基于SIFT的图像拼接(融合)实现
要求:
- 给出你用手机拍摄两张有重叠视野的照片(建议两幅图像打光不同,以体现融合的效果)。
- 用sift特征或者任意你熟悉的特征进行匹配。
- 给出变换矩阵,并完成拼接,给出拼接后的图像。
- 对拼接后的图像进行融合,附融合后的图像。
加载图片并进行预处理
第一步肯定是图片的加载和预处理。这里我的想法是:
- 先加载图片,然后调整第一张图片的分辨率,强制宽度为600;
- 之后再调整第二张图片的分辨率,让这两张图片的分辨率一样。
def load_image(img1_path, img2_path):
"""
加载两张图片,并进行预处理
:param img1_path: 图片1的路径
:param img2_path: 图片2的路径
:return: 处理后的图片1与图片2
"""
# ================ 图片加载 ================
img1 = cv.imread(img1_path)
img2 = cv.imread(img2_path)
# ================ 分辨率调整 ================
rate = 600 / img1.shape[1]
img1 = cv.resize(img1, (int(rate * img1.shape[1]), int(rate * img1.shape[0])))
img2 = cv.resize(img2, (img1.shape[1], img1.shape[0]))
# FIXME:
# - 使用边界填充:特征点匹配的结果图带有很大的黑域
# - 不使用边界填充:最后图像拼接和融合不方便,还是需要新建一张更大的图或者提前算好图的大小
# ================ 边界填充 ================
top, bot, left, right = 250, 250, 250, 250
img1 = cv.copyMakeBorder(img1, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0))
img2 = cv.copyMakeBorder(img2, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0))
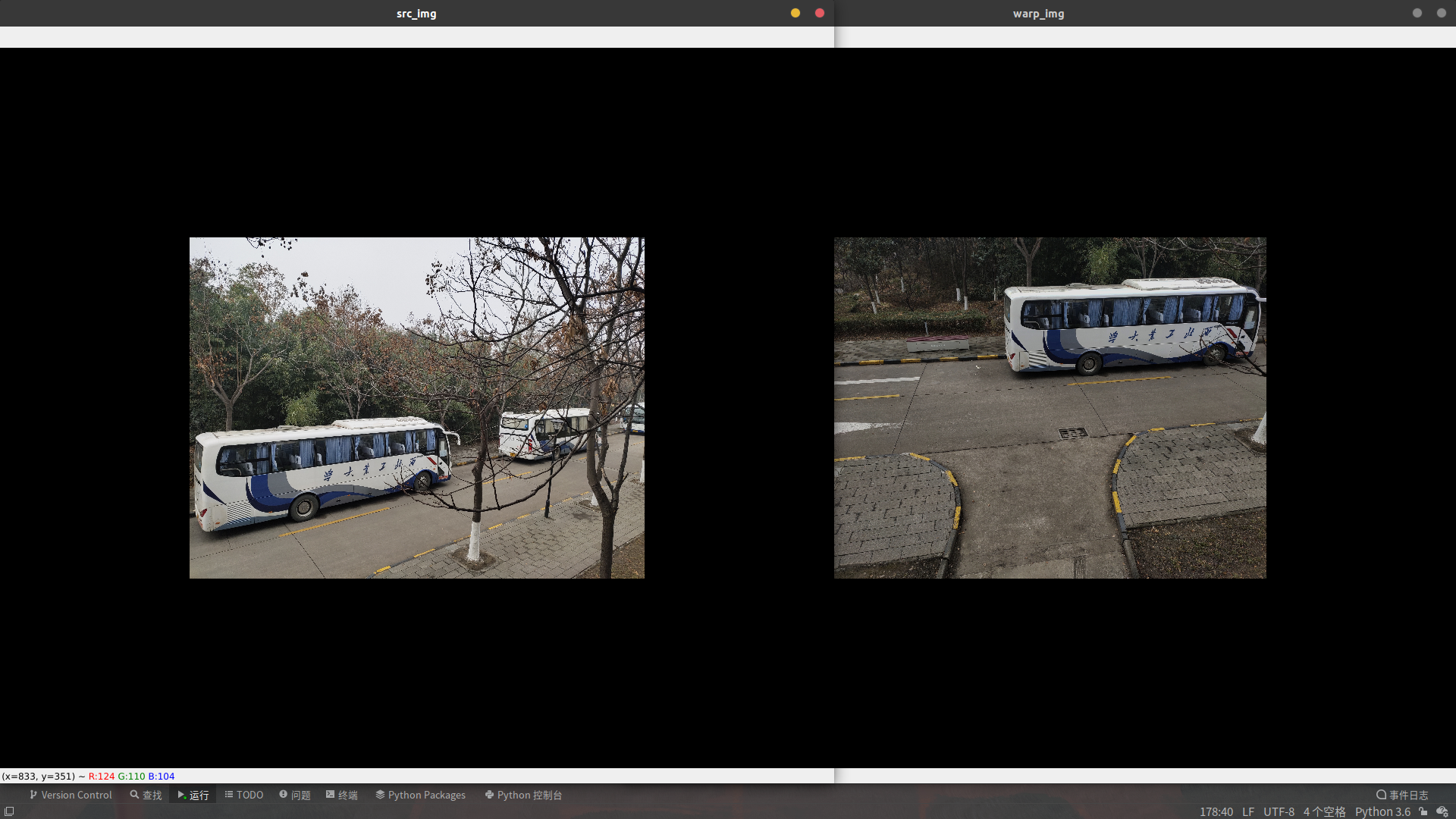
return img1, img2下面是预处理之后的两张图片(第二张图片亮度明显比第一张低)
特征点计算与匹配
得到处理好的两张图片之后,我使用OpenCV的SIFT特征点进行匹配。
def match_feather_point(img1, img2):
"""
计算特征点并进行匹配
:param img1: 第一张图片
:param img2: 第二张图片
:return: 匹配的特征点
"""
# ================ 计算SIFT特征 ================
sift = cv.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# ================ FLANN特征匹配 ================
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
return kp1, kp2, matches计算变换矩阵并完成拼接
这部分的思路:
根据匹配点间的距离选择了一些好的匹配点对;
利用OpenCV的findHomography函数计算得到了变换矩阵(所以这里使用的是投射模型);
根据变换矩阵和OpenCV的warpPerspective函数对第二张图片进行了配准(这里是前向映射);
前向映射就是根据原图用变换公式直接算出输出图像相应像素的空间位置
反向映射(Inverse Mapping):扫描输出图像的位置(x,y),通过 Image (为T的逆矩阵)计算输入图像对应的位置 (v,w),通过插值方法决定输出图像该位置的灰度值。
之后使用拷贝的方法完成了一个非常简单的拼接。
def get_good_match(img1, img2, kp1, kp2, matches):
"""
提取好的匹配点对、计算变换矩阵并拼接图像
:param img1: 第一张图片
:param img2: 第二张图片
:param kp1: 第一张图片特征点
:param kp2: 第二张图片特征点
:param matches: 匹配结果
:return: 第一张图片,配准的第二张图片,匹配结果,拼接图片,变换矩阵
"""
# TODO 使用RANSAC方法去除错误匹配点对
matches_mask = [[0, 0] for _ in range(len(matches))]
good_match = []
for i, (m, n) in enumerate(matches):
if m.distance < 0.5 * n.distance:
good_match.append(m)
matches_mask[i] = [1, 0]
# ================ 画出匹配结果图 ================
draw_params = dict(matchColor=(0, 255, 0),
singlePointColor=(255, 0, 0),
matchesMask=matches_mask,
flags=0)
img3 = cv.drawMatchesKnn(img1, kp1, img2, kp2, matches, None, **draw_params)
# ================ 图像配准,对第二幅图像进行变换 ================
MIN_MATCH_COUNT = 10
if len(good_match) < MIN_MATCH_COUNT:
print("Not enough matches are found - {}/{}".format(len(good_match), MIN_MATCH_COUNT))
return None
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_match]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_match]).reshape(-1, 1, 2)
