstruction and Tracking on a Multi-room Apartment

Geometry Forecast and Hole Filling

Robustness to Frame Loss

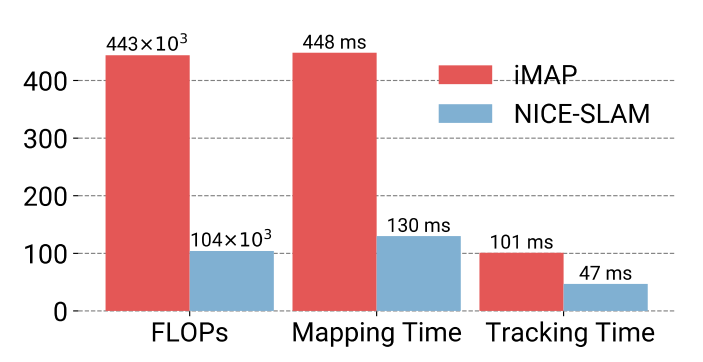
Computation Complexity
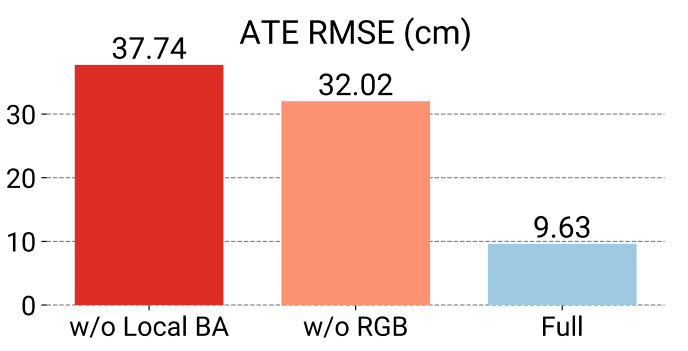
Ablation Study on Tracking
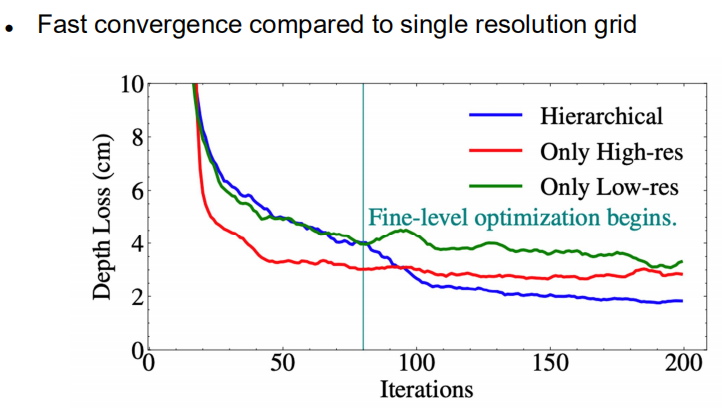
Ablation Study on Hierarchical Architecture
Future Work
- Loop closure
- Global BA
- Adaptively assign voxels
- Extend to outdoor scenes
- Make tracking as accurate as traditional methods
- NICE novel view rendering w/o the need of camera pose