M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC, 5.0)
img2 = cv.warpPerspective(img2, np.array(M), (img2.shape[1], img2.shape[0]),
flags=cv.WARP_INVERSE_MAP)
# ================ 图像拼接(拷贝拼接,效果不好) ================
dst = img1.copy()
for i in range(img2.shape[0]):
for j in range(img2.shape[1]):
pix = img2[i, j]
if pix.any():
dst[i, j] = pix
return img1, img2, img3, dst, M初始匹配的结果:

去除错误匹配之后的结果:

计算得到的变换矩阵:
变换矩阵:
[[ 2.73415935e-01 4.12585718e-01 2.88797035e+02]
[-2.82455289e-01 1.26241598e+00 -2.13730468e+02]
[-1.02250262e-03 7.60354200e-04 1.00000000e+00]]图片拼接的结果:(拼接痕迹明显)

进行图像融合
这部分的思路:
主要是根据某种权重来进行融合;
这里很自然的想到计算左右重叠的部分,然后根据重叠部分某个点到左右边界的距离来计算权重;
由于上面仅仅是计算左右重叠的部分,所以最后得到的结果可能会有横向拼接痕迹;
我后面尝试了上下左右都考虑进去,但是考虑的方法不是很好,没有取得比较好的效果。
def blend_image(src_img, warp_img):
"""
图像融合
:param src_img: 第一张图片
:param warp_img: 第二张图片
:return: 融合后的图片
"""
# ================ 基本变量定义 ================
rows, cols = src_img.shape[:2]
result = np.zeros([rows, cols, 3], np.uint8)
left = 0
right = 0
up = 0
down = 0
# ================ 找到左右重叠区域 ================
for col in range(0, cols):
if src_img[:, col].any() and warp_img[:, col].any():
left = col
break
for col in range(cols - 1, 0, -1):
if src_img[:, col].any() and warp_img[:, col].any():
right = col
break
# ================ 找到上下重叠区域 ================
# for row in range(0, rows):
# if src_img[row, :].any() and warp_img[row, :].any():
# up = row
# break
# for row in range(rows - 1, 0, -1):
# if src_img[row, :].any() and warp_img[row, :].any():
# down = row
# break
# ================ 根据权重进行图像融合 ================
# FIXME:
# - 根据左右重叠区域进行融合会导致图片中有横向的拼接痕迹
# - 利用上下与左右重叠的区域进行简单融合的效果并不好,需要一些别的办法
for row in range(0, rows):
for col in range(0, cols):
if not src_img[row, col].any(): # src不存在
result[row, col, :] = warp_img[row, col, :]
elif not warp_img[row, col].any(): # warp_img 不存在
result[row, col, :] = src_img[row, col, :]
else: # src 和warp都存在,就是交叉区域
src_len = float(abs(col - left))
test_len = float(abs(col - right))
# src_width = float(abs(row - down))
# test_width = float(abs(row - up))
alpha_1 = src_len / (src_len + test_len)
# alpha_2 = src_width / (src_width + test_width)
result[row, col, :] = src_img[row, col, :] * alpha_1 + \
warp_img[row, col, :] * (1 - alpha_1)
return result最后得到的融合结果:

其他运行结果
测试一



测试二



完整代码
"""
TODO
要求:
1.给出你用手机拍摄两张有重叠视野的照片(建议两幅图像打光不同,以体现第五步融合的效果)。
2.用sift特征或者任意你熟悉的特征进行匹配。(附特征点图)
3.用RANSAC方法去除误匹配点对。(附筛除后的特征点图)
4.给出变换矩阵(仿射模型或投射模型都可以,需注明),并完成拼接(前向映射或反向映射都可以,需注明),给出拼接后的图像。
5.对拼接后的图像进行融合(任意你喜欢的融合方法),附融合后的图像。
注意:
尽量描述清楚每一步的思路,并附上对应代码。
完成任意四步就可以拿到满分(即可以不筛除离群点,或不进行融合)。
网上代码较多,可以参考。
"""
import time
import cv2.cv2 as cv
import numpy as np
# 1.给出你用手机拍摄两张有重叠视野的照片(建议两幅图像打光不同,以体现第五步融合的效果)。
def load_image(img1_path, img2_path):
"""
加载两张图片,并进行预处理
:param img1_path: 图片1的路径
:param img2_path: 图片2的路径
:return: 处理后的图片1与图片2
"""
# ================ 图片加载 ================
img1 = cv.imread(img1_path)
img2 = cv.imread(img2_path)
# ================ 分辨率调整 ================
rate = 600 / img1.shape[1]
img1 = cv.resize(img1, (int(rate * img1.shape[1]), int(rate * img1.shape[0])))
img2 = cv.resize(img2, (img1.shape[1], img1.shape[0]))
# FIXME:
# - 使用边界填充:特征点匹配的结果图带有很大的黑域
# - 不使用边界填充:最后图像拼接和融合不方便,还是需要新建一张更大的图或者提前算好图的大小
# ================ 边界填充 ================
top, bot, left, right = 250, 250, 250, 250
img1 = cv.copyMakeBorder(img1, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0))
img2 = cv.copyMakeBorder(img2, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0))
return img1, img2
# 2.用sift特征或者任意你熟悉的特征进行匹配。(附特征点图)
def match_feather_point(img1, img2):
"""
计算特征点并进行匹配
:param img1: 第一张图片
:param img2: 第二张图片
:return: 匹配的特征点
"""
# ================ 计算SIFT特征 ================
sift = cv.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# ================ FLANN特征匹配 ================
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
return kp1, kp2, matches
# 3.用RANSAC方法去除误匹配点对。(附筛除后的特征点图)
# 4.给出变换矩阵(仿射模型或投射模型都可以,需注明),并且进行图像配准,完成拼接(前向映射或反向映射都可以,需注明),给出拼接后的图像。
def get_good_match(img1, img2, kp1, kp2, matches):
"""
提取好的匹配点对、计算变换矩阵并拼接图像
:param img1: 第一张图片
:param img2: 第二张图片
:param kp1: 第一张图片特征点
:param kp2: 第二张图片特征点
:param matches: 匹配结果
:return: 第一张图片,配准的第二张图片,匹配结果,拼接图片,变换矩阵
"""
# TODO 使用RANSAC方法去除错误匹配点对
matches_mask = [[0, 0] for _ in range(len(matches))]
good_match = []
for i, (m, n) in enumerate(matches):
if m.distance < 0.5 * n.distance:
good_match.append(m)
matches_mask[i] = [1, 0]
# ================ 画出匹配结果图 ================
# # 这是没去除的部分
# draw_params = dict(matchColor=(0, 255, 0),
# singlePointColor=(255, 0, 0),
# matchesMask=None,
# flags=0)
# img3 = cv.drawMatchesKnn(img1, kp1, img2, kp2, matches, None, **draw_params)
# cv.imshow("test", img3)
# 这是去除后的部分
draw_params = dict(matchColor=(0, 255, 0),
singlePointColor=(255, 0, 0),
matchesMask=matches_mask,
flags=0)
img3 = cv.drawMatchesKnn(img1, kp1, img2, kp2, matches, None, **draw_params)
# ================ 图像配准,对第二幅图像进行变换 ================
MIN_MATCH_COUNT = 10
if len(good_match) < MIN_MATCH_COUNT:
print("Not enough matches are found - {}/{}".format(len(good_match), MIN_MATCH_COUNT))
return None
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_match]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_match]).reshape(-1, 1, 2)
M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC, 5.0)
img2 = cv.warpPerspective(img2, np.array(M), (img2.shape[1], img2.shape[0]),
flags=cv.WARP_INVERSE_MAP)
# ================ 图像拼接(拷贝拼接,效果不好) ================
dst = img1.copy()
for i in range(img2.shape[0]):
for j in range(img2.shape[1]):
pix = img2[i, j]
if pix.any():
dst[i, j] = pix
return img1, img2, img3, dst, M
# 5.对拼接后的图像进行融合(任意你喜欢的融合方法),附融合后的图像。
def blend_image(src_img, warp_img):
"""
图像融合
:param src_img: 第一张图片
:param warp_img: 第二张图片
:return: 融合后的图片
"""
# ================ 基本变量定义 ================
rows, cols = src_img.shape[:2]
result = np.zeros([rows, cols, 3], np.uint8)
left = 0
right = 0
up = 0
down = 0
# ================ 找到左右重叠区域 ================
for col in range(0, cols):
if src_img[:, col].any() and warp_img[:, col].any():
left = col
break
for col in range(cols - 1, 0, -1):
if src_img[:, col].any() and warp_img[:, col].any():
right = col
break
# ================ 找到上下重叠区域 ================
# for row in range(0, rows):
# if src_img[row, :].any() and warp_img[row, :].any():
# up = row
# break
# for row in range(rows - 1, 0, -1):
# if src_img[row, :].any() and warp_img[row, :].any():
# down = row
# break
# ================ 根据权重进行图像融合 ================
# FIXME:
# - 根据左右重叠区域进行融合会导致图片中有横向的拼接痕迹
# - 利用上下与左右重叠的区域进行简单融合的效果并不好,需要一些别的办法
for row in range(0, rows):
for col in range(0, cols):
if not src_img[row, col].any(): # src不存在
result[row, col, :] = warp_img[row, col, :]
elif not warp_img[row, col].any(): # warp_img 不存在
result[row, col, :] = src_img[row, col, :]
else: # src 和warp都存在,就是交叉区域
src_len = float(abs(col - left))
test_len = float(abs(col - right))
# src_width = float(abs(row - down))
# test_width = float(abs(row - up))
alpha_1 = src_len / (src_len + test_len)
# alpha_2 = src_width / (src_width + test_width)
result[row, col, :] = src_img[row, col, :] * alpha_1 + \
warp_img[row, col, :] * (1 - alpha_1)
return result
def main_process(path1='./images/testA_1.jpg', path2='./images/testA_2.jpg'):
""""""
# ================ 加载图片 ================
src_img, warp_img = load_image(path1, path2)
# ================ 特征点计算与匹配 ================
start = time.time()
kp1, kp2, matches = match_feather_point(src_img, warp_img)
end = time.time()
print('特征点计算以及匹配的时间:', end - start)
# ================ 去除误匹配点、计算变换矩阵并进行拼接 ================
start = time.time()
img1, img2, img3, dst, M = get_good_match(src_img, warp_img, kp1, kp2, matches)
end = time.time()
print('去除误匹配点、计算变换矩阵并进行拼接的时间:', end - start)
# ================ 图像融合 ================
start = time.time()
res = blend_image(img1, img2)
end = time.time()
print('图像融合时间:', end - start)
# ================ 打印最后的结果 ================
print("变换矩阵", M)
cv.imshow("splicing", dst)
cv.imshow("sift_match", img3)
cv.imshow("blend_result", res)
while True:
if cv.waitKey(0) == 27:
break
if __name__ == "__main__":
path1 = "./images/testD_2.jpg"
path2 = "./images/testX_1.jpg"
main_process(path1, path2)



